 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Broadcast to Minimap: Achieving State-of-the-Art SoccerNet Game State Reconstruction
Apr 08, 2025



Game State Reconstruction (GSR), a critical task in Sports Video Understanding, involves precise tracking and localization of all individuals on the football field-players, goalkeepers, referees, and others - in real-world coordinates. This capability enables coaches and analysts to derive actionable insights into player movements, team formations, and game dynamics, ultimately optimizing training strategies and enhancing competitive advantage. Achieving accurate GSR using a single-camera setup is highly challenging due to frequent camera movements, occlusions, and dynamic scene content. In this work, we present a robust end-to-end pipeline for tracking players across an entire match using a single-camera setup. Our solution integrates a fine-tuned YOLOv5m for object detection, a SegFormer-based camera parameter estimator, and a DeepSORT-based tracking framework enhanced with re-identification, orientation prediction, and jersey number recognition. By ensuring both spatial accuracy and temporal consistency, our method delivers state-of-the-art game state reconstruction, securing first place in the SoccerNet Game State Reconstruction Challenge 2024 and significantly outperforming competing methods.
Streaming Generation of Co-Speech Gestures via Accelerated Rolling Diffusion
Mar 13, 2025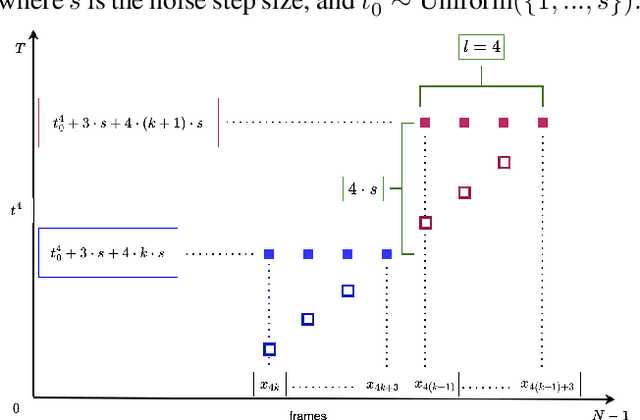


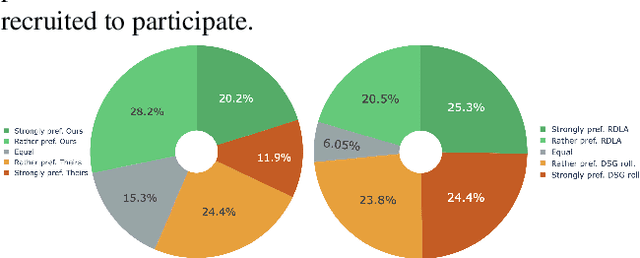
Generating co-speech gestures in real time requires both temporal coherence and efficient sampling. We introduce Accelerated Rolling Diffusion, a novel framework for streaming gesture generation that extends rolling diffusion models with structured progressive noise scheduling, enabling seamless long-sequence motion synthesis while preserving realism and diversity. We further propose Rolling Diffusion Ladder Acceleration (RDLA), a new approach that restructures the noise schedule into a stepwise ladder, allowing multiple frames to be denoised simultaneously. This significantly improves sampling efficiency while maintaining motion consistency, achieving up to a 2x speedup with high visual fidelity and temporal coherence. We evaluate our approach on ZEGGS and BEAT, strong benchmarks for real-world applicability. Our framework is universally applicable to any diffusion-based gesture generation model, transforming it into a streaming approach. Applied to three state-of-the-art methods, it consistently outperforms them, demonstrating its effectiveness as a generalizable and efficient solution for real-time, high-fidelity co-speech gesture synthesis.
SoccerNet 2024 Challenges Results
Sep 16, 2024

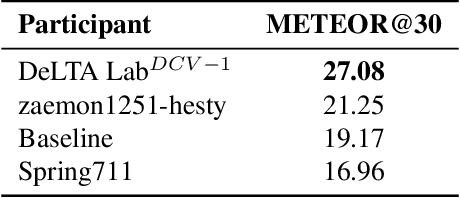
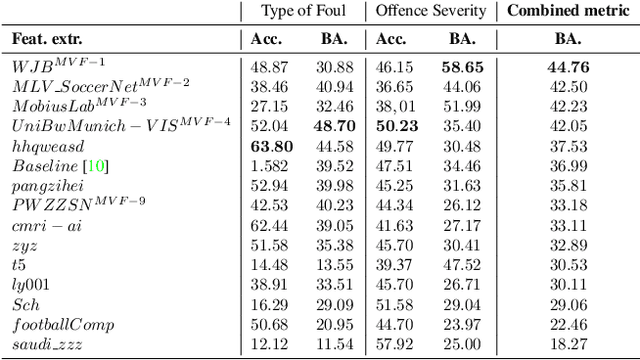
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
RaceLens: A Machine Intelligence-Based Application for Racing Photo Analysis
Oct 20, 2023


