 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEA: Revisiting anchor-based object detection DNN using Budding Ensemble Architecture
Sep 19, 2023



This paper introduces the Budding Ensemble Architecture (BEA), a novel reduced ensemble architecture for anchor-based object detection models. Object detection models are crucial in vision-based tasks, particularly in autonomous systems. They should provide precise bounding box detections while also calibrating their predicted confidence scores, leading to higher-quality uncertainty estimates. However, current models may make erroneous decisions due to false positives receiving high scores or true positives being discarded due to low scores. BEA aims to address these issues. The proposed loss functions in BEA improve the confidence score calibration and lower the uncertainty error, which results in a better distinction of true and false positives and, eventually, higher accuracy of the object detection models. Both Base-YOLOv3 and SSD models were enhanced using the BEA method and its proposed loss functions. The BEA on Base-YOLOv3 trained on the KITTI dataset results in a 6% and 3.7% increase in mAP and AP50, respectively. Utilizing a well-balanced uncertainty estimation threshold to discard samples in real-time even leads to a 9.6% higher AP50 than its base model. This is attributed to a 40% increase in the area under the AP50-based retention curve used to measure the quality of calibration of confidence scores. Furthermore, BEA-YOLOV3 trained on KITTI provides superior out-of-distribution detection on Citypersons, BDD100K, and COCO datasets compared to the ensembles and vanilla models of YOLOv3 and Gaussian-YOLOv3.
Reliable Multimodal Trajectory Prediction via Error Aligned Uncertainty Optimization
Dec 09, 2022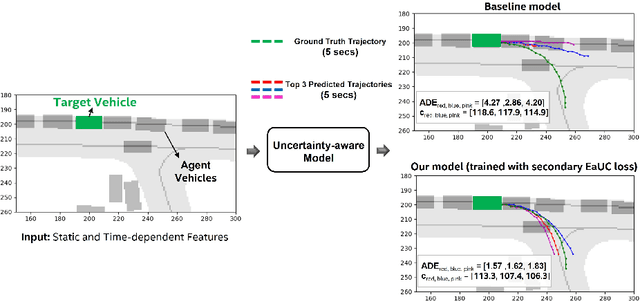
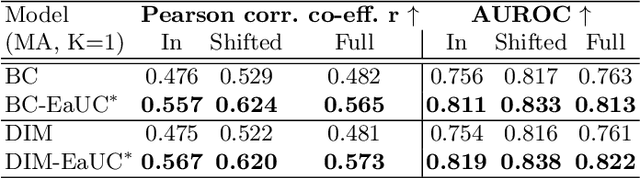
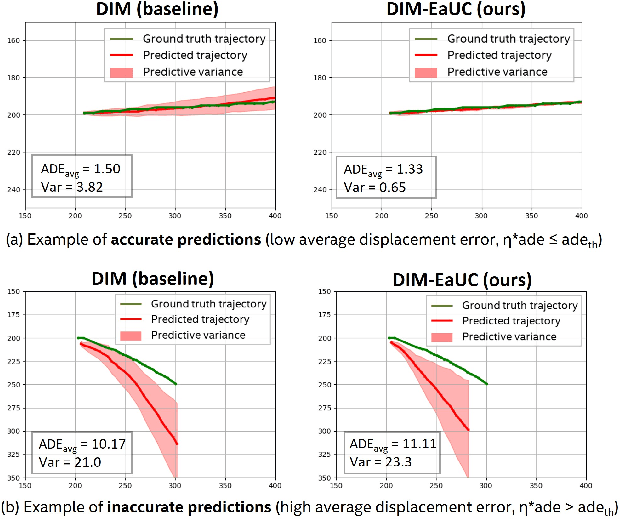

