 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Centric Image Generation from Layouts
Paper and Code



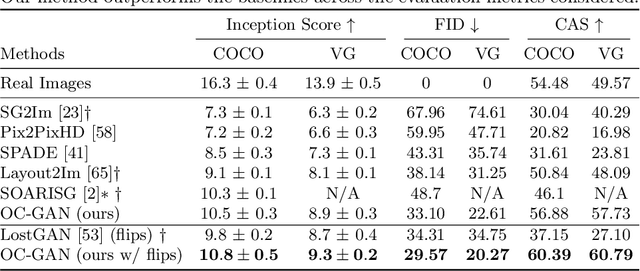
Despite recent impressive results on single-object and single-domain image generation, the generation of complex scenes with multiple objects remains challenging. In this paper, we start with the idea that a model must be able to understand individual objects and relationships between objects in order to generate complex scenes well. Our layout-to-image-generation method, which we call Object-Centric Generative Adversarial Network (or OC-GAN), relies on a novel Scene-Graph Similarity Module (SGSM). The SGSM learns representations of the spatial relationships between objects in the scene, which lead to our model's improved layout-fidelity. We also propose changes to the conditioning mechanism of the generator that enhance its object instance-awareness. Apart from improving image quality, our contributions mitigate two failure modes in previous approaches: (1) spurious objects being generated without corresponding bounding boxes in the layout, and (2) overlapping bounding boxes in the layout leading to merged objects in images. Extensive quantitative evaluation and ablation studies demonstrate the impact of our contributions, with our model outperforming previous state-of-the-art approaches on both the COCO-Stuff and Visual Genome datasets. Finally, we address an important limitation of evaluation metrics used in previous works by introducing SceneFID -- an object-centric adaptation of the popular Fr{\'e}chet Inception Distance metric, that is better suited for multi-object images.