 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification for Computer-Use Agents: A Benchmark across Vision-Language Models and GUI Grounding Datasets
Jun 24, 2026Computer-use agents turn vision-language model (VLM) predictions into executable GUI clicks, so reliable uncertainty estimates are essential for rejection, calibration, miss-severity ranking, and spatial safety regions. Yet evidence on post-hoc uncertainty quantification (UQ) for these agents is fragmented across isolated model and dataset pairs, leaving it unclear whether UQ rankings stay stable when the agent, benchmark, or observable interface changes. We present Argus, a cross-regime benchmark for post-hoc UQ in single-step executable GUI grounding: a 27-method open-weight matrix over 4 VLM agents and 4 datasets, plus an 8-method closed-source matrix across 3 frontier vendors where logits, hidden states, and attention maps are unavailable. Evaluated methods span logit-based scores, sampling and consistency measures, hidden-state and density estimators (Mahalanobis, SAPLMA), attention-based scores, P(True) and verbalised-confidence prompting, and split-conformal prediction. The main finding is selective transfer: UQ rankings are stable across datasets for a fixed model, but degrade across model classes and observable interfaces. Hidden-state and density methods are the most stable open-weight family, while CoCoA-1MCA, Focus, sampling-based scores, and verbalised self-assessment win in specific regimes. Within-model ranking transfer is strong (Spearman rho up to 0.969), but cross-tier transfer to closed-source vendors averages only +0.08, so closed-source UQ should be reranked on the target rather than extrapolated. Conformal click regions show score-level discrimination is not enough for deployment: locally weighted disks shrink radii by 40-60% when the plug-in UQ is calibrated, but coverage degrades under calibration-test or interface mismatch. We release per-item records, calibration/test splits, UQ scores, and analysis scripts for regime-aware UQ selection in GUI agents.
Synthetic Data Generation for Long-Tail Medical Image Classification: A Case Study in Skin Lesions
May 04, 2026Long-tailed class distributions are pervasive in multi-class medical datasets and pose significant challenges for deep learning models which typically underperform on tail classes with limited samples. This limitation is particularly problematic in medical applications, where rare classes often correspond to severe or high-risk diseases and therefore require high diagnostic accuracy. Existing solutions-including specialized architectures, rebalanced loss functions, and handcrafted data augmentation-offer only marginal improvements and struggle to scale due to their limited and largely deterministic variability. To address these challenges, we introduce a diffusion-model-driven synthetic data augmentation pipeline tailored for medical long-tailed classification. Our approach features a novel inpainting diffusion model combined with an Out-of-Distribution (OOD) post-selection mechanism to ensure diverse, realistic, and clinically meaningful synthetic samples. Evaluated on the ISIC2019 skin lesion classification dataset, one of the largest and most imbalanced medical imaging benchmarks, our method yields substantial improvements in overall performance, with particularly pronounced gains on tail classes with more than $28\%$ improvement on the class with the fewest samples. These results demonstrate the effectiveness of diffusion-based augmentation in mitigating long-tail imbalance and enhancing medical classification robustness.
PEFA-AI: Advancing Open-source LLMs for RTL generation using Progressive Error Feedback Agentic-AI
Nov 06, 2025We present an agentic flow consisting of multiple agents that combine specialized LLMs and hardware simulation tools to collaboratively complete the complex task of Register Transfer Level (RTL) generation without human intervention. A key feature of the proposed flow is the progressive error feedback system of agents (PEFA), a self-correcting mechanism that leverages iterative error feedback to progressively increase the complexity of the approach. The generated RTL includes checks for compilation, functional correctness, and synthesizable constructs. To validate this adaptive approach to code generation, benchmarking is performed using two opensource natural language-to-RTL datasets. We demonstrate the benefits of the proposed approach implemented on an open source agentic framework, using both open- and closed-source LLMs, effectively bridging the performance gap between them. Compared to previously published methods, our approach sets a new benchmark, providing state-of-the-art pass rates while being efficient in token counts.
