 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Intelligent Scene Augmentation for Context-Aware Object Placement and Sponsor-Logo Integration
Dec 25, 2025Intelligent image editing increasingly relies on advances in computer vision, multimodal reasoning, and generative modeling. While vision-language models (VLMs) and diffusion models enable guided visual manipulation, existing work rarely ensures that inserted objects are \emph{contextually appropriate}. We introduce two new tasks for advertising and digital media: (1) \emph{context-aware object insertion}, which requires predicting suitable object categories, generating them, and placing them plausibly within the scene; and (2) \emph{sponsor-product logo augmentation}, which involves detecting products and inserting correct brand logos, even when items are unbranded or incorrectly branded. To support these tasks, we build two new datasets with category annotations, placement regions, and sponsor-product labels.
FIRE: A Failure-Adaptive Reinforcement Learning Framework for Edge Computing Migrations
Sep 28, 2022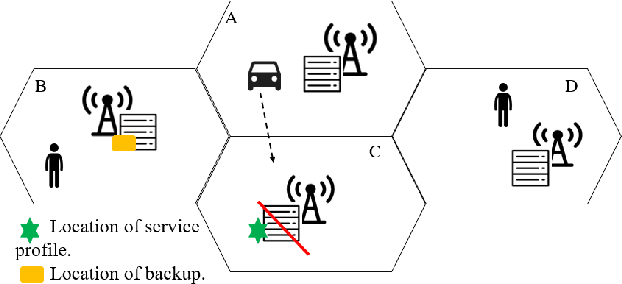
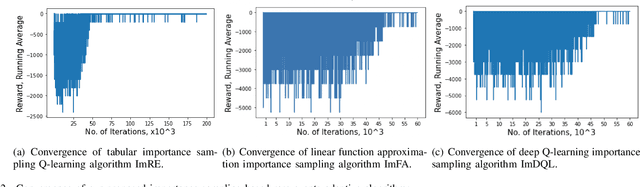
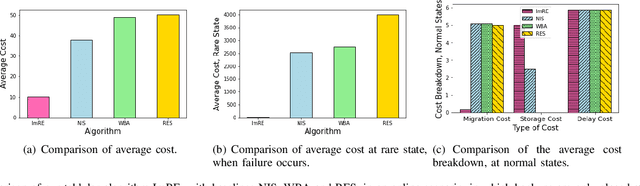
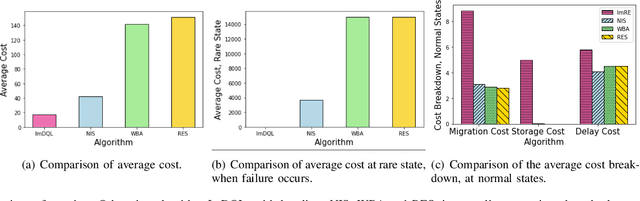
In edge computing, users' service profiles must be migrated in response to user mobility. Reinforcement learning (RL) frameworks have been proposed to do so. Nevertheless, these frameworks do not consider occasional server failures, which although rare, can prevent the smooth and safe functioning of edge computing users' latency sensitive applications such as autonomous driving and real-time obstacle detection, because users' computing jobs can no longer be completed. As these failures occur at a low probability, it is difficult for RL algorithms, which are inherently data-driven, to learn an optimal service migration solution for both the typical and rare event scenarios. Therefore, we introduce a rare events adaptive resilience framework FIRE, which integrates importance sampling into reinforcement learning to place backup services. We sample rare events at a rate proportional to their contribution to the value function, to learn an optimal policy. Our framework balances service migration trade-offs between delay and migration costs, with the costs of failure and the costs of backup placement and migration. We propose an importance sampling based Q-learning algorithm, and prove its boundedness and convergence to optimality. Following which we propose novel eligibility traces, linear function approximation and deep Q-learning versions of our algorithm to ensure it scales to real-world scenarios. We extend our framework to cater to users with different risk tolerances towards failure. Finally, we use trace driven experiments to show that our algorithm gives cost reductions in the event of failures.