Reliable uncertainty quantification in deep neural networks is very crucial in safety-critical applications such as automated driving for trustworthy and informed decision-making. Assessing the quality of uncertainty estimates is challenging as ground truth for uncertainty estimates is not available. Ideally, in a well-calibrated model, uncertainty estimates should perfectly correlate with model error. We propose a novel error aligned uncertainty optimization method and introduce a trainable loss function to guide the models to yield good quality uncertainty estimates aligning with the model error. Our approach targets continuous structured prediction and regression tasks, and is evaluated on multiple datasets including a large-scale vehicle motion prediction task involving real-world distributional shifts. We demonstrate that our method improves average displacement error by 1.69% and 4.69%, and the uncertainty correlation with model error by 17.22% and 19.13% as quantified by Pearson correlation coefficient on two state-of-the-art baselines.
DMD: A Large-Scale Multi-Modal Driver Monitoring Dataset for Attention and Alertness Analysis
Aug 27, 2020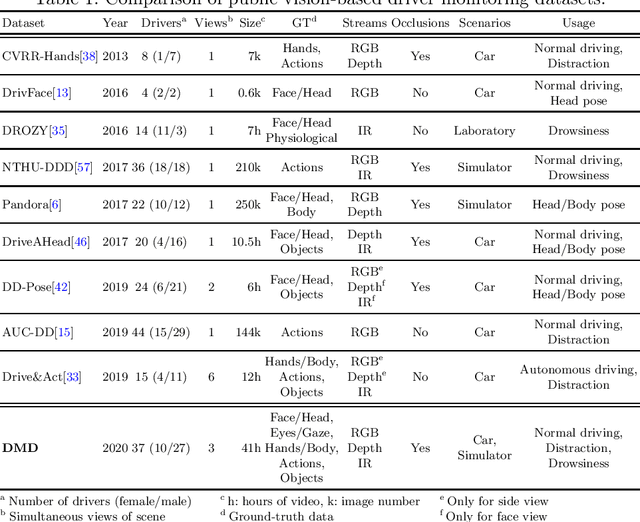
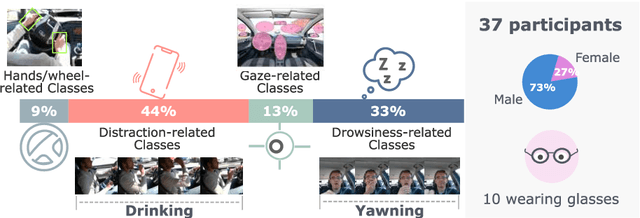
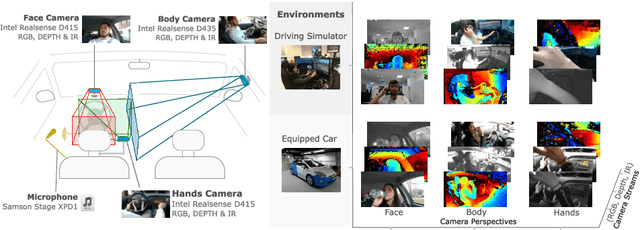

Vision is the richest and most cost-effective technology for Driver Monitoring Systems (DMS), especially after the recent success of Deep Learning (DL) methods. The lack of sufficiently large and comprehensive datasets is currently a bottleneck for the progress of DMS development, crucial for the transition of automated driving from SAE Level-2 to SAE Level-3. In this paper, we introduce the Driver Monitoring Dataset (DMD), an extensive dataset which includes real and simulated driving scenarios: distraction, gaze allocation, drowsiness, hands-wheel interaction and context data, in 41 hours of RGB, depth and IR videos from 3 cameras capturing face, body and hands of 37 drivers. A comparison with existing similar datasets is included, which shows the DMD is more extensive, diverse, and multi-purpose. The usage of the DMD is illustrated by extracting a subset of it, the dBehaviourMD dataset, containing 13 distraction activities, prepared to be used in DL training processes. Furthermore, we propose a robust and real-time driver behaviour recognition system targeting a real-world application that can run on cost-efficient CPU-only platforms, based on the dBehaviourMD. Its performance is evaluated with different types of fusion strategies, which all reach enhanced accuracy still providing real-time response.
DriverMHG: A Multi-Modal Dataset for Dynamic Recognition of Driver Micro Hand Gestures and a Real-Time Recognition Framework
Mar 02, 2020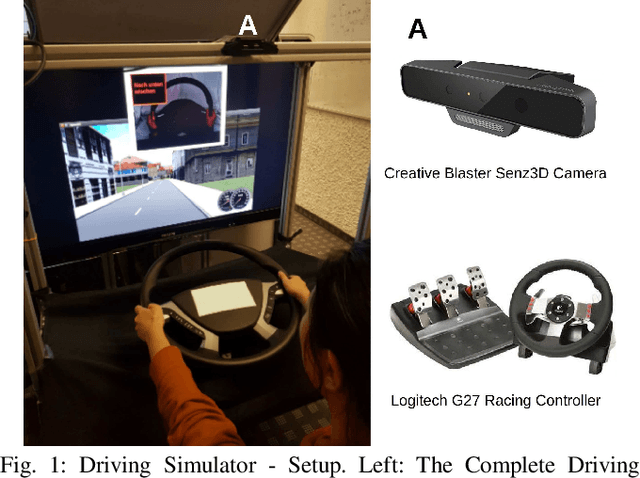