Windsock is Dancing: Adaptive Multimodal Retrieval-Augmented Generation
Oct 26, 2025Multimodal Retrieval-Augmented Generation (MRAG) has emerged as a promising method to generate factual and up-to-date responses of Multimodal Large Language Models (MLLMs) by incorporating non-parametric knowledge from external knowledge bases. However, existing MRAG approaches suffer from static retrieval strategies, inflexible modality selection, and suboptimal utilization of retrieved information, leading to three critical challenges: determining when to retrieve, what modality to incorporate, and how to utilize retrieved information effectively. To address these challenges, we introduce Windsock, a query-dependent module making decisions on retrieval necessity and modality selection, effectively reducing computational overhead and improving response quality. Additionally, we propose Dynamic Noise-Resistance (DANCE) Instruction Tuning, an adaptive training strategy that enhances MLLMs' ability to utilize retrieved information while maintaining robustness against noise. Moreover, we adopt a self-assessment approach leveraging knowledge within MLLMs to convert question-answering datasets to MRAG training datasets. Extensive experiments demonstrate that our proposed method significantly improves the generation quality by 17.07% while reducing 8.95% retrieval times.
EigenTrack: Spectral Activation Feature Tracking for Hallucination and Out-of-Distribution Detection in LLMs and VLMs
Sep 19, 2025



Large language models (LLMs) offer broad utility but remain prone to hallucination and out-of-distribution (OOD) errors. We propose EigenTrack, an interpretable real-time detector that uses the spectral geometry of hidden activations, a compact global signature of model dynamics. By streaming covariance-spectrum statistics such as entropy, eigenvalue gaps, and KL divergence from random baselines into a lightweight recurrent classifier, EigenTrack tracks temporal shifts in representation structure that signal hallucination and OOD drift before surface errors appear. Unlike black- and grey-box methods, it needs only a single forward pass without resampling. Unlike existing white-box detectors, it preserves temporal context, aggregates global signals, and offers interpretable accuracy-latency trade-offs.
Uncertainty Quantification in Continual Open-World Learning
Dec 21, 2024



AI deployed in the real-world should be capable of autonomously adapting to novelties encountered after deployment. Yet, in the field of continual learning, the reliance on novelty and labeling oracles is commonplace albeit unrealistic. This paper addresses a challenging and under-explored problem: a deployed AI agent that continuously encounters unlabeled data - which may include both unseen samples of known classes and samples from novel (unknown) classes - and must adapt to it continuously. To tackle this challenge, we propose our method COUQ "Continual Open-world Uncertainty Quantification", an iterative uncertainty estimation algorithm tailored for learning in generalized continual open-world multi-class settings. We rigorously apply and evaluate COUQ on key sub-tasks in the Continual Open-World: continual novelty detection, uncertainty guided active learning, and uncertainty guided pseudo-labeling for semi-supervised CL. We demonstrate the effectiveness of our method across multiple datasets, ablations, backbones and performance superior to state-of-the-art.
CONCLAD: COntinuous Novel CLAss Detector
Dec 13, 2024


In the field of continual learning, relying on so-called oracles for novelty detection is commonplace albeit unrealistic. This paper introduces CONCLAD ("COntinuous Novel CLAss Detector"), a comprehensive solution to the under-explored problem of continual novel class detection in post-deployment data. At each new task, our approach employs an iterative uncertainty estimation algorithm to differentiate between known and novel class(es) samples, and to further discriminate between the different novel classes themselves. Samples predicted to be from a novel class with high-confidence are automatically pseudo-labeled and used to update our model. Simultaneously, a tiny supervision budget is used to iteratively query ambiguous novel class predictions, which are also used during update. Evaluation across multiple datasets, ablations and experimental settings demonstrate our method's effectiveness at separating novel and old class samples continuously. We will release our code upon acceptance.
