 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
Quantization-Aware Distillation for NVFP4 Inference Accuracy Recovery
Jan 27, 2026This technical report presents quantization-aware distillation (QAD) and our best practices for recovering accuracy of NVFP4-quantized large language models (LLMs) and vision-language models (VLMs). QAD distills a full-precision teacher model into a quantized student model using a KL divergence loss. While applying distillation to quantized models is not a new idea, we observe key advantages of QAD for today's LLMs: 1. It shows remarkable effectiveness and stability for models trained through multi-stage post-training pipelines, including supervised fine-tuning (SFT), reinforcement learning (RL), and model merging, where traditional quantization-aware training (QAT) suffers from engineering complexity and training instability; 2. It is robust to data quality and coverage, enabling accuracy recovery without full training data. We evaluate QAD across multiple post-trained models including AceReason Nemotron, Nemotron 3 Nano, Nemotron Nano V2, Nemotron Nano V2 VL (VLM), and Llama Nemotron Super v1, showing consistent recovery to near-BF16 accuracy.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
SoccerNet-Tracking: Multiple Object Tracking Dataset and Benchmark in Soccer Videos
Apr 20, 2022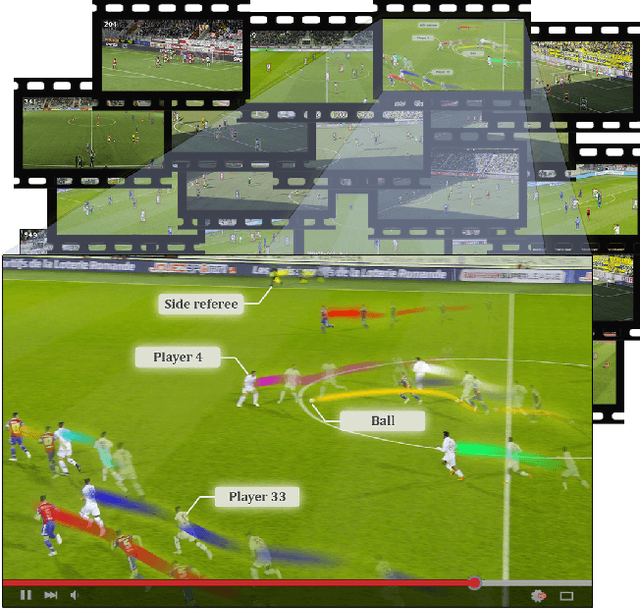
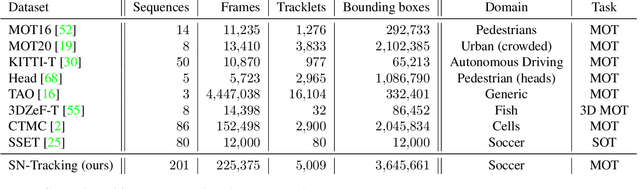
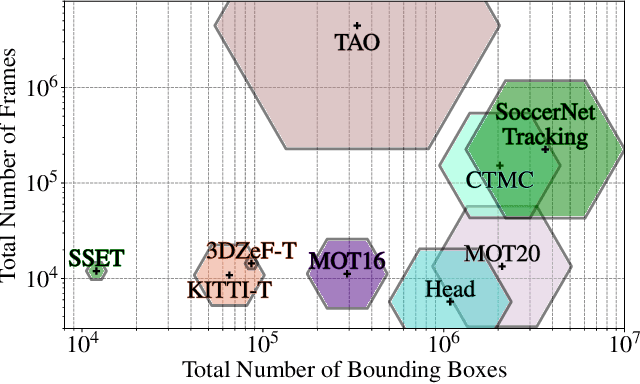
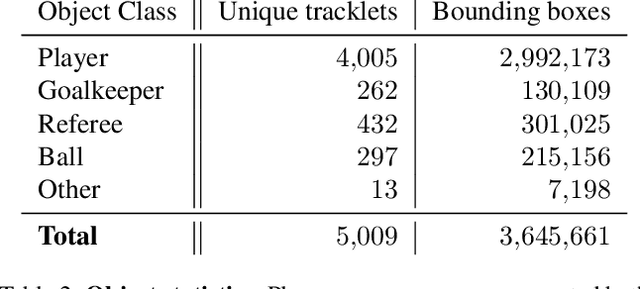
Tracking objects in soccer videos is extremely important to gather both player and team statistics, whether it is to estimate the total distance run, the ball possession or the team formation. Video processing can help automating the extraction of those information, without the need of any invasive sensor, hence applicable to any team on any stadium. Yet, the availability of datasets to train learnable models and benchmarks to evaluate methods on a common testbed is very limited. In this work, we propose a novel dataset for multiple object tracking composed of 200 sequences of 30s each, representative of challenging soccer scenarios, and a complete 45-minutes half-time for long-term tracking. The dataset is fully annotated with bounding boxes and tracklet IDs, enabling the training of MOT baselines in the soccer domain and a full benchmarking of those methods on our segregated challenge sets. Our analysis shows that multiple player, referee and ball tracking in soccer videos is far from being solved, with several improvement required in case of fast motion or in scenarios of severe occlusion.
