 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual bandits with entropy-based human feedback
Feb 12, 2025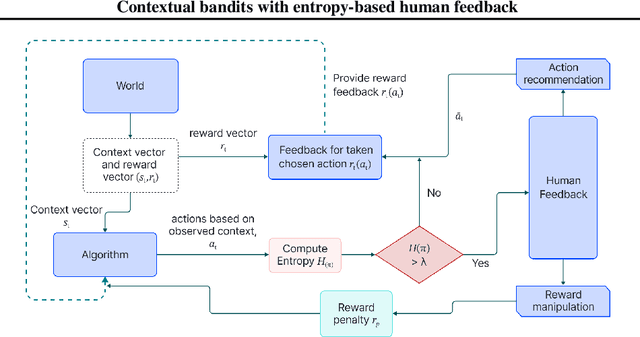
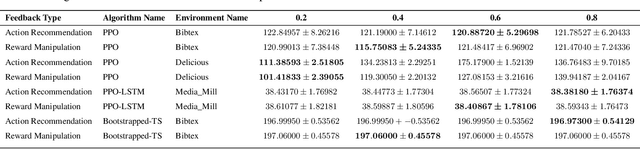
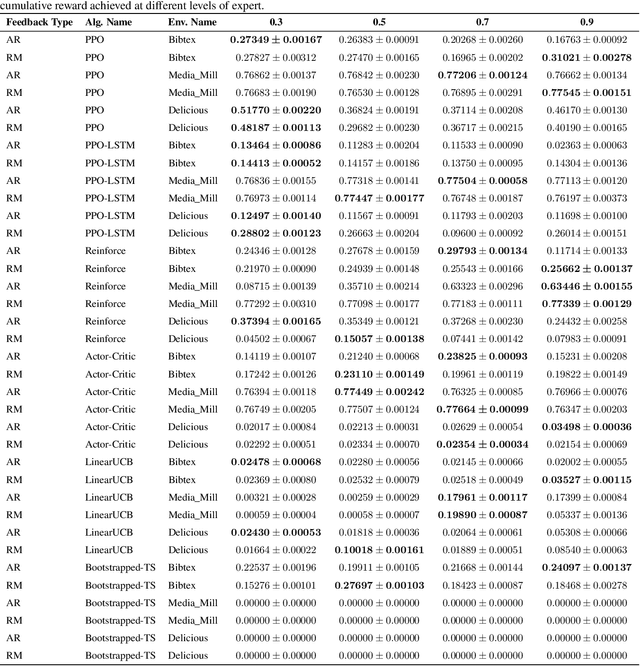
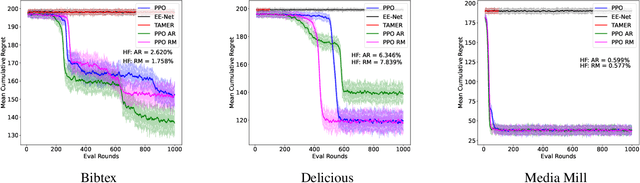
In recent years, preference-based human feedback mechanisms have become essential for enhancing model performance across diverse applications, including conversational AI systems such as ChatGPT. However, existing approaches often neglect critical aspects, such as model uncertainty and the variability in feedback quality. To address these challenges, we introduce an entropy-based human feedback framework for contextual bandits, which dynamically balances exploration and exploitation by soliciting expert feedback only when model entropy exceeds a predefined threshold. Our method is model-agnostic and can be seamlessly integrated with any contextual bandit agent employing stochastic policies. Through comprehensive experiments, we show that our approach achieves significant performance improvements while requiring minimal human feedback, even under conditions of suboptimal feedback quality. This work not only presents a novel strategy for feedback solicitation but also highlights the robustness and efficacy of incorporating human guidance into machine learning systems. Our code is publicly available: https://github.com/BorealisAI/CBHF
LLM-TS Integrator: Integrating LLM for Enhanced Time Series Modeling
Oct 21, 2024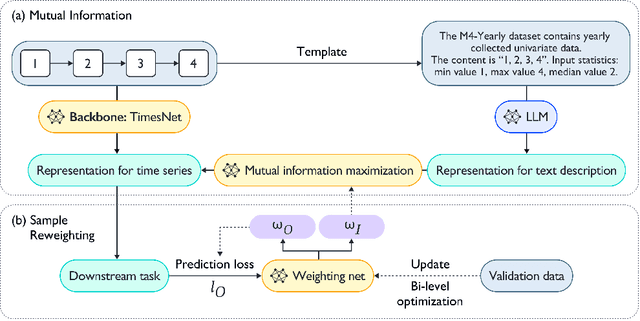

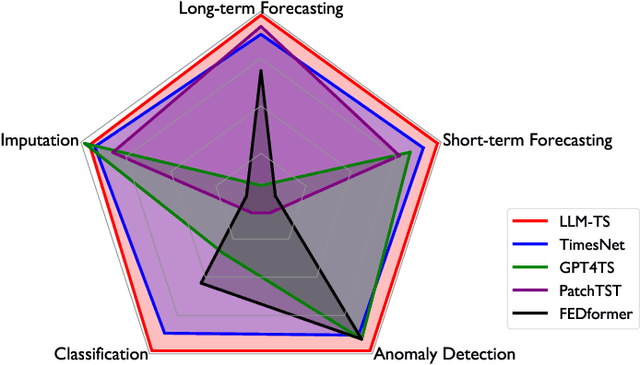
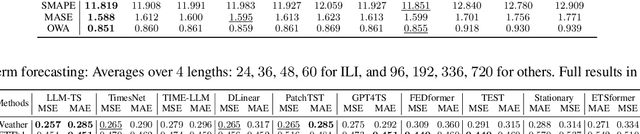
