 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Diffusion Probabilistic Model Sampling through the lens of Backward Error Analysis
Apr 22, 2023



Denoising diffusion probabilistic models (DDPMs) are a class of powerful generative models. The past few years have witnessed the great success of DDPMs in generating high-fidelity samples. A significant limitation of the DDPMs is the slow sampling procedure. DDPMs generally need hundreds or thousands of sequential function evaluations (steps) of neural networks to generate a sample. This paper aims to develop a fast sampling method for DDPMs requiring much fewer steps while retaining high sample quality. The inference process of DDPMs approximates solving the corresponding diffusion ordinary differential equations (diffusion ODEs) in the continuous limit. This work analyzes how the backward error affects the diffusion ODEs and the sample quality in DDPMs. We propose fast sampling through the \textbf{Restricting Backward Error schedule (RBE schedule)} based on dynamically moderating the long-time backward error. Our method accelerates DDPMs without any further training. Our experiments show that sampling with an RBE schedule generates high-quality samples within only 8 to 20 function evaluations on various benchmark datasets. We achieved 12.01 FID in 8 function evaluations on the ImageNet $128\times128$, and a $20\times$ speedup compared with previous baseline samplers.
Raising The Limit Of Image Rescaling Using Auxiliary Encoding
Mar 12, 2023Normalizing flow models using invertible neural networks (INN) have been widely investigated for successful generative image super-resolution (SR) by learning the transformation between the normal distribution of latent variable $z$ and the conditional distribution of high-resolution (HR) images gave a low-resolution (LR) input. Recently, image rescaling models like IRN utilize the bidirectional nature of INN to push the performance limit of image upscaling by optimizing the downscaling