 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised multimodal neuroimaging yields predictive representations for a spectrum of Alzheimer's phenotypes
Sep 07, 2022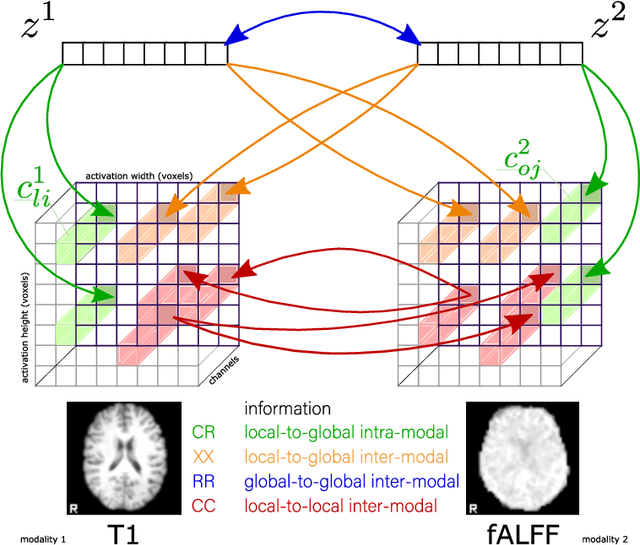

Recent neuroimaging studies that focus on predicting brain disorders via modern machine learning approaches commonly include a single modality and rely on supervised over-parameterized models.However, a single modality provides only a limited view of the highly complex brain. Critically, supervised models in clinical settings lack accurate diagnostic labels for training. Coarse labels do not capture the long-tailed spectrum of brain disorder phenotypes, which leads to a loss of generalizability of the model that makes them less useful in diagnostic settings. This work presents a novel multi-scale coordinated framework for learning multiple representations from multimodal neuroimaging data. We propose a general taxonomy of informative inductive biases to capture unique and joint information in multimodal self-supervised fusion. The taxonomy forms a family of decoder-free models with reduced computational complexity and a propensity to capture multi-scale relationships between local and global representations of the multimodal inputs. We conduct a comprehensive evaluation of the taxonomy using functional and structural magnetic resonance imaging (MRI) data across a spectrum of Alzheimer's disease phenotypes and show that self-supervised models reveal disorder-relevant brain regions and multimodal links without access to the labels during pre-training. The proposed multimodal self-supervised learning yields representations with improved classification performance for both modalities. The concomitant rich and flexible unsupervised deep learning framework captures complex multimodal relationships and provides predictive performance that meets or exceeds that of a more narrow supervised classification analysis. We present elaborate quantitative evidence of how this framework can significantly advance our search for missing links in complex brain disorders.
Tasting the cake: evaluating self-supervised generalization on out-of-distribution multimodal MRI data
Apr 20, 2021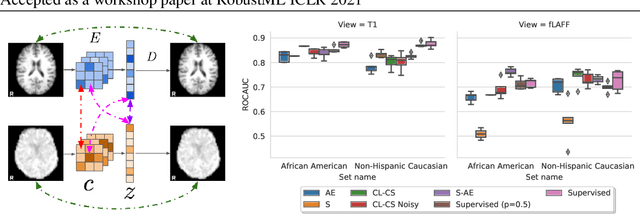
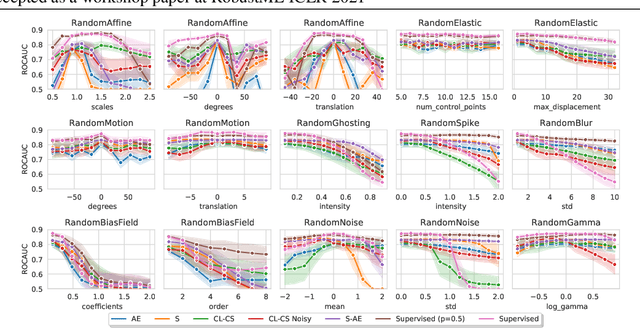
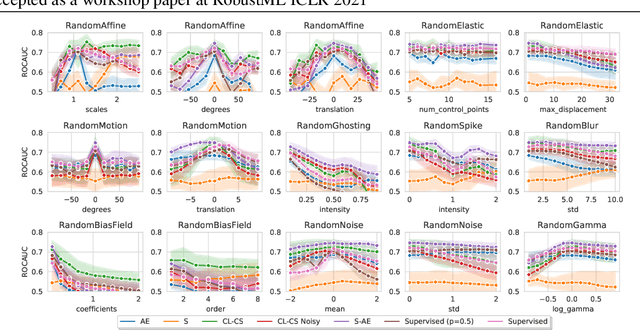

Self-supervised learning has enabled significant improvements on natural image benchmarks. However, there is less work in the medical imaging domain in this area. The optimal models have not yet been determined among the various options. Moreover, little work has evaluated the current applicability limits of novel self-supervised methods. In this paper, we evaluate a range of current contrastive self-supervised methods on out-of-distribution generalization in order to evaluate their applicability to medical imaging. We show that self-supervised models are not as robust as expected based on their results in natural imaging benchmarks and can be outperformed by supervised learning with dropout. We also show that this behavior can be countered with extensive augmentation. Our results highlight the need for out-of-distribution generalization standards and benchmarks to adopt the self-supervised methods in the medical imaging community.