Time series~(TS) modeling is essential in dynamic systems like weather prediction and anomaly detection. Recent studies utilize Large Language Models (LLMs) for TS modeling, leveraging their powerful pattern recognition capabilities. These methods primarily position LLMs as the predictive backbone, often omitting the mathematical modeling within traditional TS models, such as periodicity. However, disregarding the potential of LLMs also overlooks their pattern recognition capabilities. To address this gap, we introduce \textit{LLM-TS Integrator}, a novel framework that effectively integrates the capabilities of LLMs into traditional TS modeling. Central to this integration is our \textit{mutual information} module. The core of this \textit{mutual information} module is a traditional TS model enhanced with LLM-derived insights for improved predictive abilities. This enhancement is achieved by maximizing the mutual information between traditional model's TS representations and LLM's textual representation counterparts, bridging the two modalities. Moreover, we recognize that samples vary in importance for two losses: traditional prediction and mutual information maximization. To address this variability, we introduce the \textit{sample reweighting} module to improve information utilization. This module assigns dual weights to each sample: one for prediction loss and another for mutual information loss, dynamically optimizing these weights via bi-level optimization. Our method achieves state-of-the-art or comparable performance across five mainstream TS tasks, including short-term and long-term forecasting, imputation, classification, and anomaly detection.