CUAL: Continual Uncertainty-aware Active Learner
Dec 12, 2024



AI deployed in many real-world use cases should be capable of adapting to novelties encountered after deployment. Here, we consider a challenging, under-explored and realistic continual adaptation problem: a deployed AI agent is continuously provided with unlabeled data that may contain not only unseen samples of known classes but also samples from novel (unknown) classes. In such a challenging setting, it has only a tiny labeling budget to query the most informative samples to help it continuously learn. We present a comprehensive solution to this complex problem with our model "CUAL" (Continual Uncertainty-aware Active Learner). CUAL leverages an uncertainty estimation algorithm to prioritize active labeling of ambiguous (uncertain) predicted novel class samples while also simultaneously pseudo-labeling the most certain predictions of each class. Evaluations across multiple datasets, ablations, settings and backbones (e.g. ViT foundation model) demonstrate our method's effectiveness. We will release our code upon acceptance.
Enhancing Trust in Large Language Models with Uncertainty-Aware Fine-Tuning
Dec 03, 2024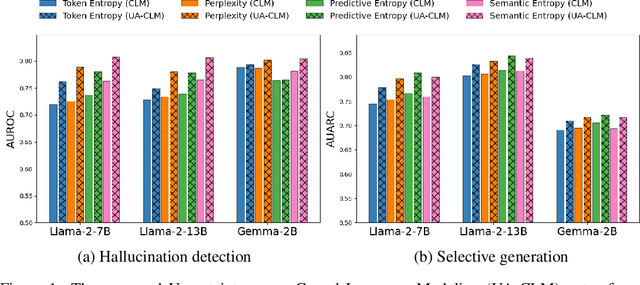
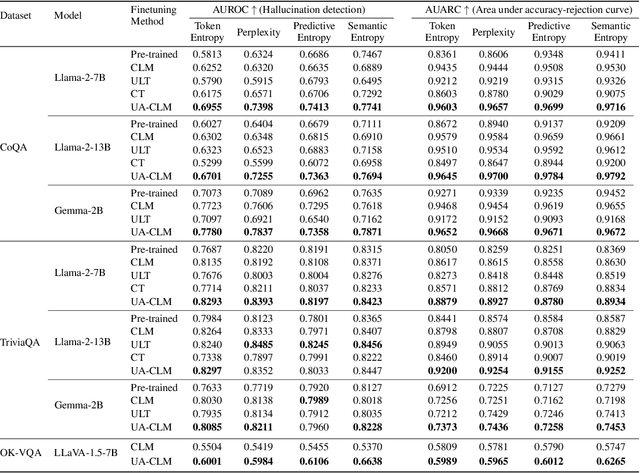

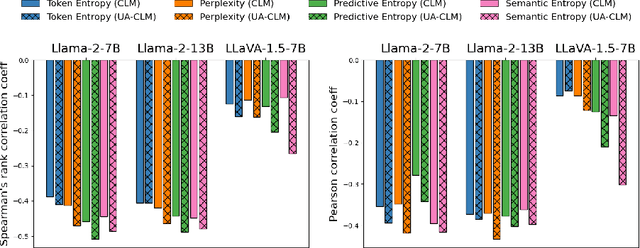
Large language models (LLMs) have revolutionized the field of natural language processing with their impressive reasoning and question-answering capabilities. However, these models are sometimes prone to generating credible-sounding but incorrect information, a phenomenon known as LLM hallucinations. Reliable uncertainty estimation in LLMs is essential for fostering trust in their generated responses and serves as a critical tool for the detection and prevention of erroneous or hallucinated outputs. To achieve reliable and well-calibrated uncertainty quantification in open-ended and free-form natural language generation, we propose an uncertainty-aware fine-tuning approach for LLMs. This approach enhances the model's ability to provide reliable uncertainty estimates without compromising accuracy, thereby guiding them to produce more trustworthy responses. We introduce a novel uncertainty-aware causal language modeling loss function, grounded in the principles of decision theory. Through rigorous evaluation on multiple free-form question-answering datasets and models, we demonstrate that our uncertainty-aware fine-tuning approach yields better calibrated uncertainty estimates in natural language generation tasks than fine-tuning with the standard causal language modeling loss. Furthermore, the experimental results show that the proposed method significantly improves the model's ability to detect hallucinations and identify out-of-domain prompts.