ASM-Loc: Action-aware Segment Modeling for Weakly-Supervised Temporal Action Localization
Mar 29, 2022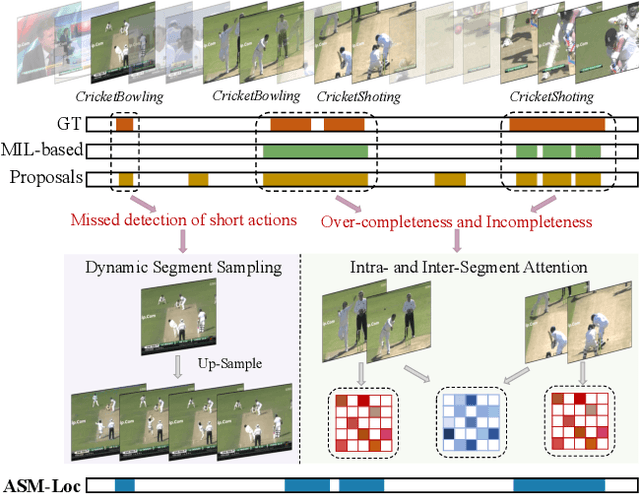
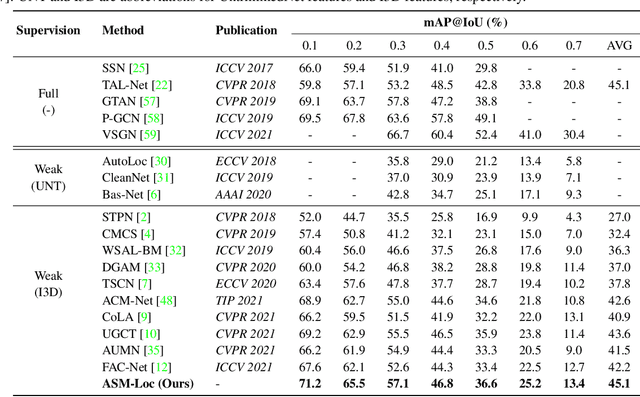
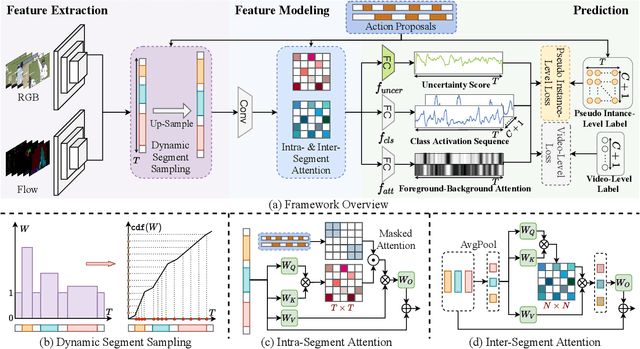
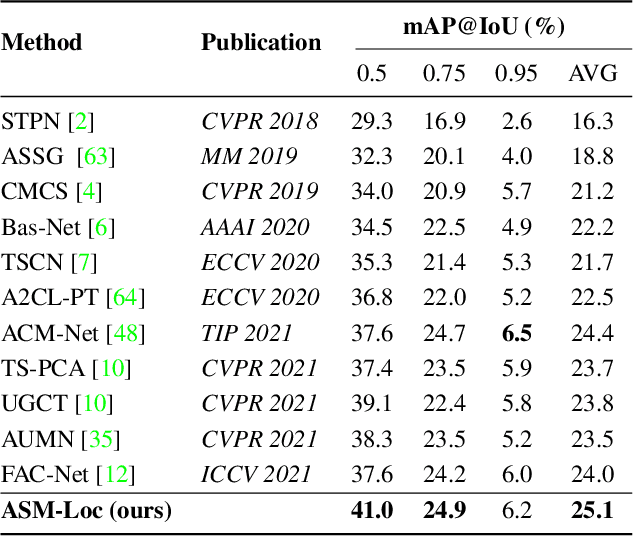
Weakly-supervised temporal action localization aims to recognize and localize action segments in untrimmed videos given only video-level action labels for training. Without the boundary information of action segments, existing methods mostly rely on multiple instance learning (MIL), where the predictions of unlabeled instances (i.e., video snippets) are supervised by classifying labeled bags (i.e., untrimmed videos). However, this formulation typically treats snippets in a video as independent instances, ignoring the underlying temporal structures within and across action segments. To address this problem, we propose \system, a novel WTAL framework that enables explicit, action-aware segment modeling beyond standard MIL-based methods. Our framework entails three segment-centric components: (i) dynamic segment sampling for compensating the contribution of short actions; (ii) intra- and inter-segment attention for modeling action dynamics and capturing temporal dependencies; (iii) pseudo instance-level supervision for improving action boundary prediction. Furthermore, a multi-step refinement strategy is proposed to progressively improve action proposals along the model training process. Extensive experiments on THUMOS-14 and ActivityNet-v1.3 demonstrate the effectiveness of our approach, establishing new state of the art on both datasets. The code and models are publicly available at~\url{https://github.com/boheumd/ASM-Loc}.