Identifying and Addressing Delusions for Target-Directed Decision-Making
Oct 10, 2024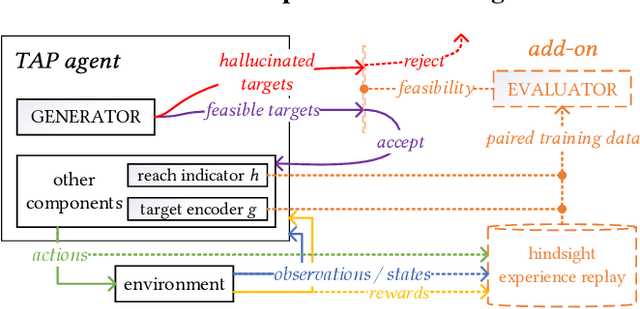

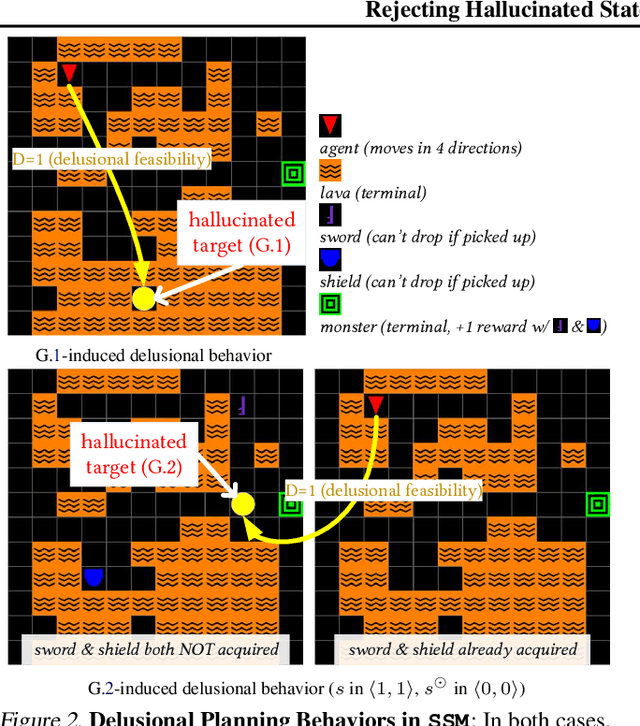
We are interested in target-directed agents, which produce targets during decision-time planning, to guide their behaviors and achieve better generalization during evaluation. Improper training of these agents can result in delusions: the agent may come to hold false beliefs about the targets, which cannot be properly rejected, leading to unwanted behaviors and damaging out-of-distribution generalization. We identify different types of delusions by using intuitive examples in carefully controlled environments, and investigate their causes. We demonstrate how delusions can be addressed for agents trained by hindsight relabeling, a mainstream approach in for training target-directed RL agents. We validate empirically the effectiveness of the proposed solutions in correcting delusional behaviors and improving out-of-distribution generalization.
OPSurv: Orthogonal Polynomials Quadrature Algorithm for Survival Analysis
Feb 02, 2024This paper introduces the Orthogonal Polynomials Quadrature Algorithm for Survival Analysis (OPSurv), a new method providing time-continuous functional outputs for both single and competing risks scenarios in survival analysis. OPSurv utilizes the initial zero condition of the Cumulative Incidence function and a unique decomposition of probability densities using orthogonal polynomials, allowing it to learn functional approximation coefficients for each risk event and construct Cumulative Incidence Function estimates via Gauss--Legendre quadrature. This approach effectively counters overfitting, particularly in competing risks scenarios, enhancing model expressiveness and control. The paper further details empirical validations and theoretical justifications of OPSurv, highlighting its robust performance as an advancement in survival analysis with competing risks.
AutoCast++: Enhancing World Event Prediction with Zero-shot Ranking-based Context Retrieval
Oct 03, 2023



Machine-based prediction of real-world events is garnering attention due to its potential for informed decision-making. Whereas traditional forecasting predominantly hinges on structured data like time-series, recent breakthroughs in language models enable predictions using unstructured text. In particular, (Zou et al., 2022) unveils AutoCast, a new benchmark that employs news articles for answering forecasting queries. Nevertheless, existing methods still trail behind human performance. The cornerstone of accurate forecasting, we argue, lies in identifying a concise, yet rich subset of news snippets from a vast corpus. With this motivation, we introduce AutoCast++, a zero-shot ranking-based context retrieval system, tailored to sift through expansive news document collections for event forecasting. Our approach first re-ranks articles based on zero-shot question-passage relevance, honing in on semantically pertinent news. Following this, the chosen articles are subjected to zero-shot summarization to attain succinct context. Leveraging a pre-trained language model, we conduct both the relevance evaluation and article summarization without needing domain-specific training. Notably, recent articles can sometimes be at odds with preceding ones due to new facts or unanticipated incidents, leading to fluctuating temporal dynamics. To tackle this, our re-ranking mechanism gives preference to more recent articles, and we further regularize the multi-passage representation learning to align with human forecaster responses made on different dates. Empirical results underscore marked improvements across multiple metrics, improving the performance for multiple-choice questions (MCQ) by 48% and true/false (TF) questions by up to 8%.
