 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAACE: A Plan-Aware Automated Agent Context Engineering Framework
Dec 18, 2025Large Language Model (LLM) agents are increasingly deployed in complex, multi-step workflows involving planning, tool use, reflection, and interaction with external knowledge systems. These workflows generate rapidly expanding contexts that must be curated, transformed, and compressed to maintain fidelity, avoid attention dilution, and reduce inference cost. Prior work on summarization and query-aware compression largely ignores the multi-step, plan-aware nature of agentic reasoning. In this work, we introduce PAACE (Plan-Aware Automated Context Engineering), a unified framework for optimizing the evolving state of LLM agents through next-k-task relevance modeling, plan-structure analysis, instruction co-refinement, and function-preserving compression. PAACE comprises (1) PAACE-Syn, a large-scale generator of synthetic agent workflows annotated with stepwise compression supervision, and (2) PAACE-FT, a family of distilled, plan-aware compressors trained from successful teacher demonstrations. Experiments on long-horizon benchmarks (AppWorld, OfficeBench, and 8-Objective QA) demonstrate that PAACE consistently improves agent correctness while substantially reducing context load. On AppWorld, PAACE achieves higher accuracy than all baselines while lowering peak context and cumulative dependency. On OfficeBench and multi-hop QA, PAACE improves both accuracy and F1, achieving fewer steps, lower peak tokens, and reduced attention dependency. Distilled PAACE-FT retains 97 percent of the teacher's performance while reducing inference cost by over an order of magnitude, enabling practical deployment of plan-aware compression with compact models.
EvoLattice: Persistent Internal-Population Evolution through Multi-Alternative Quality-Diversity Graph Representations for LLM-Guided Program Discovery
Dec 17, 2025Large language models (LLMs) are increasingly used to evolve programs and multi-agent systems, yet most existing approaches rely on overwrite-based mutations that maintain only a single candidate at a time. Such methods discard useful variants, suffer from destructive edits, and explore a brittle search space prone to structural failure. We introduce EvoLattice, a framework that represents an entire population of candidate programs or agent behaviors within a single directed acyclic graph. Each node stores multiple persistent alternatives, and every valid path through the graph defines a distinct executable candidate, yielding a large combinatorial search space without duplicating structure. EvoLattice enables fine-grained alternative-level evaluation by scoring each alternative across all paths in which it appears, producing statistics that reveal how local design choices affect global performance. These statistics provide a dense, data-driven feedback signal for LLM-guided mutation, recombination, and pruning, while preserving successful components. Structural correctness is guaranteed by a deterministic self-repair mechanism that enforces acyclicity and dependency consistency independently of the LLM. EvoLattice naturally extends to agent evolution by interpreting alternatives as prompt fragments or sub-agent behaviors. Across program synthesis (proxy and optimizer meta-learning), EvoLattice yields more stable evolution, greater expressivity, and stronger improvement trajectories than prior LLM-guided methods. The resulting dynamics resemble quality-diversity optimization, emerging implicitly from EvoLattice's internal multi-alternative representation rather than an explicit external archive.
MediaMind: Revolutionizing Media Monitoring using Agentification
Feb 18, 2025In an era of rapid technological advancements, agentification of software tools has emerged as a critical innovation, enabling systems to function autonomously and adaptively. This paper introduces MediaMind as a case study to demonstrate the agentification process, highlighting how existing software can be transformed into intelligent agents capable of independent decision-making and dynamic interaction. Developed by aiXplain, MediaMind leverages agent-based architecture to autonomously monitor, analyze, and provide insights from multilingual media content in real time. The focus of this paper is on the technical methodologies and design principles behind agentifying MediaMind, showcasing how agentification enhances adaptability, efficiency, and responsiveness. Through detailed case studies and practical examples, we illustrate how the agentification of MediaMind empowers organizations to streamline workflows, optimize decision-making, and respond to evolving trends. This work underscores the broader potential of agentification to revolutionize software tools across various domains.
