 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Keyphrase Generation with Neural Unlikelihood Training
Paper and Code

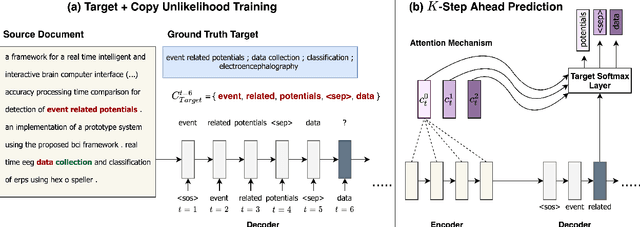

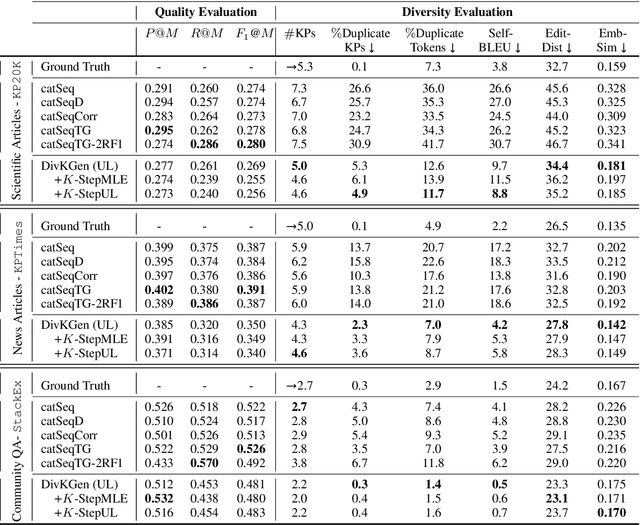
In this paper, we study sequence-to-sequence (S2S) keyphrase generation models from the perspective of diversity. Recent advances in neural natural language generation have made possible remarkable progress on the task of keyphrase generation, demonstrated through improvements on quality metrics such as F1-score. However, the importance of diversity in keyphrase generation has been largely ignored. We first analyze the extent of information redundancy present in the outputs generated by a baseline model trained using maximum likelihood estimation (MLE). Our findings show that repetition of keyphrases is a major issue with MLE training. To alleviate this issue, we adopt neural unlikelihood (UL) objective for training the S2S model. Our version of UL training operates at (1) the target token level to discourage the generation of repeating tokens; (2) the copy token level to avoid copying repetitive tokens from the source text. Further, to encourage better model planning during the decoding process, we incorporate K-step ahead token prediction objective that computes both MLE and UL losses on future tokens as well. Through extensive experiments on datasets from three different domains we demonstrate that the proposed approach attains considerably large diversity gains, while maintaining competitive output quality.