What Constitutes Good Contrastive Learning in Time-Series Forecasting?
Jun 21, 2023

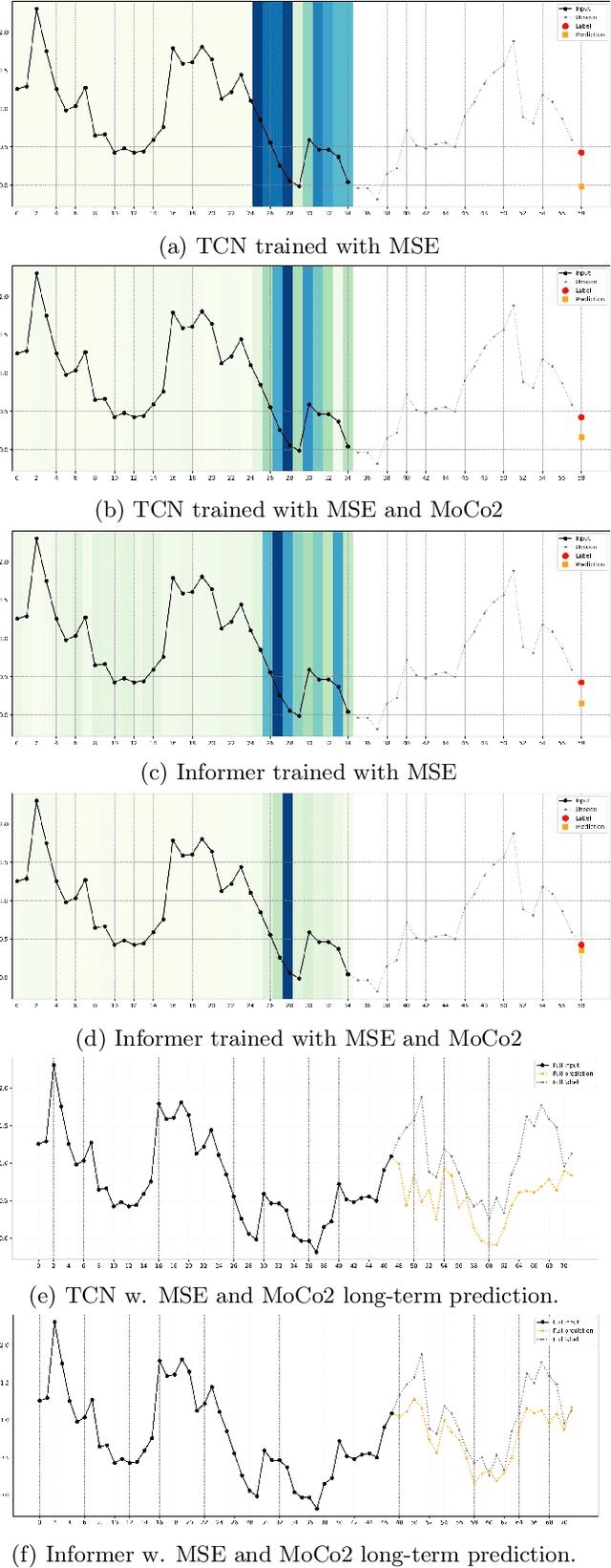
In recent years, the introduction of self-supervised contrastive learning (SSCL) has demonstrated remarkable improvements in representation learning across various domains, including natural language processing and computer vision. By leveraging the inherent benefits of self-supervision, SSCL enables the pre-training of representation models using vast amounts of unlabeled data. Despite these advances, there remains a significant gap in understanding the impact of different SSCL strategies on time series forecasting performance, as well as the specific benefits that SSCL can bring. This paper aims to address these gaps by conducting a comprehensive analysis of the effectiveness of various training variables, including different SSCL algorithms, learning strategies, model architectures, and their interplay. Additionally, to gain deeper insights into the improvements brought about by SSCL in the context of time-series forecasting, a qualitative analysis of the empirical receptive field is performed. Through our experiments, we demonstrate that the end-to-end training of a Transformer model using the Mean Squared Error (MSE) loss and SSCL emerges as the most effective approach in time series forecasting. Notably, the incorporation of the contrastive objective enables the model to prioritize more pertinent information for forecasting, such as scale and periodic relationships. These findings contribute to a better understanding of the benefits of SSCL in time series forecasting and provide valuable insights for future research in this area.
