 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMediaMind: Revolutionizing Media Monitoring using Agentification
Feb 18, 2025In an era of rapid technological advancements, agentification of software tools has emerged as a critical innovation, enabling systems to function autonomously and adaptively. This paper introduces MediaMind as a case study to demonstrate the agentification process, highlighting how existing software can be transformed into intelligent agents capable of independent decision-making and dynamic interaction. Developed by aiXplain, MediaMind leverages agent-based architecture to autonomously monitor, analyze, and provide insights from multilingual media content in real time. The focus of this paper is on the technical methodologies and design principles behind agentifying MediaMind, showcasing how agentification enhances adaptability, efficiency, and responsiveness. Through detailed case studies and practical examples, we illustrate how the agentification of MediaMind empowers organizations to streamline workflows, optimize decision-making, and respond to evolving trends. This work underscores the broader potential of agentification to revolutionize software tools across various domains.
An Automated End-to-End Open-Source Software for High-Quality Text-to-Speech Dataset Generation
Feb 26, 2024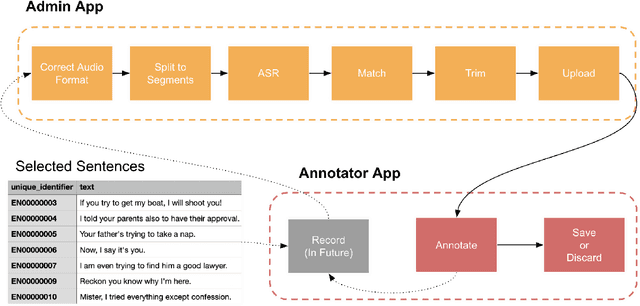


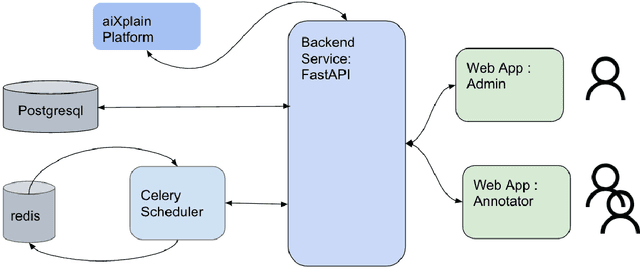
Data availability is crucial for advancing artificial intelligence applications, including voice-based technologies. As content creation, particularly in social media, experiences increasing demand, translation and text-to-speech (TTS) technologies have become essential tools. Notably, the performance of these TTS technologies is highly dependent on the quality of the training data, emphasizing the mutual dependence of data availability and technological progress. This paper introduces an end-to-end tool to generate high-quality datasets for text-to-speech (TTS) models to address this critical need for high-quality data. The contributions of this work are manifold and include: the integration of language-specific phoneme distribution into sample selection, automation of the recording process, automated and human-in-the-loop quality assurance of recordings, and processing of recordings to meet specified formats. The proposed application aims to streamline the dataset creation process for TTS models through these features, thereby facilitating advancements in voice-based technologies.