MS-nowcasting: Operational Precipitation Nowcasting with Convolutional LSTMs at Microsoft Weather
Nov 18, 2021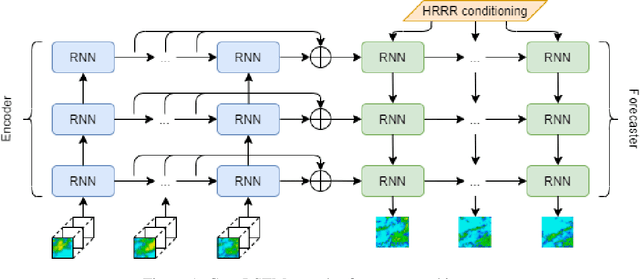
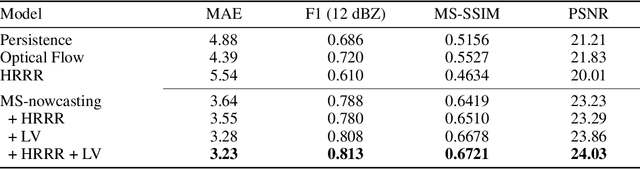
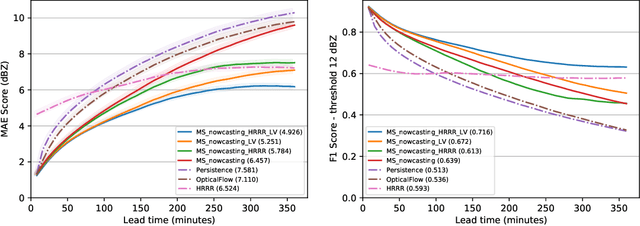
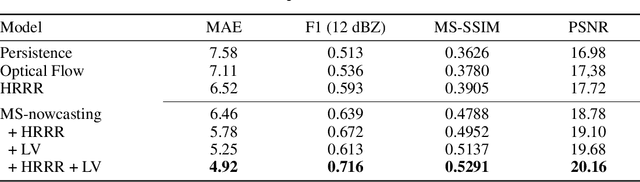
We present the encoder-forecaster convolutional long short-term memory (LSTM) deep-learning model that powers Microsoft Weather's operational precipitation nowcasting product. This model takes as input a sequence of weather radar mosaics and deterministically predicts future radar reflectivity at lead times up to 6 hours. By stacking a large input receptive field along the feature dimension and conditioning the model's forecaster with predictions from the physics-based High Resolution Rapid Refresh (HRRR) model, we are able to outperform optical flow and HRRR baselines by 20-25% on multiple metrics averaged over all lead times.
Object-Centric Image Generation from Layouts
Mar 16, 2020


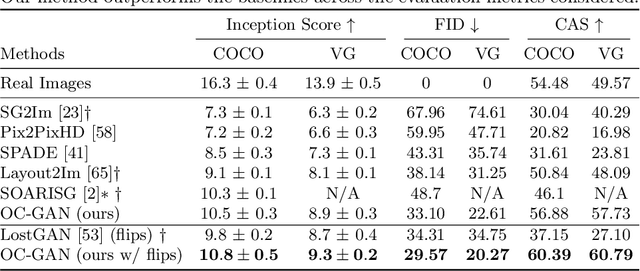
Despite recent impressive results on single-object and single-domain image generation, the generation of complex scenes with multiple objects remains challenging. In this paper, we start with the idea that a model must be able to understand individual objects and relationships between objects in order to generate complex scenes well. Our layout-to-image-generation method, which we call Object-Centric Generative Adversarial Network (or OC-GAN), relies on a novel Scene-Graph Similarity Module (SGSM). The SGSM learns representations of the spatial relationships between objects in the scene, which lead to our model's improved layout-fidelity. We also propose changes to the conditioning mechanism of the generator that enhance its object instance-awareness. Apart from improving image quality, our contributions mitigate two failure modes in previous approaches: (1) spurious objects being generated without corresponding bounding boxes in the layout, and (2) overlapping bounding boxes in the layout leading to merged objects in images. Extensive quantitative evaluation and ablation studies demonstrate the impact of our contributions, with our model outperforming previous state-of-the-art approaches on both the COCO-Stuff and Visual Genome datasets. Finally, we address an important limitation of evaluation metrics used in previous works by introducing SceneFID -- an object-centric adaptation of the popular Fr{\'e}chet Inception Distance metric, that is better suited for multi-object images.