Robust Reinforcement Learning Objectives for Sequential Recommender Systems
May 30, 2023Attention-based sequential recommendation methods have demonstrated promising results by accurately capturing users' dynamic interests from historical interactions. In addition to generating superior user representations, recent studies have begun integrating reinforcement learning (RL) into these models. Framing sequential recommendation as an RL problem with reward signals, unlocks developing recommender systems (RS) that consider a vital aspect-incorporating direct user feedback in the form of rewards to deliver a more personalized experience. Nonetheless, employing RL algorithms presents challenges, including off-policy training, expansive combinatorial action spaces, and the scarcity of datasets with sufficient reward signals. Contemporary approaches have attempted to combine RL and sequential modeling, incorporating contrastive-based objectives and negative sampling strategies for training the RL component. In this study, we further emphasize the efficacy of contrastive-based objectives paired with augmentation to address datasets with extended horizons. Additionally, we recognize the potential instability issues that may arise during the application of negative sampling. These challenges primarily stem from the data imbalance prevalent in real-world datasets, which is a common issue in offline RL contexts. While our established baselines attempt to mitigate this through various techniques, instability remains an issue. Therefore, we introduce an enhanced methodology aimed at providing a more effective solution to these challenges.
Self-supervised multimodal neuroimaging yields predictive representations for a spectrum of Alzheimer's phenotypes
Sep 07, 2022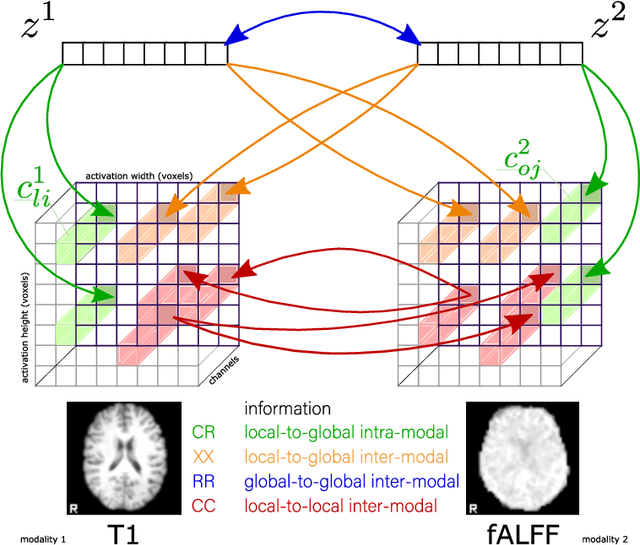

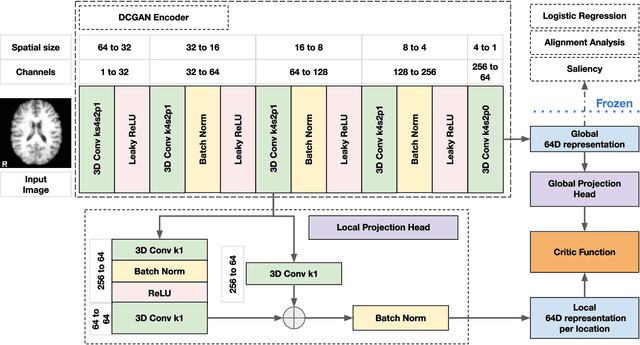
Recent neuroimaging studies that focus on predicting brain disorders via modern machine learning approaches commonly include a single modality and rely on supervised over-parameterized models.However, a single modality provides only a limited view of the highly complex brain. Critically, supervised models in clinical settings lack accurate diagnostic labels for training. Coarse labels do not capture the long-tailed spectrum of brain disorder phenotypes, which leads to a loss of generalizability of the model that makes them less useful in diagnostic settings. This work presents a novel multi-scale coordinated framework for learning multiple representations from multimodal neuroimaging data. We propose a general taxonomy of informative inductive biases to capture unique and joint information in multimodal self-supervised fusion. The taxonomy forms a family of decoder-free models with reduced computational complexity and a propensity to capture multi-scale relationships between local and global representations of the multimodal inputs. We conduct a comprehensive evaluation of the taxonomy using functional and structural magnetic resonance imaging (MRI) data across a spectrum of Alzheimer's disease phenotypes and show that self-supervised models reveal disorder-relevant brain regions and multimodal links without access to the labels during pre-training. The proposed multimodal self-supervised learning yields representations with improved classification performance for both modalities. The concomitant rich and flexible unsupervised deep learning framework captures complex multimodal relationships and provides predictive performance that meets or exceeds that of a more narrow supervised classification analysis. We present elaborate quantitative evidence of how this framework can significantly advance our search for missing links in complex brain disorders.
