 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Trust in Large Language Models with Uncertainty-Aware Fine-Tuning
Paper and Code
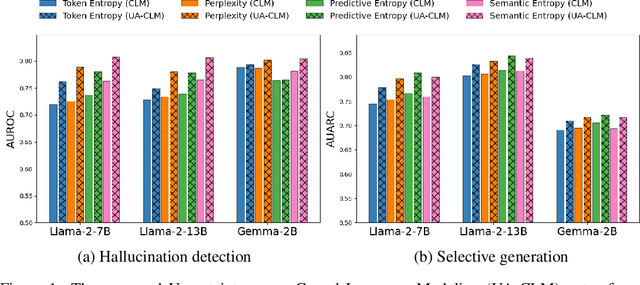
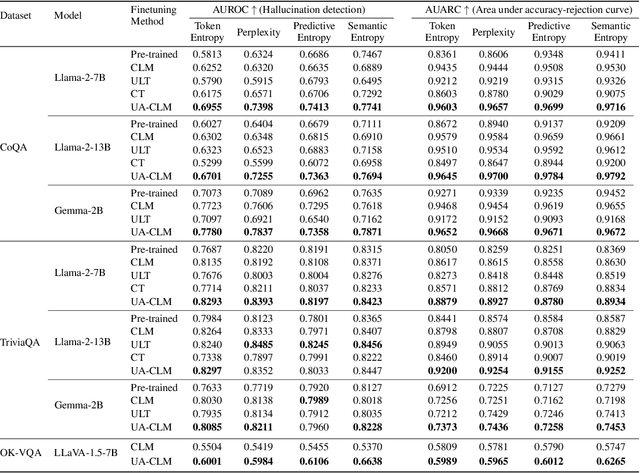

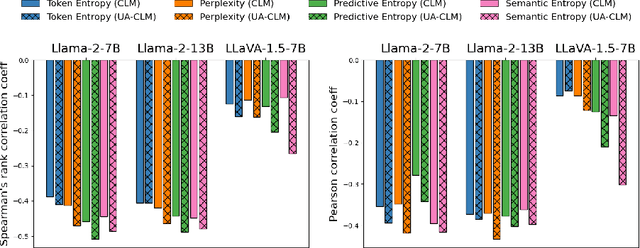
Large language models (LLMs) have revolutionized the field of natural language processing with their impressive reasoning and question-answering capabilities. However, these models are sometimes prone to generating credible-sounding but incorrect information, a phenomenon known as LLM hallucinations. Reliable uncertainty estimation in LLMs is essential for fostering trust in their generated responses and serves as a critical tool for the detection and prevention of erroneous or hallucinated outputs. To achieve reliable and well-calibrated uncertainty quantification in open-ended and free-form natural language generation, we propose an uncertainty-aware fine-tuning approach for LLMs. This approach enhances the model's ability to provide reliable uncertainty estimates without compromising accuracy, thereby guiding them to produce more trustworthy responses. We introduce a novel uncertainty-aware causal language modeling loss function, grounded in the principles of decision theory. Through rigorous evaluation on multiple free-form question-answering datasets and models, we demonstrate that our uncertainty-aware fine-tuning approach yields better calibrated uncertainty estimates in natural language generation tasks than fine-tuning with the standard causal language modeling loss. Furthermore, the experimental results show that the proposed method significantly improves the model's ability to detect hallucinations and identify out-of-domain prompts.