From FiLM to Video: Multi-turn Question Answering with Multi-modal Context
Dec 17, 2018

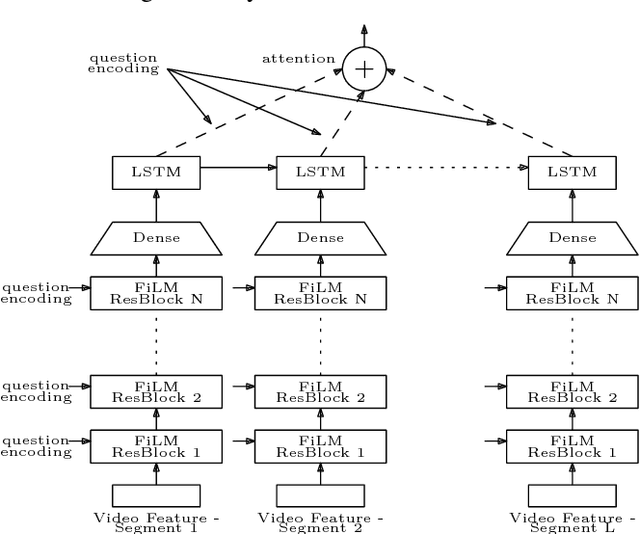
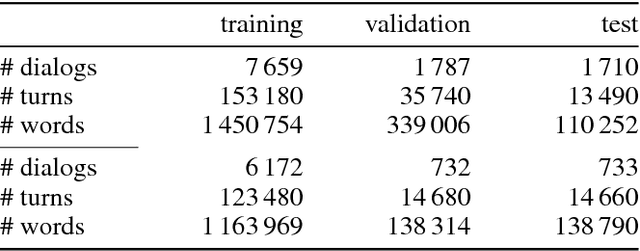
Understanding audio-visual content and the ability to have an informative conversation about it have both been challenging areas for intelligent systems. The Audio Visual Scene-aware Dialog (AVSD) challenge, organized as a track of the Dialog System Technology Challenge 7 (DSTC7), proposes a combined task, where a system has to answer questions pertaining to a video given a dialogue with previous question-answer pairs and the video itself. We propose for this task a hierarchical encoder-decoder model which computes a multi-modal embedding of the dialogue context. It first embeds the dialogue history using two LSTMs. We extract video and audio frames at regular intervals and compute semantic features using pre-trained I3D and VGGish models, respectively. Before summarizing both modalities into fixed-length vectors using LSTMs, we use FiLM blocks to condition them on the embeddings of the current question, which allows us to reduce the dimensionality considerably. Finally, we use an LSTM decoder that we train with scheduled sampling and evaluate using beam search. Compared to the modality-fusing baseline model released by the AVSD challenge organizers, our model achieves a relative improvements of more than 16%, scoring 0.36 BLEU-4 and more than 33%, scoring 0.997 CIDEr.