Scaleformer: Iterative Multi-scale Refining Transformers for Time Series Forecasting
Jun 08, 2022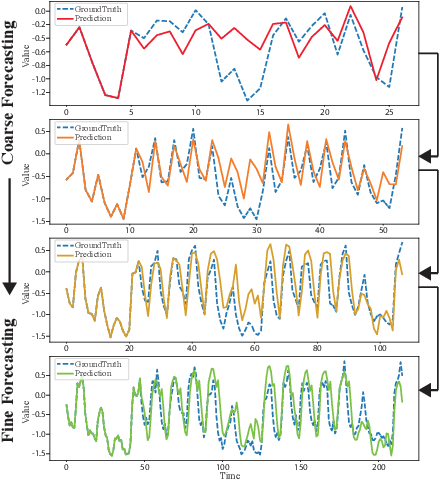
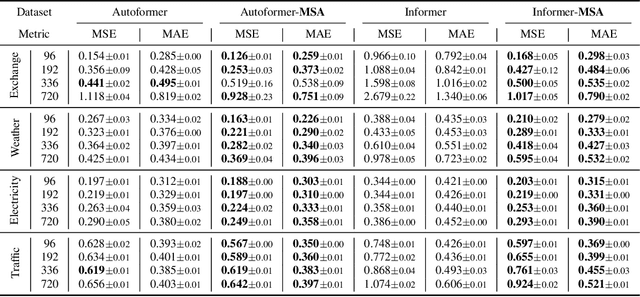
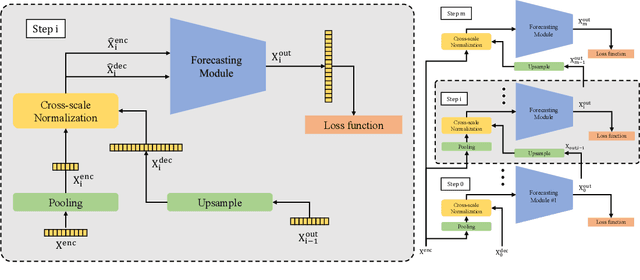
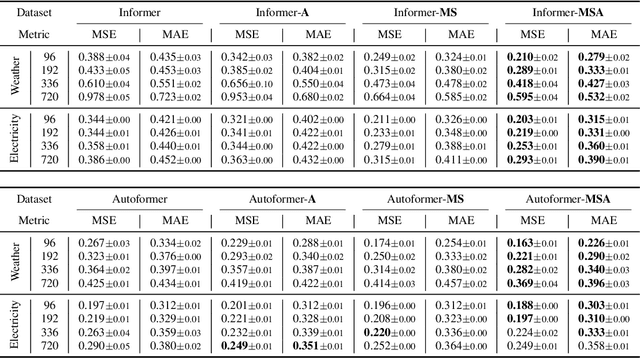
The performance of time series forecasting has recently been greatly improved by the introduction of transformers. In this paper, we propose a general multi-scale framework that can be applied to state-of-the-art transformer-based time series forecasting models including Autoformer and Informer. Using iteratively refining a forecasted time series at multiple scales with shared weights, architecture adaptations and a specially-designed normalization scheme, we are able to achieve significant performance improvements with minimal additional computational overhead. Via detailed ablation studies, we demonstrate the effectiveness of our proposed architectural and methodological innovations. Furthermore, our experiments on four public datasets show that the proposed multi-scale framework outperforms the corresponding baselines with an average improvement of 13% and 38% over Autoformer and Informer, respectively.