ChamaleonLLM: Batch-Aware Dynamic Low-Rank Adaptation via Inference-Time Clusters
Feb 09, 2025
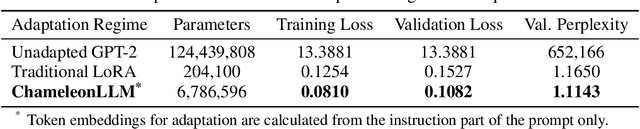
Recent advances in large language models (LLMs) have shown remarkable performance across diverse tasks. However, these models are typically deployed with fixed weights, which limits their ability to adapt dynamically to the variability inherent in real-world data during inference. This paper introduces ChamaleonLLM, a novel framework that enables inference-time adaptation of LLMs by leveraging batch-aware clustering and on-the-fly generation of low-rank updates. Unlike traditional fine-tuning approaches such as Low-Rank Adaptation (LoRA) or methods that rely on a fixed set of pre-learned uniforms (changeable masks), our method dynamically generates adaptive modifications to the decoder weights based on the aggregated statistics of clustered batches. By intelligently grouping similar inputs and computing context-aware low-rank updates via a hyper-network, ChamaleonLLM achieves significant performance gains, outperforming conventional LoRA methods while eliminating the overhead of maintaining multiple expert models. Our experiments highlight the potential of our approach to serve as a versatile and highly adaptive solution for language model inference. ChamaleonLLM is open-sourced to ensure the reproducibility of our experiments: https://anonymous.4open.science/r/ChamaleonLLM/
A Multi-AI Agent System for Autonomous Optimization of Agentic AI Solutions via Iterative Refinement and LLM-Driven Feedback Loops
Dec 22, 2024



Agentic AI systems use specialized agents to handle tasks within complex workflows, enabling automation and efficiency. However, optimizing these systems often requires labor-intensive, manual adjustments to refine roles, tasks, and interactions. This paper introduces a framework for autonomously optimizing Agentic AI solutions across industries, such as NLP-driven enterprise applications. The system employs agents for Refinement, Execution, Evaluation, Modification, and Documentation, leveraging iterative feedback loops powered by an LLM (Llama 3.2-3B). The framework achieves optimal performance without human input by autonomously generating and testing hypotheses to improve system configurations. This approach enhances scalability and adaptability, offering a robust solution for real-world applications in dynamic environments. Case studies across diverse domains illustrate the transformative impact of this framework, showcasing significant improvements in output quality, relevance, and actionability. All data for these case studies, including original and evolved agent codes, along with their outputs, are here: https://anonymous.4open.science/r/evolver-1D11/
An Automated End-to-End Open-Source Software for High-Quality Text-to-Speech Dataset Generation
Feb 26, 2024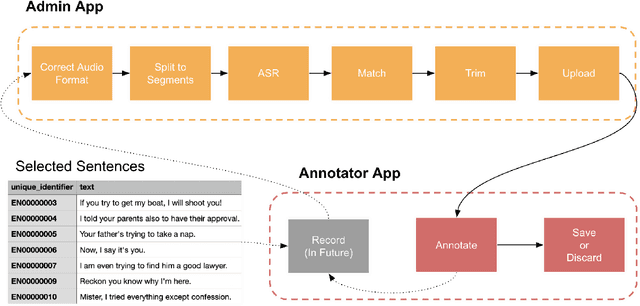


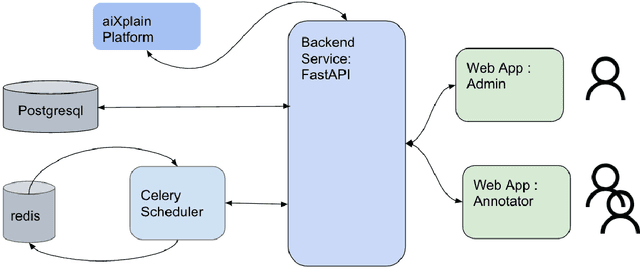
Data availability is crucial for advancing artificial intelligence applications, including voice-based technologies. As content creation, particularly in social media, experiences increasing demand, translation and text-to-speech (TTS) technologies have become essential tools. Notably, the performance of these TTS technologies is highly dependent on the quality of the training data, emphasizing the mutual dependence of data availability and technological progress. This paper introduces an end-to-end tool to generate high-quality datasets for text-to-speech (TTS) models to address this critical need for high-quality data. The contributions of this work are manifold and include: the integration of language-specific phoneme distribution into sample selection, automation of the recording process, automated and human-in-the-loop quality assurance of recordings, and processing of recordings to meet specified formats. The proposed application aims to streamline the dataset creation process for TTS models through these features, thereby facilitating advancements in voice-based technologies.
