Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating lyrics with variational autoencoder and multi-modal artist embeddings
Paper and Code
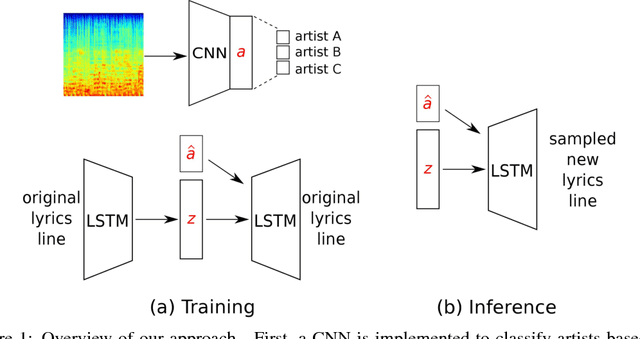
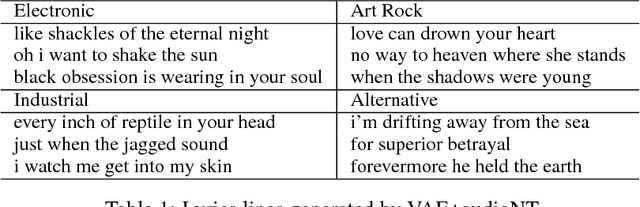
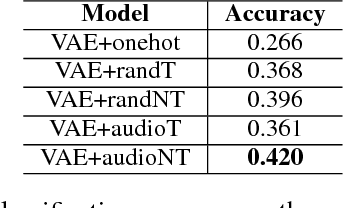
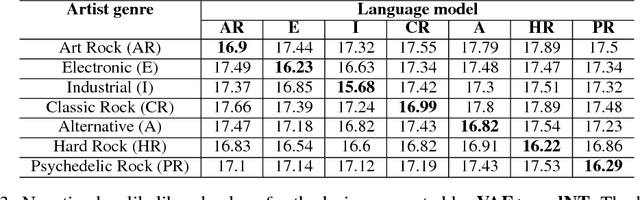
We present a system for generating song lyrics lines conditioned on the style of a specified artist. The system uses a variational autoencoder with artist embeddings. We propose the pre-training of artist embeddings with the representations learned by a CNN classifier, which is trained to predict artists based on MEL spectrograms of their song clips. This work is the first step towards combining audio and text modalities of songs for generating lyrics conditioned on the artist's style. Our preliminary results suggest that there is a benefit in initializing artists' embeddings with the representations learned by a spectrogram classifier.
* 5 pages, 5 tables, 1 figure
View paper on