Keep Drawing It: Iterative language-based image generation and editing
Nov 24, 2018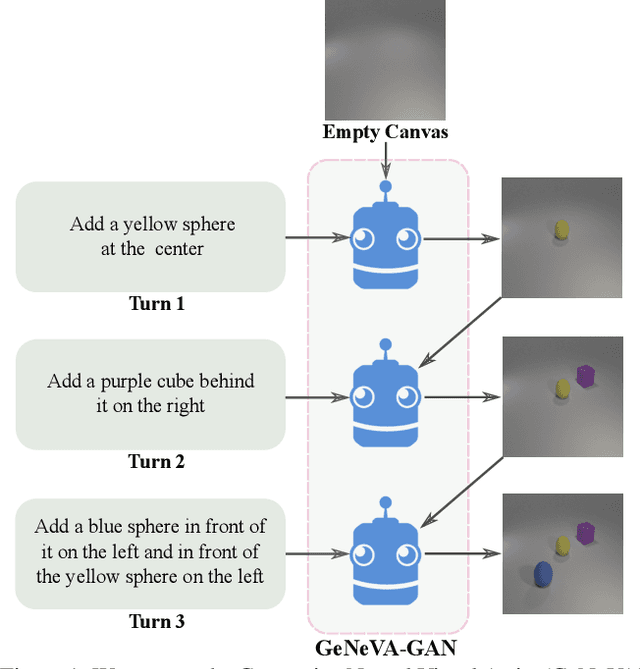


Conditional text-to-image generation approaches commonly focus on generating a single image in a single step. One practical extension beyond one-step generation is an interactive system that generates an image iteratively, conditioned on ongoing linguistic input / feedback. This is significantly more challenging as such a system must understand and keep track of the ongoing context and history. In this work, we present a recurrent image generation model which takes into account both the generated output up to the current step as well as all past instructions for generation. We show that our model is able to generate the background, add new objects, apply simple transformations to existing objects, and correct previous mistakes. We believe our approach is an important step toward interactive generation.
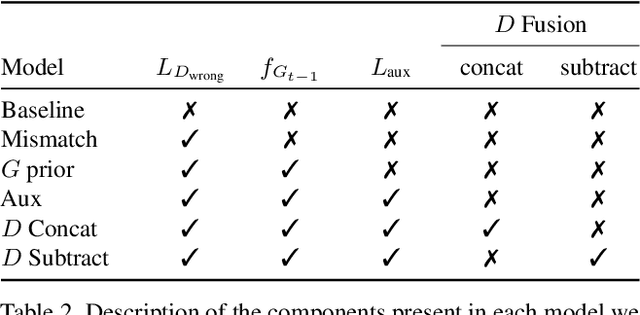
ChatPainter: Improving Text to Image Generation using Dialogue
Feb 22, 2018

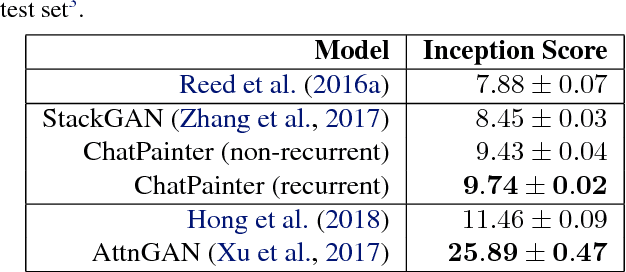
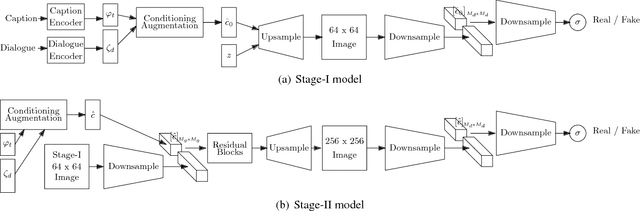
Synthesizing realistic images from text descriptions on a dataset like Microsoft Common Objects in Context (MS COCO), where each image can contain several objects, is a challenging task. Prior work has used text captions to generate images. However, captions might not be informative enough to capture the entire image and insufficient for the model to be able to understand which objects in the images correspond to which words in the captions. We show that adding a dialogue that further describes the scene leads to significant improvement in the inception score and in the quality of generated images on the MS COCO dataset.