and upscaling steps jointly. While the random sampling of latent variable $z$ is useful in generating diverse photo-realistic images, it is not desirable for image rescaling when accurate restoration of the HR image is more important. Hence, in places of random sampling of $z$, we propose auxiliary encoding modules to further push the limit of image rescaling performance. Two options to store the encoded latent variables in downscaled LR images, both readily supported in existing image file format, are proposed. One is saved as the alpha-channel, the other is saved as meta-data in the image header, and the corresponding modules are denoted as suffixes -A and -M respectively. Optimal network architectural changes are investigated for both options to demonstrate their effectiveness in raising the rescaling performance limit on different baseline models including IRN and DLV-IRN.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
SoccerNet-Tracking: Multiple Object Tracking Dataset and Benchmark in Soccer Videos
Apr 20, 2022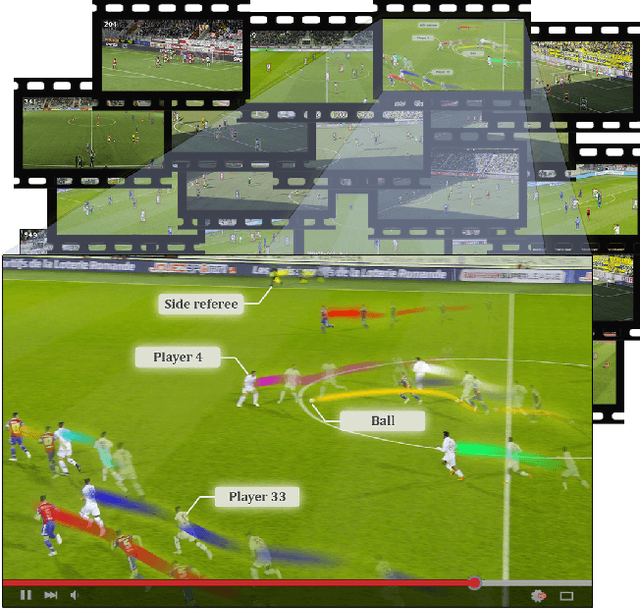
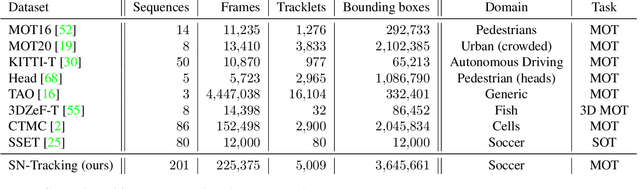
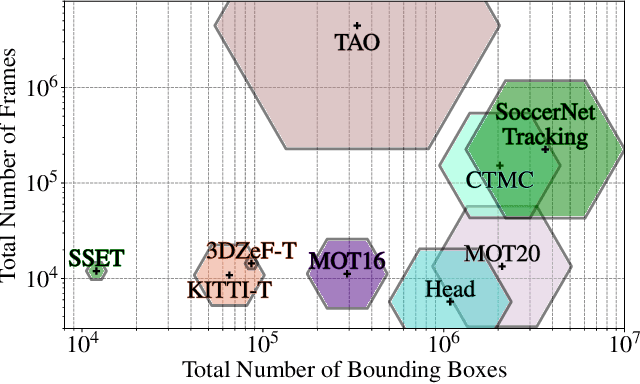
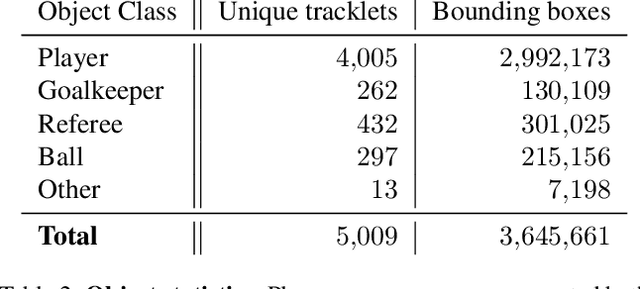
Tracking objects in soccer videos is extremely important to gather both player and team statistics, whether it is to estimate the total distance run, the ball possession or the team formation. Video processing can help automating the extraction of those information, without the need of any invasive sensor, hence applicable to any team on any stadium. Yet, the availability of datasets to train learnable models and benchmarks to evaluate methods on a common testbed is very limited. In this work, we propose a novel dataset for multiple object tracking composed of 200 sequences of 30s each, representative of challenging soccer scenarios, and a complete 45-minutes half-time for long-term tracking. The dataset is fully annotated with bounding boxes and tracklet IDs, enabling the training of MOT baselines in the soccer domain and a full benchmarking of those methods on our segregated challenge sets. Our analysis shows that multiple player, referee and ball tracking in soccer videos is far from being solved, with several improvement required in case of fast motion or in scenarios of severe occlusion.