The use of hand gestures provides a natural alternative to cumbersome interface devices for Human-Computer Interaction (HCI) systems. However, real-time recognition of dynamic micro hand gestures from video streams is challenging for in-vehicle scenarios since (i) the gestures should be performed naturally without distracting the driver, (ii) micro hand gestures occur within very short time intervals at spatially constrained areas, (iii) the performed gesture should be recognized only once, and (iv) the entire architecture should be designed lightweight as it will be deployed to an embedded system. In this work, we propose an HCI system for dynamic recognition of driver micro hand gestures, which can have a crucial impact in automotive sector especially for safety related issues. For this purpose, we initially collected a dataset named Driver Micro Hand Gestures (DriverMHG), which consists of RGB, depth and infrared modalities. The challenges for dynamic recognition of micro hand gestures have been addressed by proposing a lightweight convolutional neural network (CNN) based architecture which operates online efficiently with a sliding window approach. For the CNN model, several 3-dimensional resource efficient networks are applied and their performances are analyzed. Online recognition of gestures has been performed with 3D-MobileNetV2, which provided the best offline accuracy among the applied networks with similar computational complexities. The final architecture is deployed on a driver simulator operating in real-time. We make DriverMHG dataset and our source code publicly available.
Real-Time Driver State Monitoring Using a CNN Based Spatio-Temporal Approach
Jul 18, 2019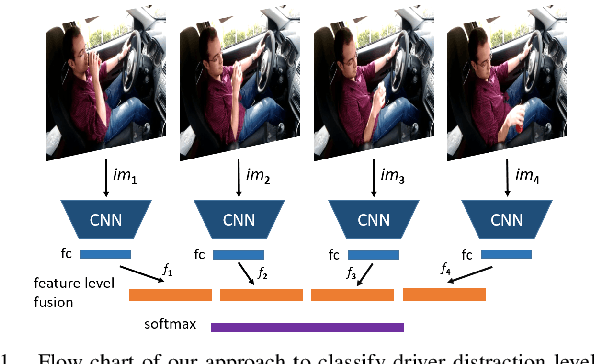


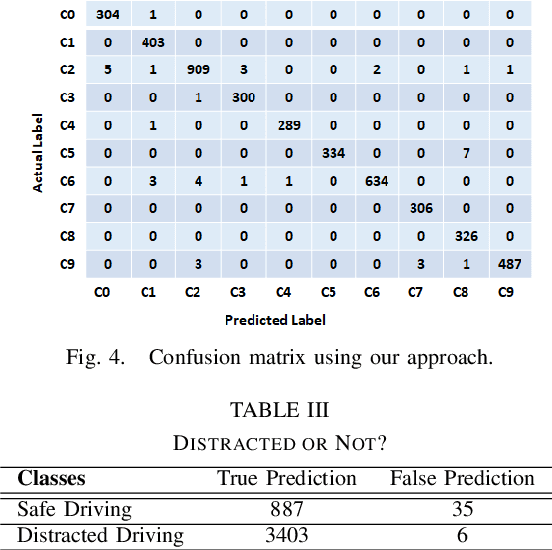
Many road accidents occur due to distracted drivers. Today, driver monitoring is essential even for the latest autonomous vehicles to alert distracted drivers in order to take over control of the vehicle in case of emergency. In this paper, a spatio-temporal approach is applied to classify drivers' distraction level and movement decisions using convolutional neural networks (CNNs). We approach this problem as action recognition to benefit from temporal information in addition to spatial information. Our approach relies on features extracted from sparsely selected frames of an action using a pre-trained BN-Inception network. Experiments show that our approach outperforms the state-of-the art results on the Distracted Driver Dataset (96.31%), with an accuracy of 99.10% for 10-class classification while providing real-time performance. We also analyzed the impact of fusion using RGB and optical flow modalities with a very recent data level fusion strategy. The results on the Distracted Driver and Brain4Cars datasets show that fusion of these modalities further increases the accuracy.
Resource Efficient 3D Convolutional Neural Networks
Apr 27, 2019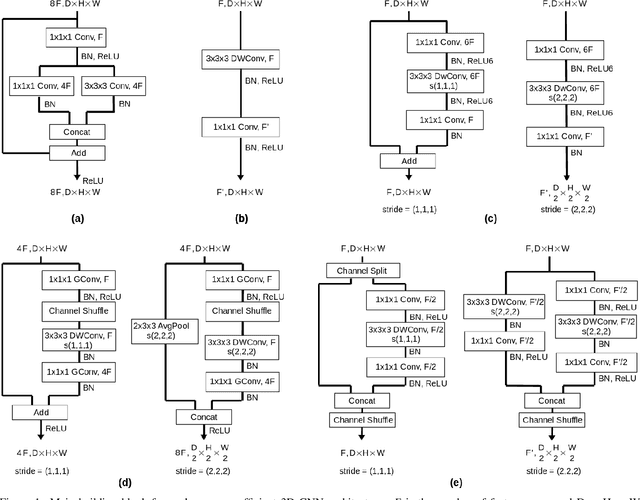
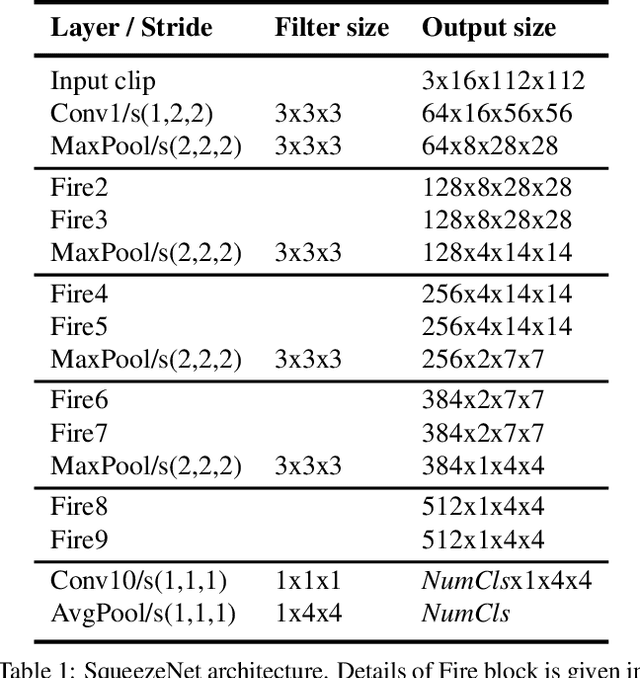