This paper presents RaceLens, a novel application utilizing advanced deep learning and computer vision models for comprehensive analysis of racing photos. The developed models have demonstrated their efficiency in a wide array of tasks, including detecting racing cars, recognizing car numbers, detecting and quantifying car details, and recognizing car orientations. We discuss the process of collecting a robust dataset necessary for training our models, and describe an approach we have designed to augment and improve this dataset continually. Our method leverages a feedback loop for continuous model improvement, thus enhancing the performance and accuracy of RaceLens over time. A significant part of our study is dedicated to illustrating the practical application of RaceLens, focusing on its successful deployment by NASCAR teams over four seasons. We provide a comprehensive evaluation of our system's performance and its direct impact on the team's strategic decisions and performance metrics. The results underscore the transformative potential of machine intelligence in the competitive and dynamic world of car racing, setting a precedent for future applications.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Multi-Task Meta-Learning Modification with Stochastic Approximation
Nov 05, 2021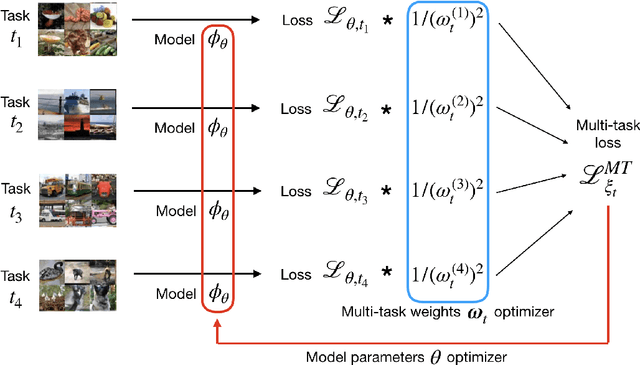

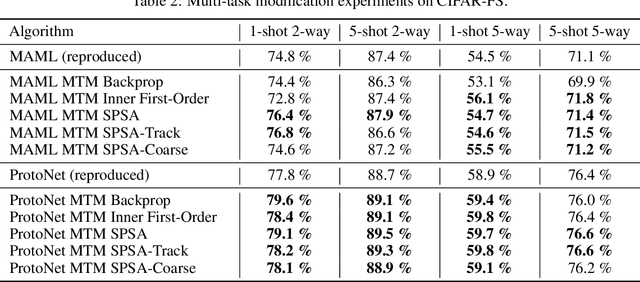

Meta-learning methods aim to build learning algorithms capable of quickly adapting to new tasks in low-data regime. One of the main benchmarks of such an algorithms is a few-shot learning problem. In this paper we investigate the modification of standard meta-learning pipeline that takes a multi-task approach during training. The proposed method simultaneously utilizes information from several meta-training tasks in a common loss function. The impact of each of these tasks in the loss function is controlled by the corresponding weight. Proper optimization of these weights can have a big influence on training of the entire model and might improve the quality on test time tasks. In this work we propose and investigate the use of methods from the family of simultaneous perturbation stochastic approximation (SPSA) approaches for meta-train tasks weights optimization. We have also compared the proposed algorithms with gradient-based methods and found that stochastic approximation demonstrates the largest quality boost in test time. Proposed multi-task modification can be applied to almost all methods that use meta-learning pipeline. In this paper we study applications of this modification on Prototypical Networks and Model-Agnostic Meta-Learning algorithms on CIFAR-FS, FC100, tieredImageNet and miniImageNet few-shot learning benchmarks. During these experiments, multi-task modification has demonstrated improvement over original methods. The proposed SPSA-Tracking algorithm shows the largest accuracy boost that is competitive against the state-of-the-art meta-learning methods. Our code is available online.
Simultaneous Perturbation Stochastic Approximation for Few-Shot Learning
Jun 09, 2020

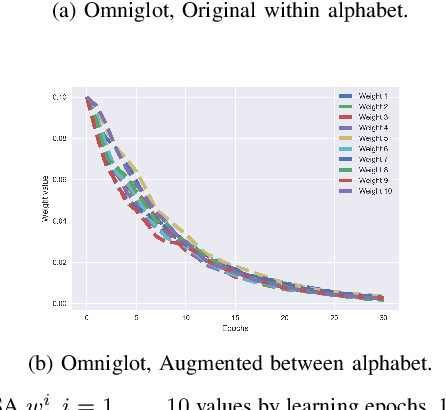

Few-shot learning is an important research field of machine learning in which a classifier must be trained in such a way that it can adapt to new classes which are not included in the training set. However, only small amounts of examples of each class are available for training. This is one of the key problems with learning algorithms of this type which leads to the significant uncertainty. We attack this problem via randomized stochastic approximation. In this paper, we suggest to consider the new multi-task loss function and propose the SPSA-like few-shot learning approach based on the prototypical networks method. We provide a theoretical justification and an analysis of experiments for this approach. The results of experiments on the benchmark dataset demonstrate that the proposed method is superior to the original prototypical networks.
Large Scale Landmark Recognition via Deep Metric Learning
Aug 29, 2019

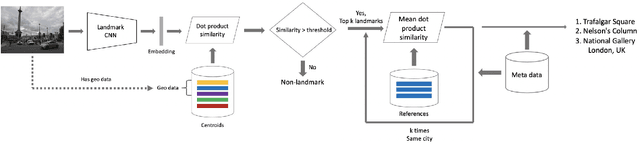

This paper presents a novel approach for landmark recognition in images that we've successfully deployed at Mail ru. This method enables us to recognize famous places, buildings, monuments, and other landmarks in user photos. The main challenge lies in the fact that it's very complicated to give a precise definition of what is and what is not a landmark. Some buildings, statues and natural objects are landmarks; others are not. There's also no database with a fairly large number of landmarks to train a recognition model. A key feature of using landmark recognition in a production environment is that the number of photos containing landmarks is extremely small. This is why the model should have a very low false positive rate as well as high recognition accuracy. We propose a metric learning-based approach that successfully deals with existing challenges and efficiently handles a large number of landmarks. Our method uses a deep neural network and requires a single pass inference that makes it fast to use in production. We also describe an algorithm for cleaning landmarks database which is essential for training a metric learning model. We provide an in-depth description of basic components of our method like neural network architecture, the learning strategy, and the features of our metric learning approach. We show the results of proposed solutions in tests that emulate the distribution of photos with and without landmarks from a user collection. We compare our method with others during these tests. The described system has been deployed as a part of a photo recognition solution at Cloud Mail ru, which is the photo sharing and storage service at Mail ru Group.