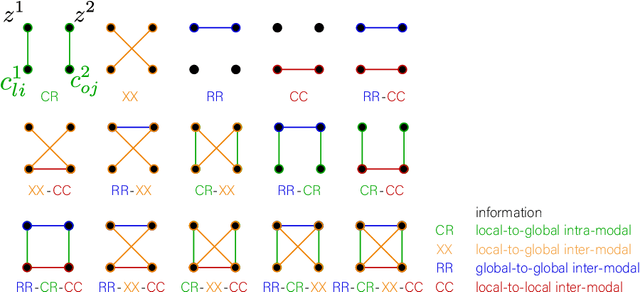
Taxonomy of multimodal self-supervised representation learning
Dec 29, 2020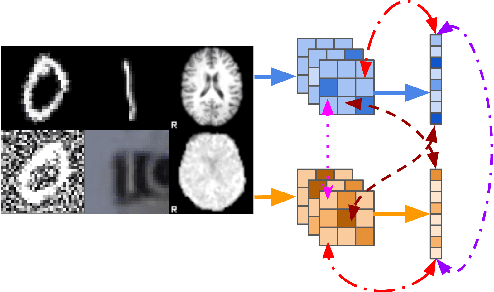
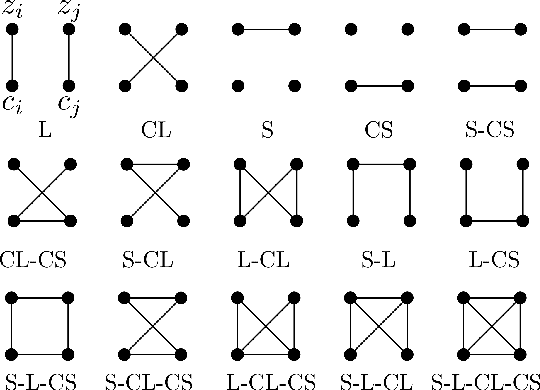
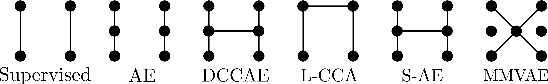
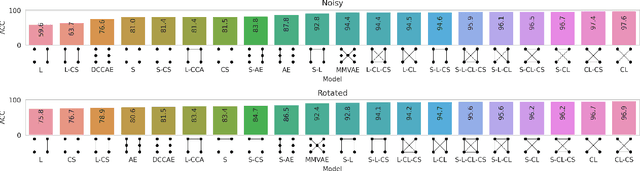
Sensory input from multiple sources is crucial for robust and coherent human perception. Different sources contribute complementary explanatory factors and get combined based on factors they share. This system motivated the design of powerful unsupervised representation-learning algorithms. In this paper, we unify recent work on multimodal self-supervised learning under a single framework. Observing that most self-supervised methods optimize similarity metrics between a set of model components, we propose a taxonomy of all reasonable ways to organize this process. We empirically show on two versions of multimodal MNIST and a multimodal brain imaging dataset that (1) multimodal contrastive learning has significant benefits over its unimodal counterpart, (2) the specific composition of multiple contrastive objectives is critical to performance on a downstream task, (3) maximization of the similarity between representations has a regularizing effect on a neural network, which sometimes can lead to reduced downstream performance but still can reveal multimodal relations. Consequently, we outperform previous unsupervised encoder-decoder methods based on CCA or variational mixtures MMVAE on various datasets on linear evaluation protocol.