Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Representation Learning for Non-Parallel Text Style Transfer
Paper and Code
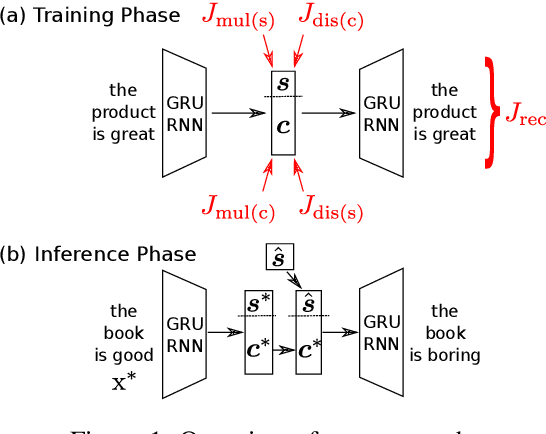
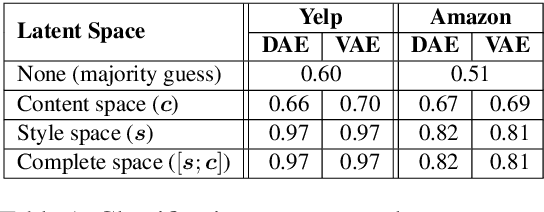
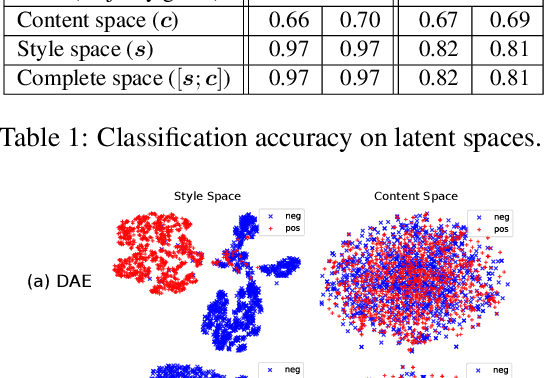
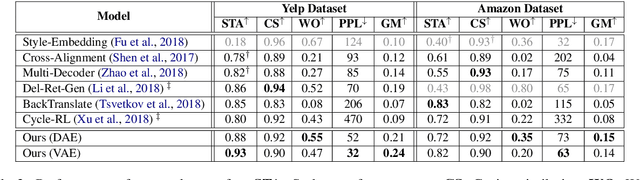
This paper tackles the problem of disentangling the latent variables of style and content in language models. We propose a simple yet effective approach, which incorporates auxiliary multi-task and adversarial objectives, for label prediction and bag-of-words prediction, respectively. We show, both qualitatively and quantitatively, that the style and content are indeed disentangled in the latent space. This disentangled latent representation learning method is applied to style transfer on non-parallel corpora. We achieve substantially better results in terms of transfer accuracy, content preservation and language fluency, in comparison to previous state-of-the-art approaches.
* 11 pages, 7 figures, 6 tables; Preliminary work rejected by EMNLP-18
View paper on