A Reference-less Quality Metric for Automatic Speech Recognition via Contrastive-Learning of a Multi-Language Model with Self-Supervision
Jun 21, 2023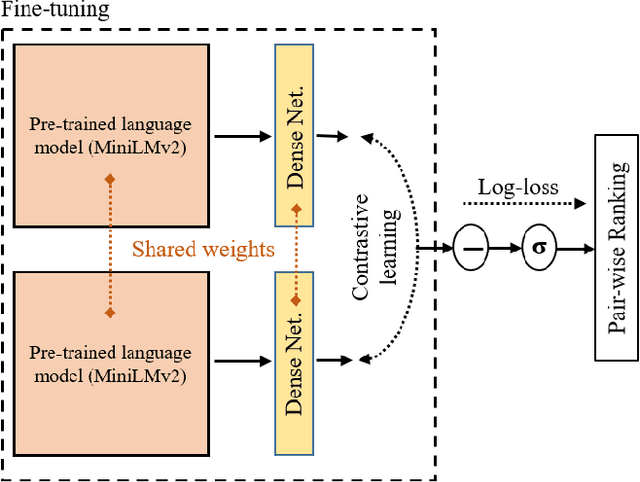
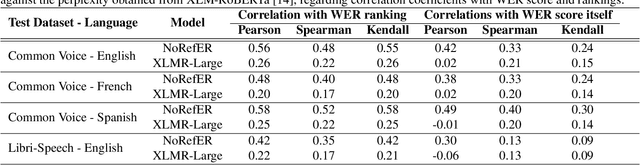
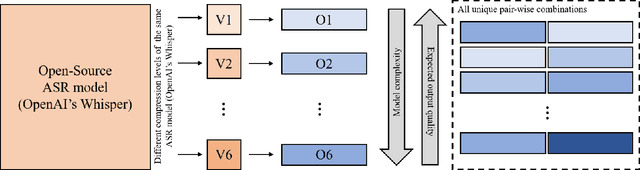
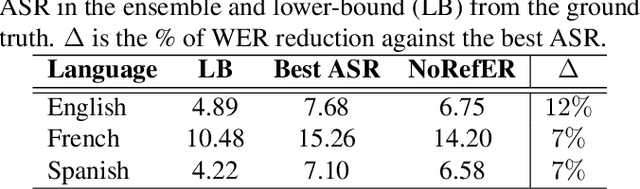
The common standard for quality evaluation of automatic speech recognition (ASR) systems is reference-based metrics such as the Word Error Rate (WER), computed using manual ground-truth transcriptions that are time-consuming and expensive to obtain. This work proposes a multi-language referenceless quality metric, which allows comparing the performance of different ASR models on a speech dataset without ground truth transcriptions. To estimate the quality of ASR hypotheses, a pre-trained language model (LM) is fine-tuned with contrastive learning in a self-supervised learning manner. In experiments conducted on several unseen test datasets consisting of outputs from top commercial ASR engines in various languages, the proposed referenceless metric obtains a much higher correlation with WER scores and their ranks than the perplexity metric from the state-of-art multi-lingual LM in all experiments, and also reduces WER by more than $7\%$ when used for ensembling hypotheses. The fine-tuned model and experiments are made available for the reproducibility: https://github.com/aixplain/NoRefER
NoRefER: a Referenceless Quality Metric for Automatic Speech Recognition via Semi-Supervised Language Model Fine-Tuning with Contrastive Learning
Jun 21, 2023This paper introduces NoRefER, a novel referenceless quality metric for automatic speech recognition (ASR) systems. Traditional reference-based metrics for evaluating ASR systems require costly ground-truth transcripts. NoRefER overcomes this limitation by fine-tuning a multilingual language model for pair-wise ranking ASR hypotheses using contrastive learning with Siamese network architecture. The self-supervised NoRefER exploits the known quality relationships between hypotheses from multiple compression levels of an ASR for learning to rank intra-sample hypotheses by quality, which is essential for model comparisons. The semi-supervised version also uses a referenced dataset to improve its inter-sample quality ranking, which is crucial for selecting potentially erroneous samples. The results indicate that NoRefER correlates highly with reference-based metrics and their intra-sample ranks, indicating a high potential for referenceless ASR evaluation or a/b testing.
EvolveMT: an Ensemble MT Engine Improving Itself with Usage Only
Jun 20, 2023This paper presents EvolveMT for efficiently combining multiple machine translation (MT) engines. The proposed system selects the output from a single engine for each segment by utilizing online learning techniques to predict the most suitable system for every translation request. A neural quality estimation metric supervises the method without requiring reference translations. The online learning capability of this system allows for dynamic adaptation to alterations in the domain or machine translation engines, thereby obviating the necessity for additional training. EvolveMT selects a subset of translation engines to be called based on the source sentence features. The degree of exploration is configurable according to the desired quality-cost trade-off. Results from custom datasets demonstrate that EvolveMT achieves similar translation accuracy at a lower cost than selecting the best translation of each segment from all translations using an MT quality estimator. To our knowledge, EvolveMT is the first meta MT system that adapts itself after deployment to incoming translation requests from the production environment without needing costly retraining on human feedback.
