 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Automated End-to-End Open-Source Software for High-Quality Text-to-Speech Dataset Generation
Feb 26, 2024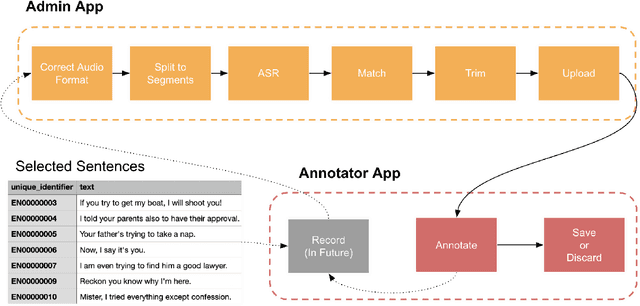


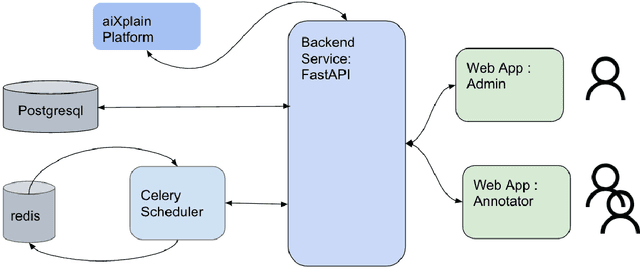
Data availability is crucial for advancing artificial intelligence applications, including voice-based technologies. As content creation, particularly in social media, experiences increasing demand, translation and text-to-speech (TTS) technologies have become essential tools. Notably, the performance of these TTS technologies is highly dependent on the quality of the training data, emphasizing the mutual dependence of data availability and technological progress. This paper introduces an end-to-end tool to generate high-quality datasets for text-to-speech (TTS) models to address this critical need for high-quality data. The contributions of this work are manifold and include: the integration of language-specific phoneme distribution into sample selection, automation of the recording process, automated and human-in-the-loop quality assurance of recordings, and processing of recordings to meet specified formats. The proposed application aims to streamline the dataset creation process for TTS models through these features, thereby facilitating advancements in voice-based technologies.
Word-Level ASR Quality Estimation for Efficient Corpus Sampling and Post-Editing through Analyzing Attentions of a Reference-Free Metric
Feb 02, 2024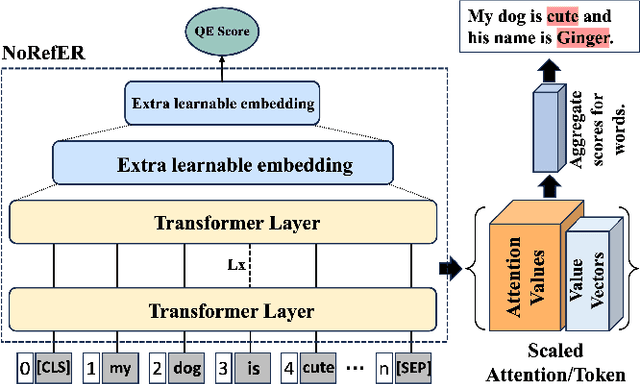

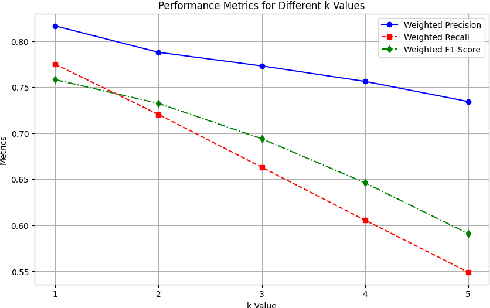
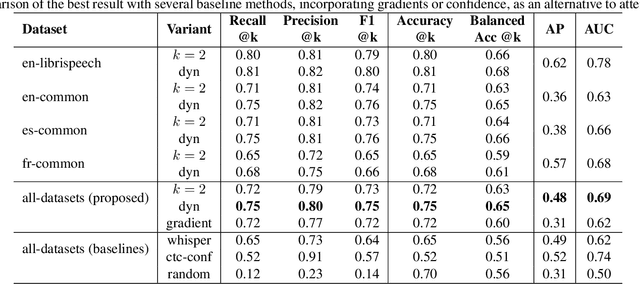
In the realm of automatic speech recognition (ASR), the quest for models that not only perform with high accuracy but also offer transparency in their decision-making processes is crucial. The potential of quality estimation (QE) metrics is introduced and evaluated as a novel tool to enhance explainable artificial intelligence (XAI) in ASR systems. Through experiments and analyses, the capabilities of the NoRefER (No Reference Error Rate) metric are explored in identifying word-level errors to aid post-editors in refining ASR hypotheses. The investigation also extends to the utility of NoRefER in the corpus-building process, demonstrating its effectiveness in augmenting datasets with insightful annotations. The diagnostic aspects of NoRefER are examined, revealing its ability to provide valuable insights into model behaviors and decision patterns. This has proven beneficial for prioritizing hypotheses in post-editing workflows and fine-tuning ASR models. The findings suggest that NoRefER is not merely a tool for error detection but also a comprehensive framework for enhancing ASR systems' transparency, efficiency, and effectiveness. To ensure the reproducibility of the results, all source codes of this study are made publicly available.