Word-Level ASR Quality Estimation for Efficient Corpus Sampling and Post-Editing through Analyzing Attentions of a Reference-Free Metric
Feb 02, 2024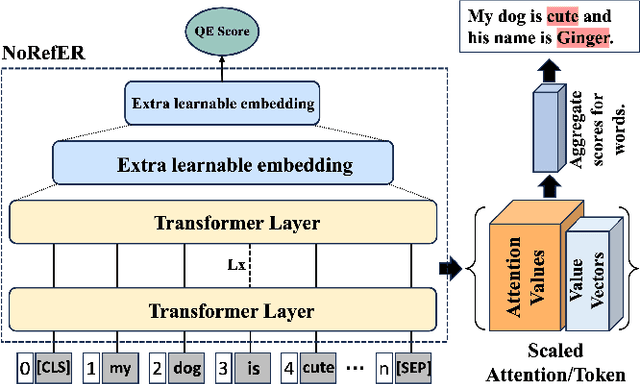

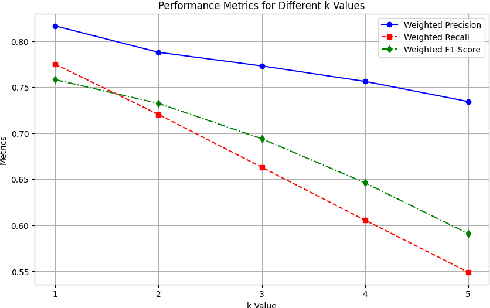
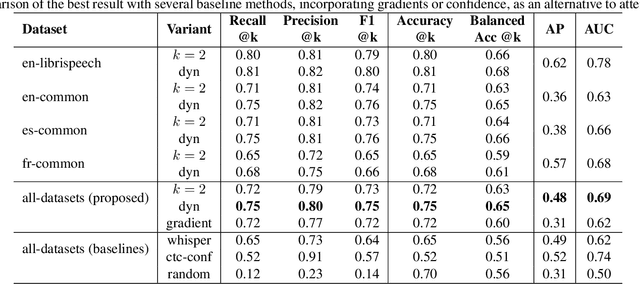
In the realm of automatic speech recognition (ASR), the quest for models that not only perform with high accuracy but also offer transparency in their decision-making processes is crucial. The potential of quality estimation (QE) metrics is introduced and evaluated as a novel tool to enhance explainable artificial intelligence (XAI) in ASR systems. Through experiments and analyses, the capabilities of the NoRefER (No Reference Error Rate) metric are explored in identifying word-level errors to aid post-editors in refining ASR hypotheses. The investigation also extends to the utility of NoRefER in the corpus-building process, demonstrating its effectiveness in augmenting datasets with insightful annotations. The diagnostic aspects of NoRefER are examined, revealing its ability to provide valuable insights into model behaviors and decision patterns. This has proven beneficial for prioritizing hypotheses in post-editing workflows and fine-tuning ASR models. The findings suggest that NoRefER is not merely a tool for error detection but also a comprehensive framework for enhancing ASR systems' transparency, efficiency, and effectiveness. To ensure the reproducibility of the results, all source codes of this study are made publicly available.
Generative Meta-Learning Robust Quality-Diversity Portfolio
Jul 15, 2023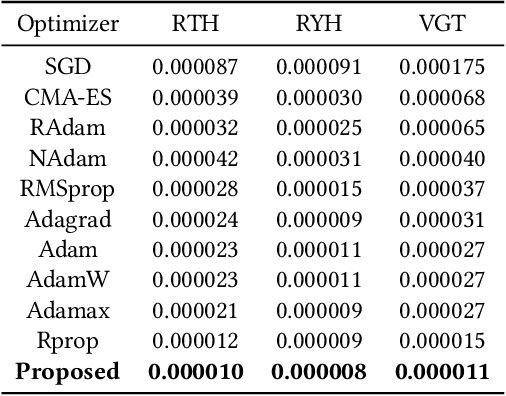
This paper proposes a novel meta-learning approach to optimize a robust portfolio ensemble. The method uses a deep generative model to generate diverse and high-quality sub-portfolios combined to form the ensemble portfolio. The generative model consists of a convolutional layer, a stateful LSTM module, and a dense network. During training, the model takes a randomly sampled batch of Gaussian noise and outputs a population of solutions, which are then evaluated using the objective function of the problem. The weights of the model are updated using a gradient-based optimizer. The convolutional layer transforms the noise into a desired distribution in latent space, while the LSTM module adds dependence between generations. The dense network decodes the population of solutions. The proposed method balances maximizing the performance of the sub-portfolios with minimizing their maximum correlation, resulting in a robust ensemble portfolio against systematic shocks. The approach was effective in experiments where stochastic rewards were present. Moreover, the results (Fig. 1) demonstrated that the ensemble portfolio obtained by taking the average of the generated sub-portfolio weights was robust and generalized well. The proposed method can be applied to problems where diversity is desired among co-optimized solutions for a robust ensemble. The source-codes and the dataset are in the supplementary material.