ASM-Loc: Action-aware Segment Modeling for Weakly-Supervised Temporal Action Localization
Mar 29, 2022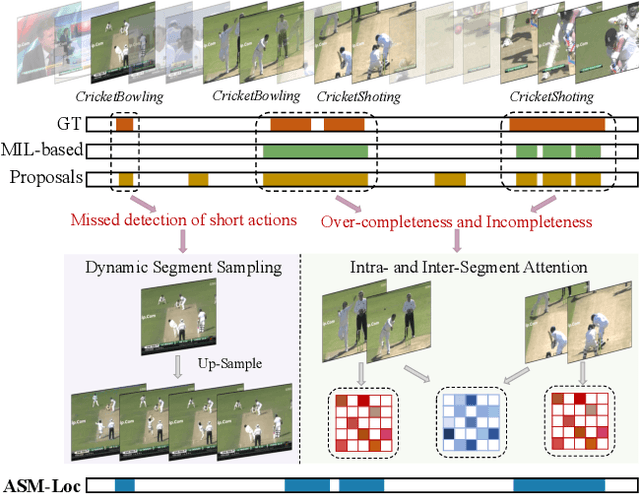
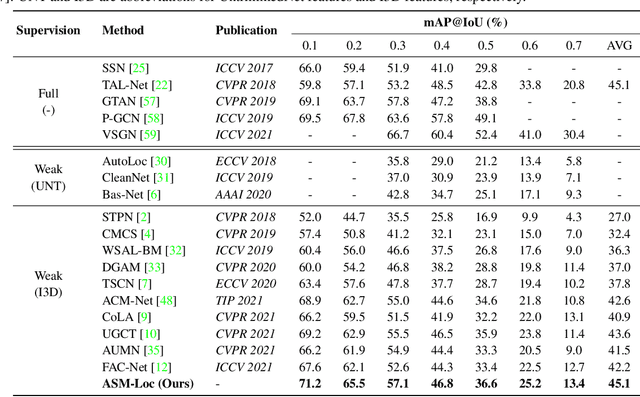
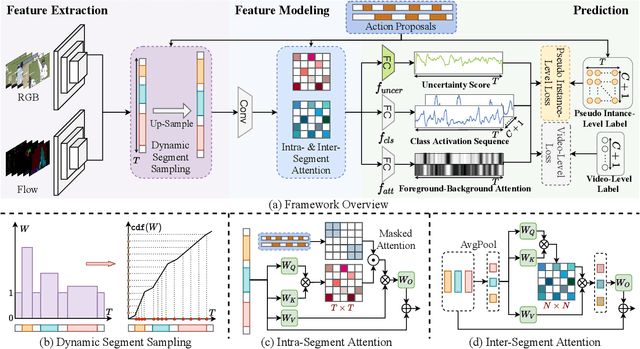
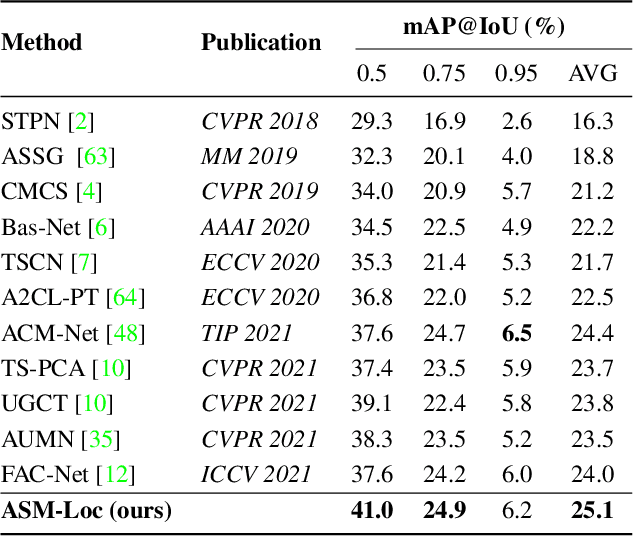
Weakly-supervised temporal action localization aims to recognize and localize action segments in untrimmed videos given only video-level action labels for training. Without the boundary information of action segments, existing methods mostly rely on multiple instance learning (MIL), where the predictions of unlabeled instances (i.e., video snippets) are supervised by classifying labeled bags (i.e., untrimmed videos). However, this formulation typically treats snippets in a video as independent instances, ignoring the underlying temporal structures within and across action segments. To address this problem, we propose \system, a novel WTAL framework that enables explicit, action-aware segment modeling beyond standard MIL-based methods. Our framework entails three segment-centric components: (i) dynamic segment sampling for compensating the contribution of short actions; (ii) intra- and inter-segment attention for modeling action dynamics and capturing temporal dependencies; (iii) pseudo instance-level supervision for improving action boundary prediction. Furthermore, a multi-step refinement strategy is proposed to progressively improve action proposals along the model training process. Extensive experiments on THUMOS-14 and ActivityNet-v1.3 demonstrate the effectiveness of our approach, establishing new state of the art on both datasets. The code and models are publicly available at~\url{https://github.com/boheumd/ASM-Loc}.