Efficient Machine Translation Corpus Generation
Jun 20, 2023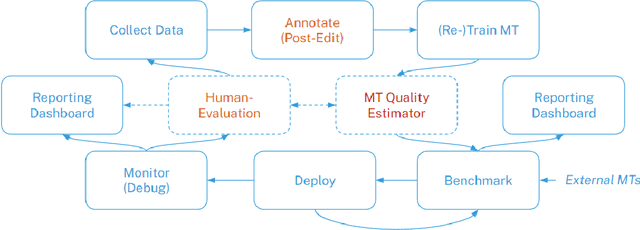
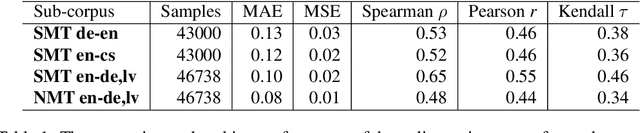
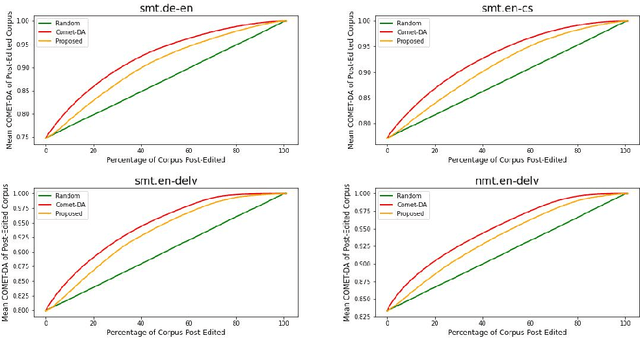
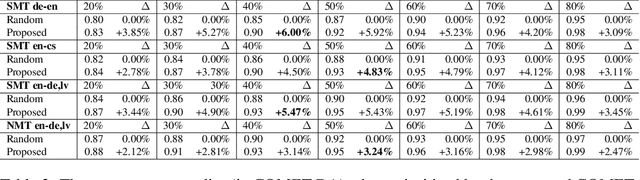
This paper proposes an efficient and semi-automated method for human-in-the-loop post-editing for machine translation (MT) corpus generation. The method is based on online training of a custom MT quality estimation metric on-the-fly as linguists perform post-edits. The online estimator is used to prioritize worse hypotheses for post-editing, and auto-close best hypotheses without post-editing. This way, significant improvements can be achieved in the resulting quality of post-edits at a lower cost due to reduced human involvement. The trained estimator can also provide an online sanity check mechanism for post-edits and remove the need for additional linguists to review them or work on the same hypotheses. In this paper, the effect of prioritizing with the proposed method on the resulting MT corpus quality is presented versus scheduling hypotheses randomly. As demonstrated by experiments, the proposed method improves the lifecycle of MT models by focusing the linguist effort on production samples and hypotheses, which matter most for expanding MT corpora to be used for re-training them.
Resource Efficient 3D Convolutional Neural Networks
Apr 27, 2019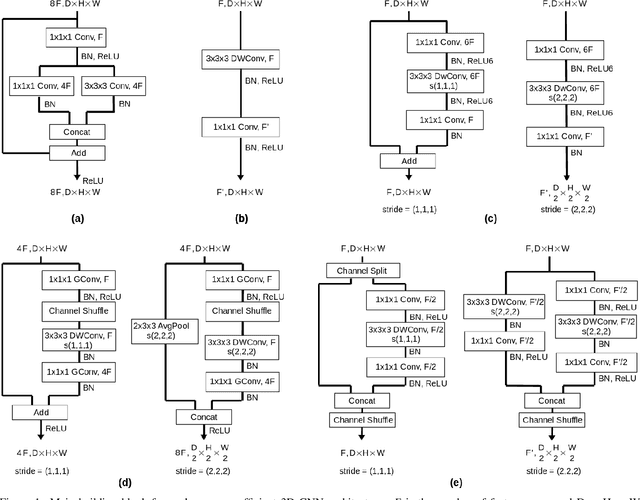
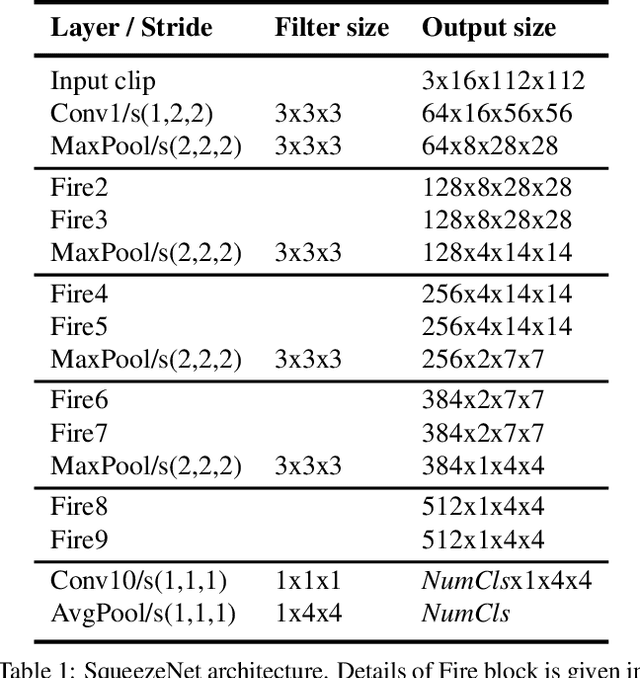

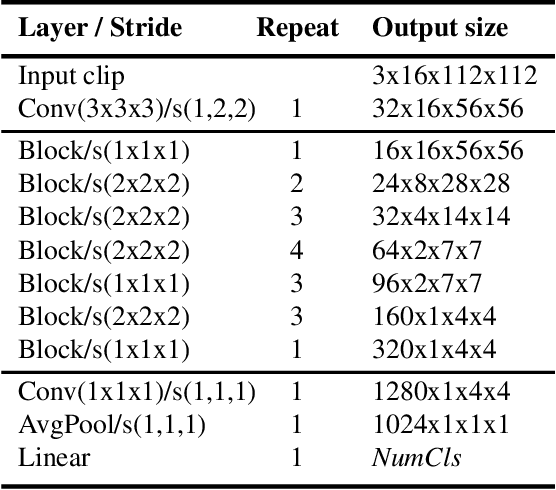
Recently, convolutional neural networks with 3D kernels (3D CNNs) have been very popular in computer vision community as a result of their superior ability of extracting spatio-temporal features within video frames compared to 2D CNNs. Although, there has been great advances recently to build resource efficient 2D CNN architectures considering memory and power budget, there is hardly any similar resource efficient architectures for 3D CNNs. In this paper, we have converted various well-known resource efficient 2D CNNs to 3D CNNs and evaluated their performance on three major benchmarks in terms of classification accuracy for different complexity levels. We have experimented on (1) Kinetics-600 dataset to inspect their capacity to learn, (2) Jester dataset to inspect their ability to capture