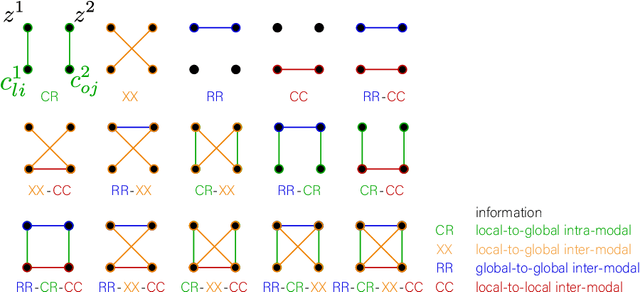
Taxonomy of multimodal self-supervised representation learning
Dec 29, 2020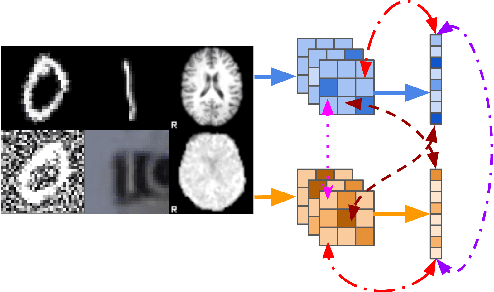
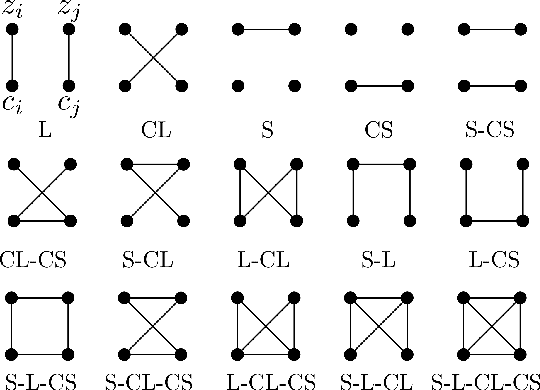
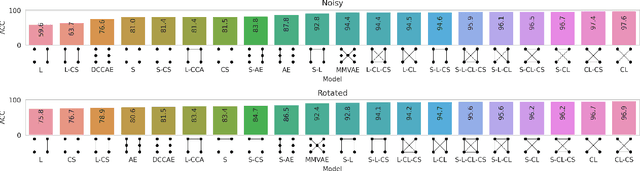
Sensory input from multiple sources is crucial for robust and coherent human perception. Different sources contribute complementary explanatory factors and get combined based on factors they share. This system motivated the design of powerful unsupervised representation-learning algorithms. In this paper, we unify recent work on multimodal self-supervised learning under a single framework. Observing that most self-supervised methods optimize similarity metrics between a set of model components, we propose a taxonomy of all reasonable ways to organize this process. We empirically show on two versions of multimodal MNIST and a multimodal brain imaging dataset that (1) multimodal contrastive learning has significant benefits over its unimodal counterpart, (2) the specific composition of multiple contrastive objectives is critical to performance on a downstream task, (3) maximization of the similarity between representations has a regularizing effect on a neural network, which sometimes can lead to reduced downstream performance but still can reveal multimodal relations. Consequently, we outperform previous unsupervised encoder-decoder methods based on CCA or variational mixtures MMVAE on various datasets on linear evaluation protocol.