Feature Combination Meets Attention: Baidu Soccer Embeddings and Transformer based Temporal Detection
Jun 28, 2021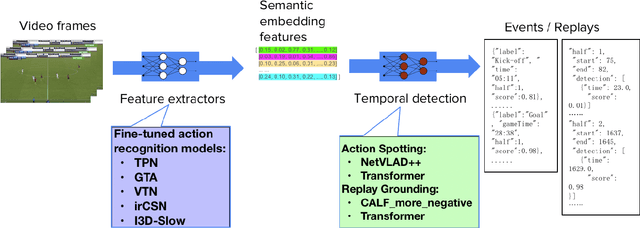
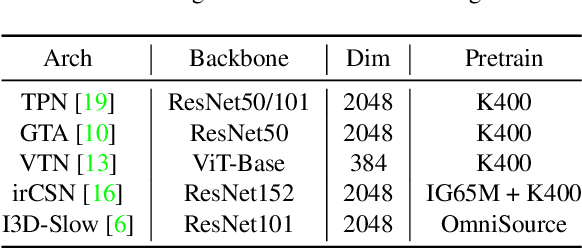
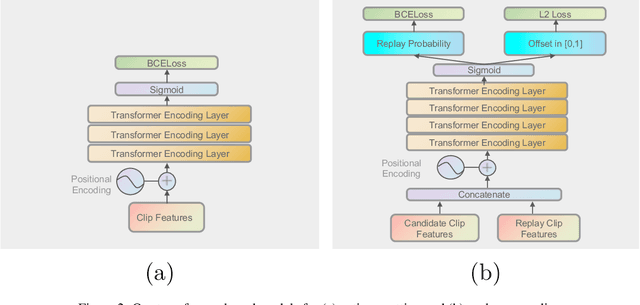
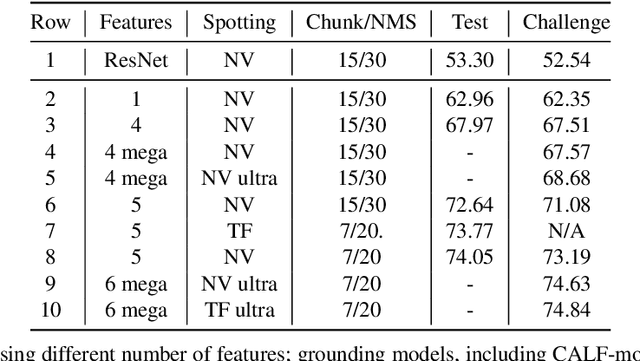
With rapidly evolving internet technologies and emerging tools, sports related videos generated online are increasing at an unprecedentedly fast pace. To automate sports video editing/highlight generation process, a key task is to precisely recognize and locate the events in the long untrimmed videos. In this tech report, we present a two-stage paradigm to detect what and when events happen in soccer broadcast videos. Specifically, we fine-tune multiple action recognition models on soccer data to extract high-level semantic features, and design a transformer based temporal detection module to locate the target events. This approach achieved the state-of-the-art performance in both two tasks, i.e., action spotting and replay grounding, in the SoccerNet-v2 Challenge, under CVPR 2021 ActivityNet workshop. Our soccer embedding features are released at https://github.com/baidu-research/vidpress-sports. By sharing these features with the broader community, we hope to accelerate the research into soccer video understanding.
Sketch-based 3D Shape Retrieval using Convolutional Neural Networks
Apr 14, 2015


Retrieving 3D models from 2D human sketches has received considerable attention in the areas of graphics, image retrieval, and computer vision. Almost always in state of the art approaches a large amount of "best views" are computed for 3D models, with the hope that the query sketch matches one of these 2D projections of 3D models using predefined features. We argue that this two stage approach (view selection -- matching) is pragmatic but also problematic because the "best views" are subjective and ambiguous, which makes the matching inputs obscure. This imprecise nature of matching further makes it challenging to choose features manually. Instead of relying on the elusive concept of "best views" and the hand-crafted features, we propose to define our views using a minimalism approach and learn features for both sketches and views. Specifically, we drastically reduce the number of views to only two predefined directions for the whole dataset. Then, we learn two Siamese Convolutional Neural Networks (CNNs), one for the views and one for the sketches. The loss function is defined on the within-domain as well as the cross-domain similarities. Our experiments on three benchmark datasets demonstrate that our method is significantly better than state of the art approaches, and outperforms them in all conventional metrics.