 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-TS Integrator: Integrating LLM for Enhanced Time Series Modeling
Oct 21, 2024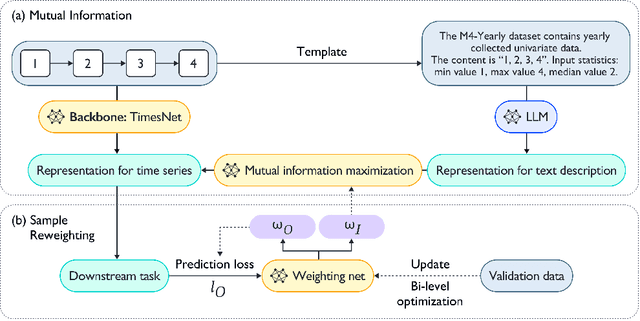

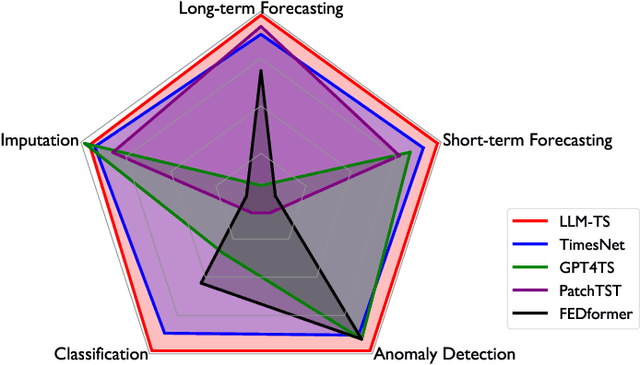
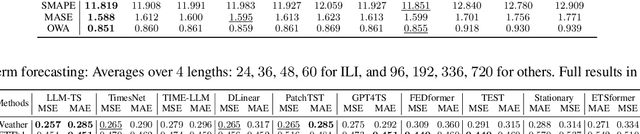
Time series~(TS) modeling is essential in dynamic systems like weather prediction and anomaly detection. Recent studies utilize Large Language Models (LLMs) for TS modeling, leveraging their powerful pattern recognition capabilities. These methods primarily position LLMs as the predictive backbone, often omitting the mathematical modeling within traditional TS models, such as periodicity. However, disregarding the potential of LLMs also overlooks their pattern recognition capabilities. To address this gap, we introduce \textit{LLM-TS Integrator}, a novel framework that effectively integrates the capabilities of LLMs into traditional TS modeling. Central to this integration is our \textit{mutual information} module. The core of this \textit{mutual information} module is a traditional TS model enhanced with LLM-derived insights for improved predictive abilities. This enhancement is achieved by maximizing the mutual information between traditional model's TS representations and LLM's textual representation counterparts, bridging the two modalities. Moreover, we recognize that samples vary in importance for two losses: traditional prediction and mutual information maximization. To address this variability, we introduce the \textit{sample reweighting} module to improve information utilization. This module assigns dual weights to each sample: one for prediction loss and another for mutual information loss, dynamically optimizing these weights via bi-level optimization. Our method achieves state-of-the-art or comparable performance across five mainstream TS tasks, including short-term and long-term forecasting, imputation, classification, and anomaly detection.
DynaShare: Task and Instance Conditioned Parameter Sharing for Multi-Task Learning
May 26, 2023Multi-task networks rely on effective parameter sharing to achieve robust generalization across tasks. In this paper, we present a novel parameter sharing method for multi-task learning that conditions parameter sharing on both the task and the intermediate feature representations at inference time. In contrast to traditional parameter sharing approaches, which fix or learn a deterministic sharing pattern during training and apply the same pattern to all examples during inference, we propose to dynamically decide which parts of the network to activate based on both the task and the input instance. Our approach learns a hierarchical gating policy consisting of a task-specific policy for coarse layer selection and gating units for individual input instances, which work together to determine the execution path at inference time. Experiments on the NYU v2, Cityscapes and MIMIC-III datasets demonstrate the potential of the proposed approach and its applicability across problem domains.
Gumbel-Softmax Selective Networks
Nov 19, 2022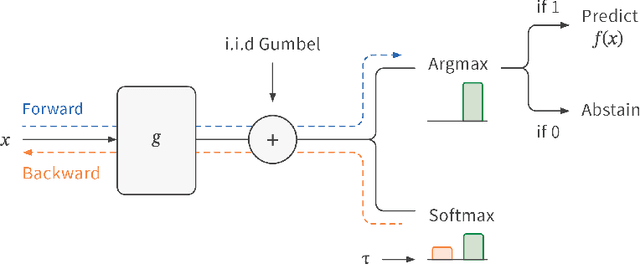
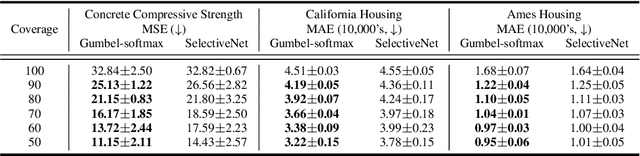

ML models often operate within the context of a larger system that can adapt its response when the ML model is uncertain, such as falling back on safe defaults or a human in the loop. This commonly encountered operational context calls for principled techniques for training ML models with the option to abstain from predicting when uncertain. Selective neural networks are trained with an integrated option to abstain, allowing them to learn to recognize and optimize for the subset of the data distribution for which confident predictions can be made. However, optimizing selective networks is challenging due to the non-differentiability of the binary selection function (the discrete decision of whether to predict or abstain). This paper presents a general method for training selective networks that leverages the Gumbel-softmax reparameterization trick to enable selection within an end-to-end differentiable training framework. Experiments on public datasets demonstrate the potential of Gumbel-softmax selective networks for selective regression and classification.