 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaceLens: A Machine Intelligence-Based Application for Racing Photo Analysis
Oct 20, 2023


This paper presents RaceLens, a novel application utilizing advanced deep learning and computer vision models for comprehensive analysis of racing photos. The developed models have demonstrated their efficiency in a wide array of tasks, including detecting racing cars, recognizing car numbers, detecting and quantifying car details, and recognizing car orientations. We discuss the process of collecting a robust dataset necessary for training our models, and describe an approach we have designed to augment and improve this dataset continually. Our method leverages a feedback loop for continuous model improvement, thus enhancing the performance and accuracy of RaceLens over time. A significant part of our study is dedicated to illustrating the practical application of RaceLens, focusing on its successful deployment by NASCAR teams over four seasons. We provide a comprehensive evaluation of our system's performance and its direct impact on the team's strategic decisions and performance metrics. The results underscore the transformative potential of machine intelligence in the competitive and dynamic world of car racing, setting a precedent for future applications.
Taxonomy of multimodal self-supervised representation learning
Dec 29, 2020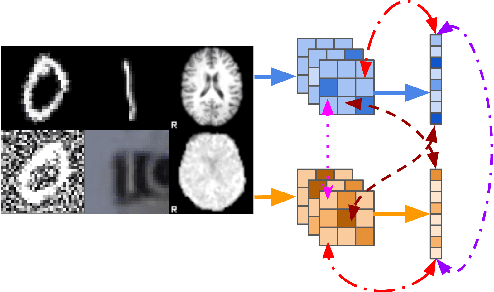
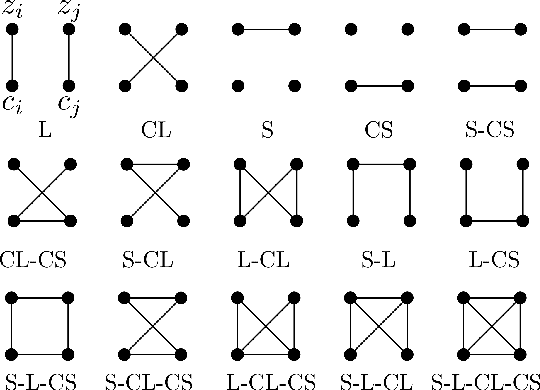
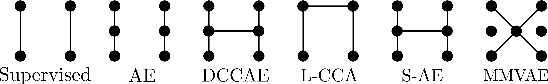
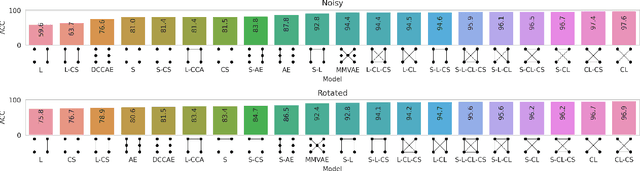
Sensory input from multiple sources is crucial for robust and coherent human perception. Different sources contribute complementary explanatory factors and get combined based on factors they share. This system motivated the design of powerful unsupervised representation-learning algorithms. In this paper, we unify recent work on multimodal self-supervised learning under a single framework. Observing that most self-supervised methods optimize similarity metrics between a set of model components, we propose a taxonomy of all reasonable ways to organize this process. We empirically show on two versions of multimodal MNIST and a multimodal brain imaging dataset that (1) multimodal contrastive learning has significant benefits over its unimodal counterpart, (2) the specific composition of multiple contrastive objectives is critical to performance on a downstream task, (3) maximization of the similarity between representations has a regularizing effect on a neural network, which sometimes can lead to reduced downstream performance but still can reveal multimodal relations. Consequently, we outperform previous unsupervised encoder-decoder methods based on CCA or variational mixtures MMVAE on various datasets on linear evaluation protocol.
On self-supervised multi-modal representation learning: An application to Alzheimer's disease
Dec 25, 2020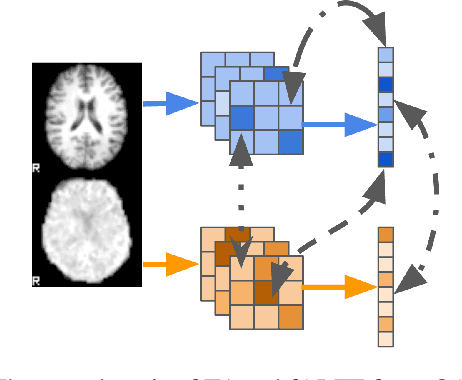
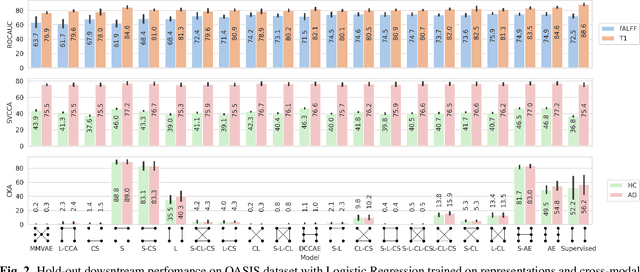
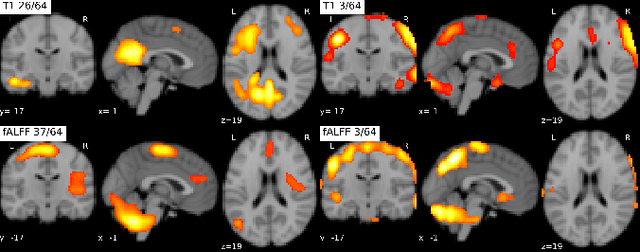
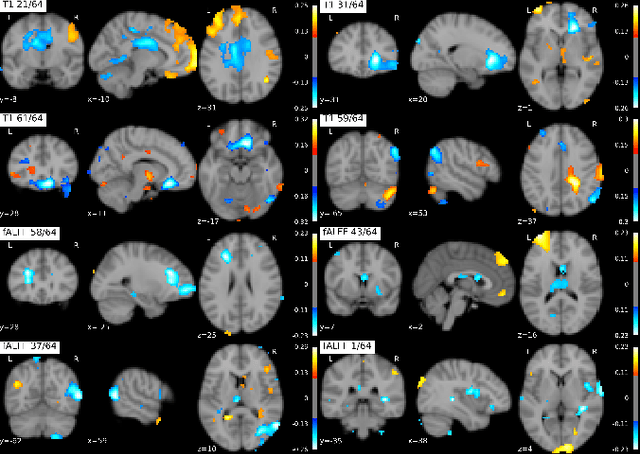
Introspection of deep supervised predictive models trained on functional and structural brain imaging may uncover novel markers of Alzheimer's disease (AD). However, supervised training is prone to learning from spurious features (shortcut learning) impairing its value in the discovery process. Deep unsupervised and, recently, contrastive self-supervised approaches, not biased to classification, are better candidates for the task. Their multimodal options specifically offer additional regularization via modality interactions. In this paper, we introduce a way to exhaustively consider multimodal architectures for contrastive self-supervised fusion of fMRI and MRI of AD patients and controls. We show that this multimodal fusion results in representations that improve the results of the downstream classification for both modalities. We investigate the fused self-supervised features projected into the brain space and introduce a numerically stable way to do so.