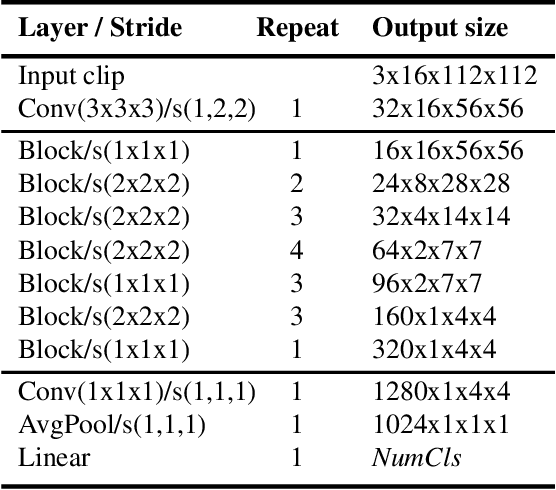
Recently, convolutional neural networks with 3D kernels (3D CNNs) have been very popular in computer vision community as a result of their superior ability of extracting spatio-temporal features within video frames compared to 2D CNNs. Although, there has been great advances recently to build resource efficient 2D CNN architectures considering memory and power budget, there is hardly any similar resource efficient architectures for 3D CNNs. In this paper, we have converted various well-known resource efficient 2D CNNs to 3D CNNs and evaluated their performance on three major benchmarks in terms of classification accuracy for different complexity levels. We have experimented on (1) Kinetics-600 dataset to inspect their capacity to learn, (2) Jester dataset to inspect their ability to capture hand motion patterns, and (3) UCF-101 to inspect the applicability of transfer learning. We have evaluated the run-time performance of each model on a single GPU and an embedded GPU. The results of this study show that these models can be utilized for different types of real-world applications since they provide real-time performance with considerable accuracies and memory usage. Our analysis on different complexity levels shows that the resource efficient 3D CNNs should not be designed too shallow or narrow in order to save complexity. The codes and pretrained models used in this work are publicly available.
Real-time Hand Gesture Detection and Classification Using Convolutional Neural Networks
Feb 05, 2019


Real-time recognition of dynamic hand gestures from video streams is a challenging task since (i) there is no indication when a gesture starts and ends in the video, (ii) performed gestures should only be recognized once, and (iii) the entire architecture should be designed considering the memory and power budget. In this work, we address these challenges by proposing a hierarchical structure enabling offline-working convolutional neural network (CNN) architectures to operate online efficiently by using sliding window approach. The proposed architecture consists of two models: (1) A detector which is a lightweight CNN architecture to detect gestures and (2) a classifier which is a deep CNN to classify the detected gestures. In order to evaluate the single-time activations of the detected gestures, we propose to use Levenshtein distance as an evaluation metric since it can measure misclassifications, multiple detections, and missing detections at the same time. We evaluate our architecture on two publicly available datasets - EgoGesture and NVIDIA Dynamic Hand Gesture Datasets - which require temporal detection and classification of the performed hand gestures. ResNeXt-101 model, which is used as a classifier, achieves the state-of-the-art offline classification accuracy of 94.04% and 83.82% for depth modality on EgoGesture and NVIDIA benchmarks, respectively. In real-time detection and classification, we obtain considerable early detections while achieving performances close to offline operation. The codes and pretrained models used in this work are publicly available.