Relevance of Unsupervised Metrics in Task-Oriented Dialogue for Evaluating Natural Language Generation
Jun 29, 2017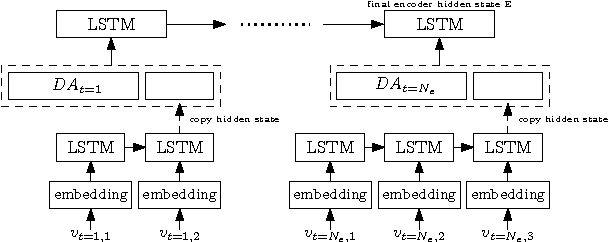

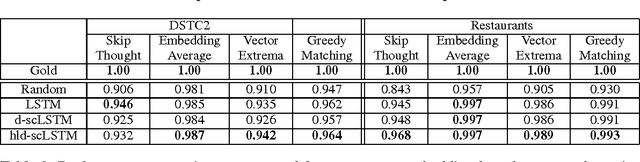
Automated metrics such as BLEU are widely used in the machine translation literature. They have also been used recently in the dialogue community for evaluating dialogue response generation. However, previous work in dialogue response generation has shown that these metrics do not correlate strongly with human judgment in the non task-oriented dialogue setting. Task-oriented dialogue responses are expressed on narrower domains and exhibit lower diversity. It is thus reasonable to think that these automated metrics would correlate well with human judgment in the task-oriented setting where the generation task consists of translating dialogue acts into a sentence. We conduct an empirical study to confirm whether this is the case. Our findings indicate that these automated metrics have stronger correlation with human judgments in the task-oriented setting compared to what has been observed in the non task-oriented setting. We also observe that these metrics correlate even better for datasets which provide multiple ground truth reference sentences. In addition, we show that some of the currently available corpora for task-oriented language generation can be solved with simple models and advocate for more challenging datasets.
A Frame Tracking Model for Memory-Enhanced Dialogue Systems
Jun 06, 2017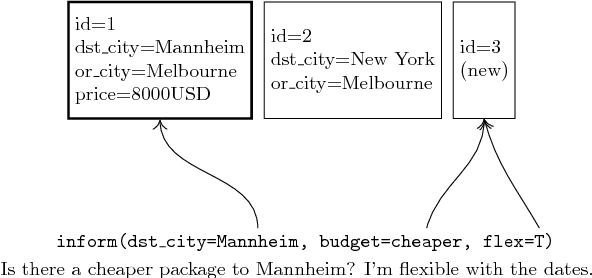

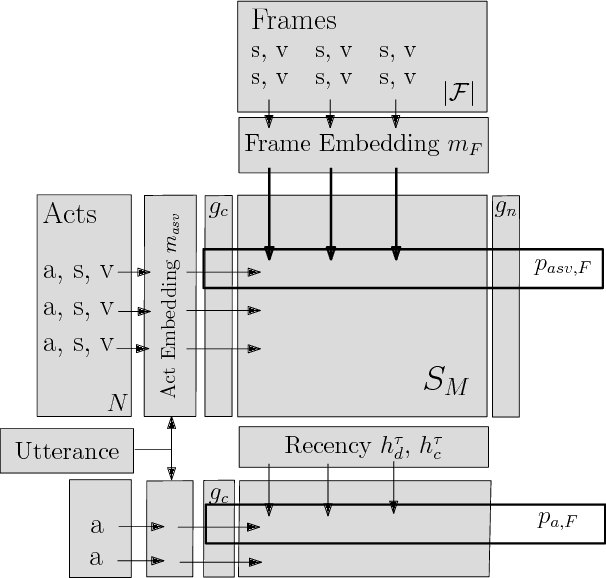

Recently, resources and tasks were proposed to go beyond state tracking in dialogue systems. An example is the frame tracking task, which requires recording multiple frames, one for each user goal set during the dialogue. This allows a user, for instance, to compare items corresponding to different goals. This paper proposes a model which takes as input the list of frames created so far during the dialogue, the current user utterance as well as the dialogue acts, slot types, and slot values associated with this utterance. The model then outputs the frame being referenced by each triple of dialogue act, slot type, and slot value. We show that on the recently published Frames dataset, this model significantly outperforms a previously proposed rule-based baseline. In addition, we propose an extensive analysis of the frame tracking task by dividing it into sub-tasks and assessing their difficulty with respect to our model.