hand motion patterns, and (3) UCF-101 to inspect the applicability of transfer learning. We have evaluated the run-time performance of each model on a single GPU and an embedded GPU. The results of this study show that these models can be utilized for different types of real-world applications since they provide real-time performance with considerable accuracies and memory usage. Our analysis on different complexity levels shows that the resource efficient 3D CNNs should not be designed too shallow or narrow in order to save complexity. The codes and pretrained models used in this work are publicly available.
Real-time Hand Gesture Detection and Classification Using Convolutional Neural Networks
Feb 05, 2019


Real-time recognition of dynamic hand gestures from video streams is a challenging task since (i) there is no indication when a gesture starts and ends in the video, (ii) performed gestures should only be recognized once, and (iii) the entire architecture should be designed considering the memory and power budget. In this work, we address these challenges by proposing a hierarchical structure enabling offline-working convolutional neural network (CNN) architectures to operate online efficiently by using sliding window approach. The proposed architecture consists of two models: (1) A detector which is a lightweight CNN architecture to detect gestures and (2) a classifier which is a deep CNN to classify the detected gestures. In order to evaluate the single-time activations of the detected gestures, we propose to use Levenshtein distance as an evaluation metric since it can measure misclassifications, multiple detections, and missing detections at the same time. We evaluate our architecture on two publicly available datasets - EgoGesture and NVIDIA Dynamic Hand Gesture Datasets - which require temporal detection and classification of the performed hand gestures. ResNeXt-101 model, which is used as a classifier, achieves the state-of-the-art offline classification accuracy of 94.04% and 83.82% for depth modality on EgoGesture and NVIDIA benchmarks, respectively. In real-time detection and classification, we obtain considerable early detections while achieving performances close to offline operation. The codes and pretrained models used in this work are publicly available.