Feature Combination Meets Attention: Baidu Soccer Embeddings and Transformer based Temporal Detection
Jun 28, 2021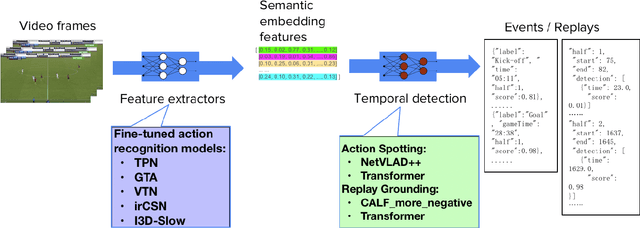
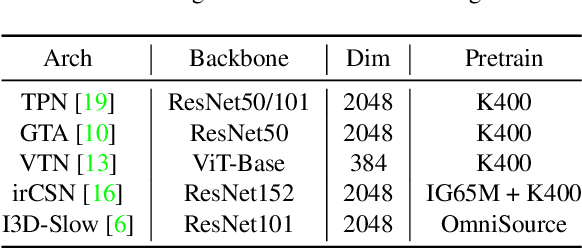
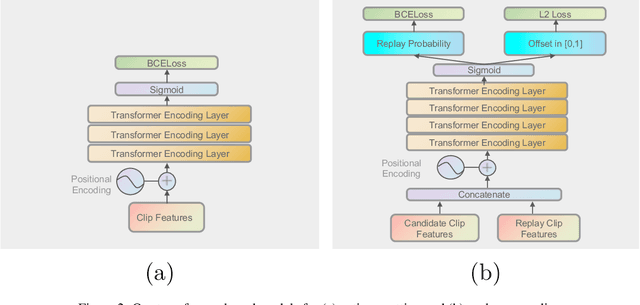
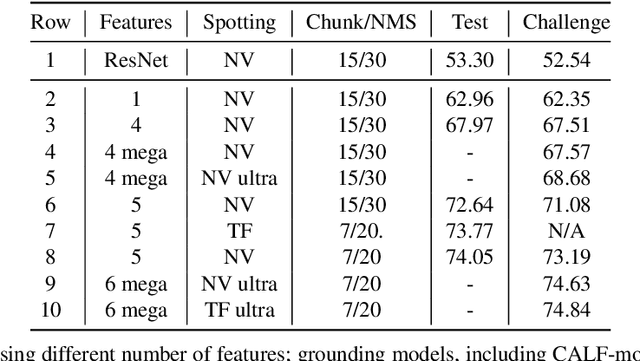
With rapidly evolving internet technologies and emerging tools, sports related videos generated online are increasing at an unprecedentedly fast pace. To automate sports video editing/highlight generation process, a key task is to precisely recognize and locate the events in the long untrimmed videos. In this tech report, we present a two-stage paradigm to detect what and when events happen in soccer broadcast videos. Specifically, we fine-tune multiple action recognition models on soccer data to extract high-level semantic features, and design a transformer based temporal detection module to locate the target events. This approach achieved the state-of-the-art performance in both two tasks, i.e., action spotting and replay grounding, in the SoccerNet-v2 Challenge, under CVPR 2021 ActivityNet workshop. Our soccer embedding features are released at https://github.com/baidu-research/vidpress-sports. By sharing these features with the broader community, we hope to accelerate the research into soccer video understanding.