 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Generation of Co-Speech Gestures via Accelerated Rolling Diffusion
Paper and Code
Mar 13, 2025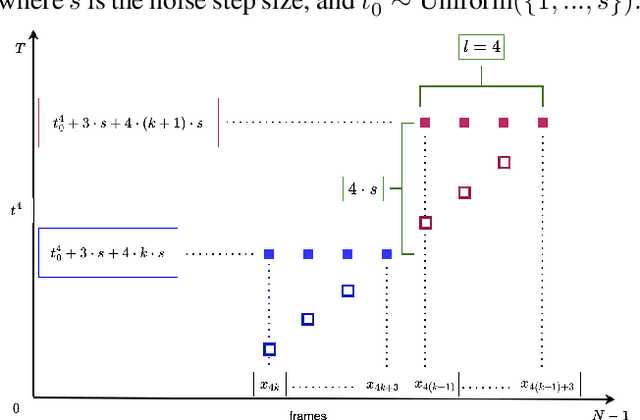


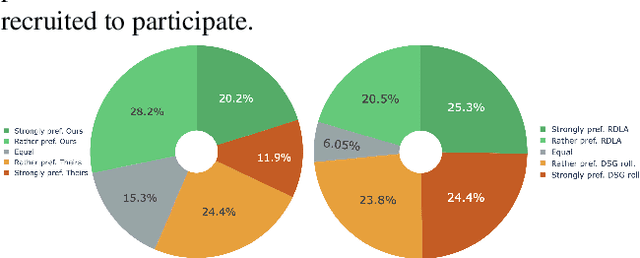
Generating co-speech gestures in real time requires both temporal coherence and efficient sampling. We introduce Accelerated Rolling Diffusion, a novel framework for streaming gesture generation that extends rolling diffusion models with structured progressive noise scheduling, enabling seamless long-sequence motion synthesis while preserving realism and diversity. We further propose Rolling Diffusion Ladder Acceleration (RDLA), a new approach that restructures the noise schedule into a stepwise ladder, allowing multiple frames to be denoised simultaneously. This significantly improves sampling efficiency while maintaining motion consistency, achieving up to a 2x speedup with high visual fidelity and temporal coherence. We evaluate our approach on ZEGGS and BEAT, strong benchmarks for real-world applicability. Our framework is universally applicable to any diffusion-based gesture generation model, transforming it into a streaming approach. Applied to three state-of-the-art methods, it consistently outperforms them, demonstrating its effectiveness as a generalizable and efficient solution for real-time, high-fidelity co-speech gesture synthesis.