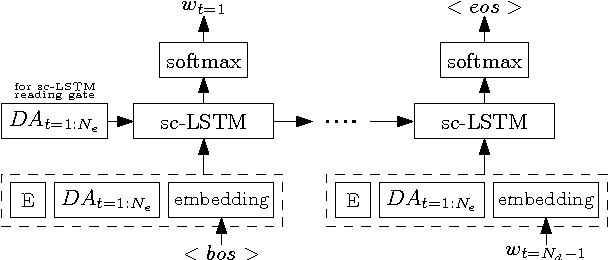
Natural Language Generation in Dialogue using Lexicalized and Delexicalized Data
Apr 21, 2017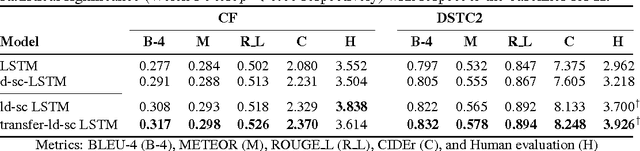
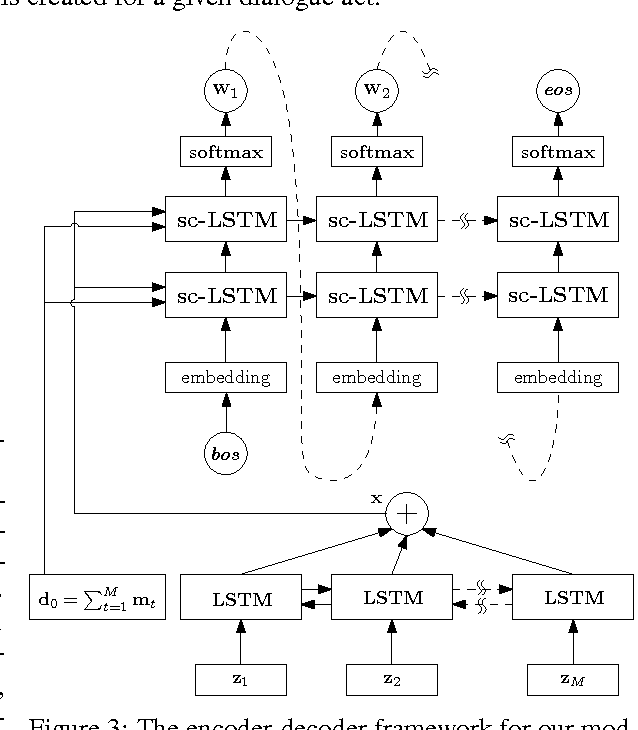
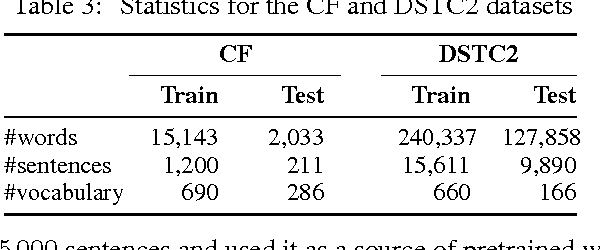
Natural language generation plays a critical role in spoken dialogue systems. We present a new approach to natural language generation for task-oriented dialogue using recurrent neural networks in an encoder-decoder framework. In contrast to previous work, our model uses both lexicalized and delexicalized components i.e. slot-value pairs for dialogue acts, with slots and corresponding values aligned together. This allows our model to learn from all available data including the slot-value pairing, rather than being restricted to delexicalized slots. We show that this helps our model generate more natural sentences with better grammar. We further improve our model's performance by transferring weights learnt from a pretrained sentence auto-encoder. Human evaluation of our best-performing model indicates that it generates sentences which users find more appealing.