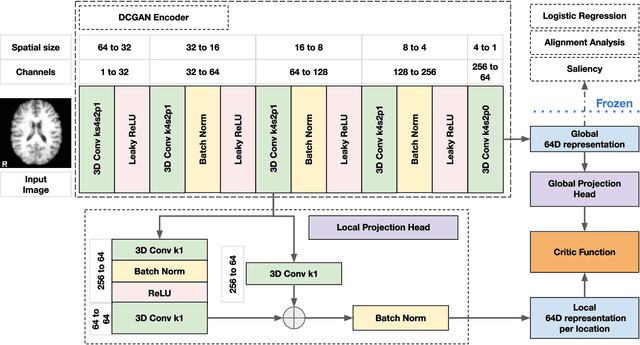
On self-supervised multi-modal representation learning: An application to Alzheimer's disease
Dec 25, 2020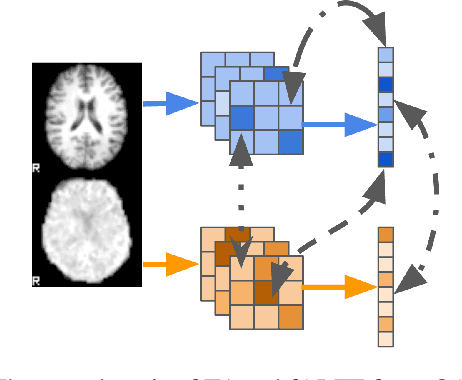
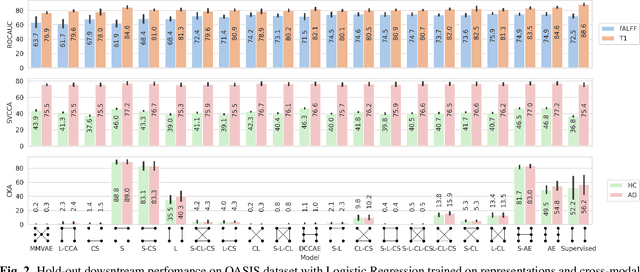
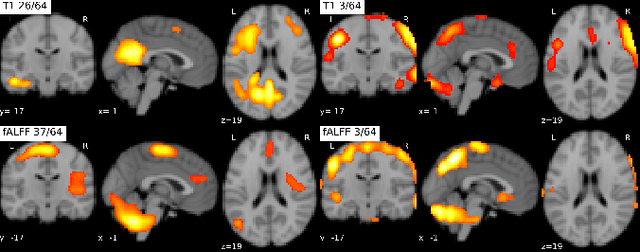
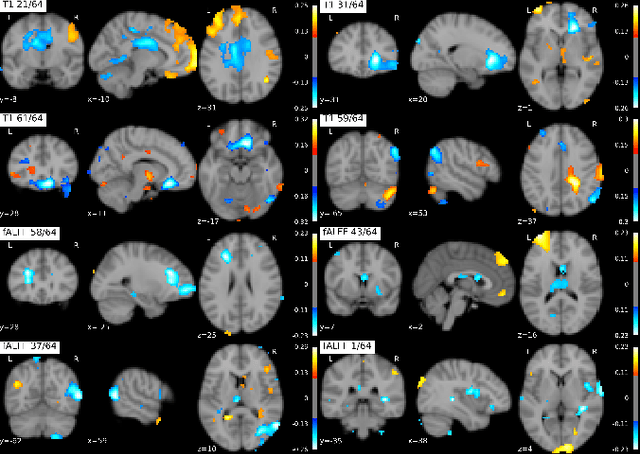
Introspection of deep supervised predictive models trained on functional and structural brain imaging may uncover novel markers of Alzheimer's disease (AD). However, supervised training is prone to learning from spurious features (shortcut learning) impairing its value in the discovery process. Deep unsupervised and, recently, contrastive self-supervised approaches, not biased to classification, are better candidates for the task. Their multimodal options specifically offer additional regularization via modality interactions. In this paper, we introduce a way to exhaustively consider multimodal architectures for contrastive self-supervised fusion of fMRI and MRI of AD patients and controls. We show that this multimodal fusion results in representations that improve the results of the downstream classification for both modalities. We investigate the fused self-supervised features projected into the brain space and introduce a numerically stable way to do so.