NoRefER: a Referenceless Quality Metric for Automatic Speech Recognition via Semi-Supervised Language Model Fine-Tuning with Contrastive Learning
Jun 21, 2023This paper introduces NoRefER, a novel referenceless quality metric for automatic speech recognition (ASR) systems. Traditional reference-based metrics for evaluating ASR systems require costly ground-truth transcripts. NoRefER overcomes this limitation by fine-tuning a multilingual language model for pair-wise ranking ASR hypotheses using contrastive learning with Siamese network architecture. The self-supervised NoRefER exploits the known quality relationships between hypotheses from multiple compression levels of an ASR for learning to rank intra-sample hypotheses by quality, which is essential for model comparisons. The semi-supervised version also uses a referenced dataset to improve its inter-sample quality ranking, which is crucial for selecting potentially erroneous samples. The results indicate that NoRefER correlates highly with reference-based metrics and their intra-sample ranks, indicating a high potential for referenceless ASR evaluation or a/b testing.
A Reference-less Quality Metric for Automatic Speech Recognition via Contrastive-Learning of a Multi-Language Model with Self-Supervision
Jun 21, 2023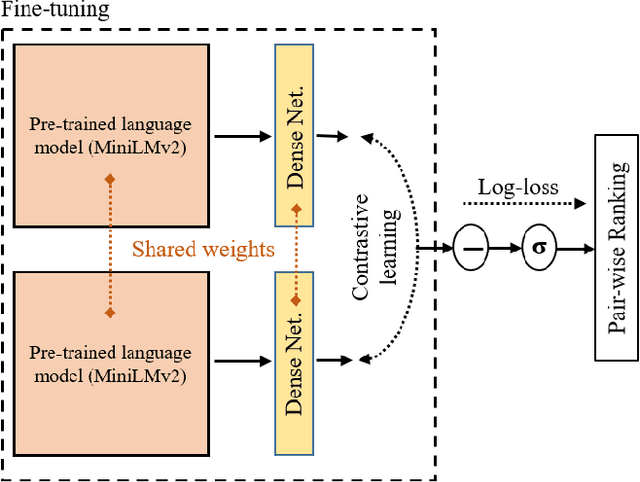
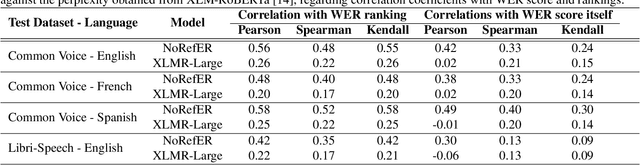
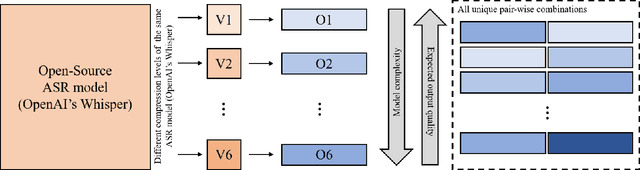
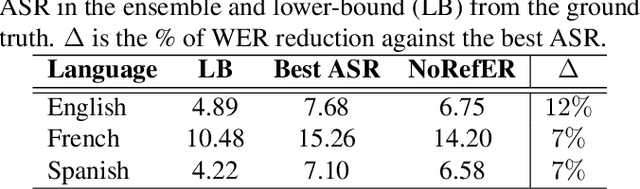
The common standard for quality evaluation of automatic speech recognition (ASR) systems is reference-based metrics such as the Word Error Rate (WER), computed using manual ground-truth transcriptions that are time-consuming and expensive to obtain. This work proposes a multi-language referenceless quality metric, which allows comparing the performance of different ASR models on a speech dataset without ground truth transcriptions. To estimate the quality of ASR hypotheses, a pre-trained language model (LM) is fine-tuned with contrastive learning in a self-supervised learning manner. In experiments conducted on several unseen test datasets consisting of outputs from top commercial ASR engines in various languages, the proposed referenceless metric obtains a much higher correlation with WER scores and their ranks than the perplexity metric from the state-of-art multi-lingual LM in all experiments, and also reduces WER by more than $7\%$ when used for ensembling hypotheses. The fine-tuned model and experiments are made available for the reproducibility: https://github.com/aixplain/NoRefER
DynaShare: Task and Instance Conditioned Parameter Sharing for Multi-Task Learning
May 26, 2023Multi-task networks rely on effective parameter sharing to achieve robust generalization across tasks. In this paper, we present a novel parameter sharing method for multi-task learning that conditions parameter sharing on both the task and the intermediate feature representations at inference time. In contrast to traditional parameter sharing approaches, which fix or learn a deterministic sharing pattern during training and apply the same pattern to all examples during inference, we propose to dynamically decide which parts of the network to activate based on both the task and the input instance. Our approach learns a hierarchical gating policy consisting of a task-specific policy for coarse layer selection and gating units for individual input instances, which work together to determine the execution path at inference time. Experiments on the NYU v2, Cityscapes and MIMIC-III datasets demonstrate the potential of the proposed approach and its applicability across problem domains.