Rate-Distortion Theory in Coding for Machines and its Application
May 26, 2023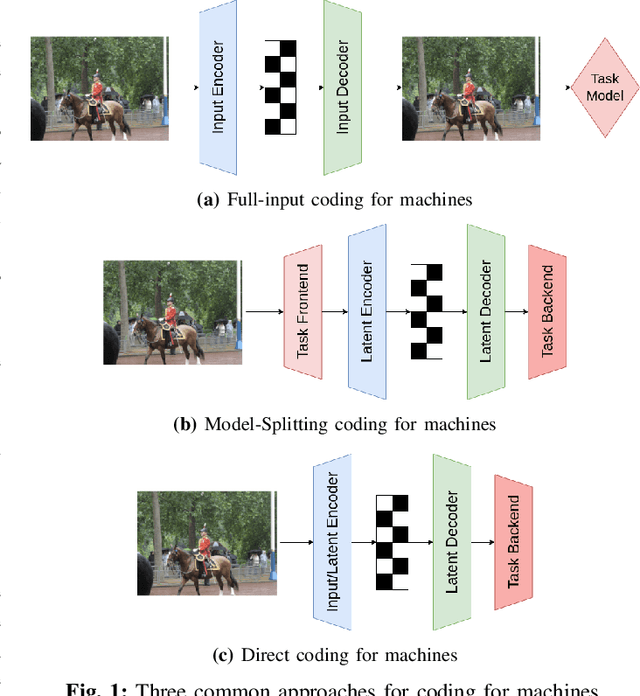
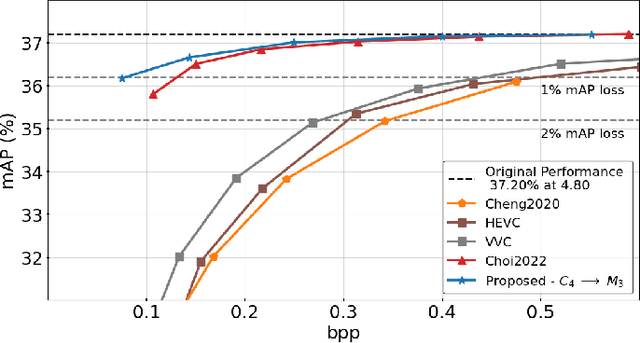
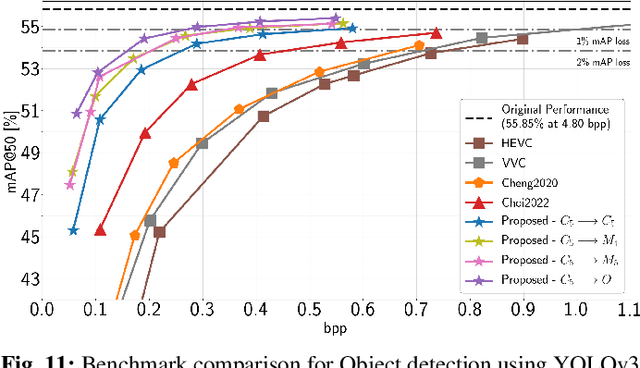
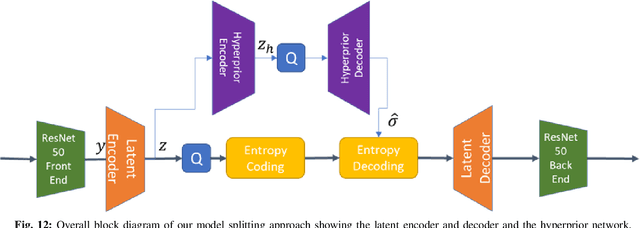
Recent years have seen a tremendous growth in both the capability and popularity of automatic machine analysis of images and video. As a result, a growing need for efficient compression methods optimized for machine vision, rather than human vision, has emerged. To meet this growing demand, several methods have been developed for image and video coding for machines. Unfortunately, while there is a substantial body of knowledge regarding rate-distortion theory for human vision, the same cannot be said of machine analysis. In this paper, we extend the current rate-distortion theory for machines, providing insight into important design considerations of machine-vision codecs. We then utilize this newfound understanding to improve several methods for learnable image coding for machines. Our proposed methods achieve state-of-the-art rate-distortion performance on several computer vision tasks such as classification, instance segmentation, and object detection.