NoRefER: a Referenceless Quality Metric for Automatic Speech Recognition via Semi-Supervised Language Model Fine-Tuning with Contrastive Learning
Jun 21, 2023This paper introduces NoRefER, a novel referenceless quality metric for automatic speech recognition (ASR) systems. Traditional reference-based metrics for evaluating ASR systems require costly ground-truth transcripts. NoRefER overcomes this limitation by fine-tuning a multilingual language model for pair-wise ranking ASR hypotheses using contrastive learning with Siamese network architecture. The self-supervised NoRefER exploits the known quality relationships between hypotheses from multiple compression levels of an ASR for learning to rank intra-sample hypotheses by quality, which is essential for model comparisons. The semi-supervised version also uses a referenced dataset to improve its inter-sample quality ranking, which is crucial for selecting potentially erroneous samples. The results indicate that NoRefER correlates highly with reference-based metrics and their intra-sample ranks, indicating a high potential for referenceless ASR evaluation or a/b testing.
A Reference-less Quality Metric for Automatic Speech Recognition via Contrastive-Learning of a Multi-Language Model with Self-Supervision
Jun 21, 2023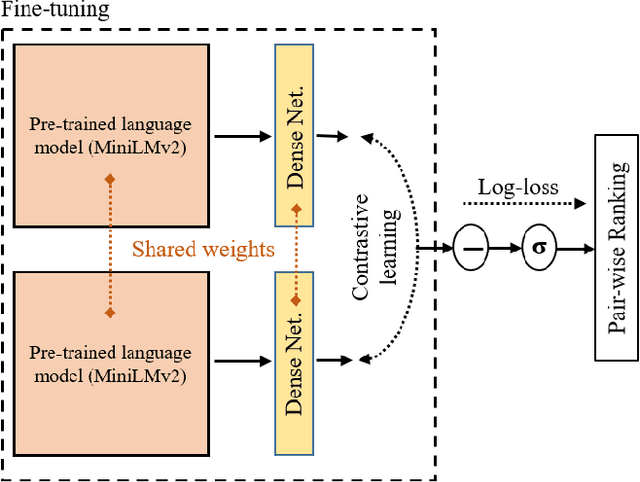
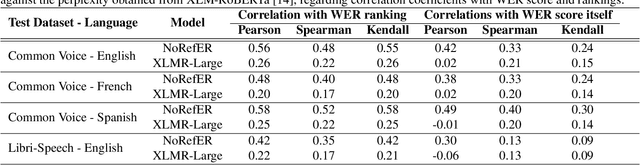
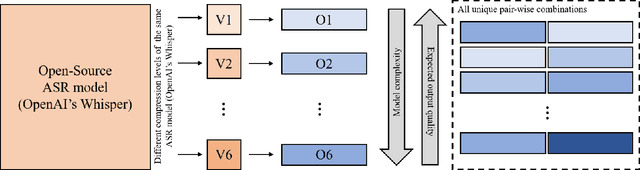
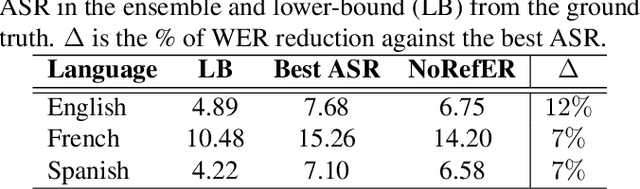
The common standard for quality evaluation of automatic speech recognition (ASR) systems is reference-based metrics such as the Word Error Rate (WER), computed using manual ground-truth transcriptions that are time-consuming and expensive to obtain. This work proposes a multi-language referenceless quality metric, which allows comparing the performance of different ASR models on a speech dataset without ground truth transcriptions. To estimate the quality of ASR hypotheses, a pre-trained language model (LM) is fine-tuned with contrastive learning in a self-supervised learning manner. In experiments conducted on several unseen test datasets consisting of outputs from top commercial ASR engines in various languages, the proposed referenceless metric obtains a much higher correlation with WER scores and their ranks than the perplexity metric from the state-of-art multi-lingual LM in all experiments, and also reduces WER by more than $7\%$ when used for ensembling hypotheses. The fine-tuned model and experiments are made available for the reproducibility: https://github.com/aixplain/NoRefER