 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACER: Trajectory Risk Aggregation for Critical Episodes in Agentic Reasoning
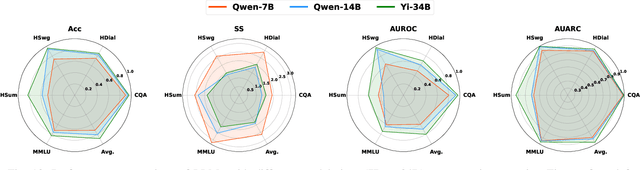
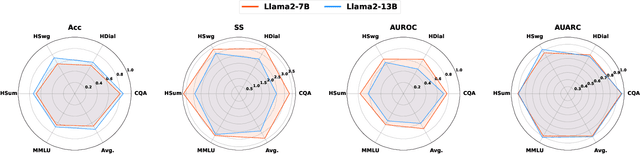
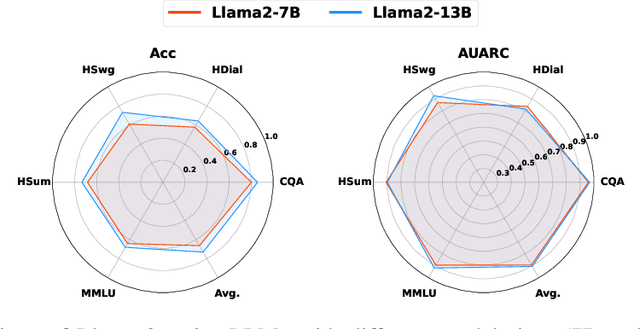
Feb 11, 2026Estimating uncertainty for AI agents in real-world multi-turn tool-using interaction with humans is difficult because failures are often triggered by sparse critical episodes (e.g., looping, incoherent tool use, or user-agent miscoordination) even when local generation appears confident. Existing uncertainty proxies focus on single-shot text generation and therefore miss these trajectory-level breakdown signals. We introduce TRACER, a trajectory-level uncertainty metric for dual-control Tool-Agent-User interaction. TRACER combines content-aware surprisal with situational-awareness signals, semantic and lexical repetition, and tool-grounded coherence gaps, and aggregates them using a tail-focused risk functional with a MAX-composite step risk to surface decisive anomalies. We evaluate TRACER on $τ^2$-bench by predicting task failure and selective task execution. To this end, TRACER improves AUROC by up to 37.1% and AUARC by up to 55% over baselines, enabling earlier and more accurate detection of uncertainty in complex conversational tool-use settings. Our code and benchmark are available at https://github.com/sinatayebati/agent-tracer.
Learnable Conformal Prediction with Context-Aware Nonconformity Functions for Robotic Planning and Perception
Sep 26, 2025Deep learning models in robotics often output point estimates with poorly calibrated confidences, offering no native mechanism to quantify predictive reliability under novel, noisy, or out-of-distribution inputs. Conformal prediction (CP) addresses this gap by providing distribution-free coverage guarantees, yet its reliance on fixed nonconformity scores ignores context and can yield intervals that are overly conservative or unsafe. We address this with Learnable Conformal Prediction (LCP), which replaces fixed scores with a lightweight neural function that leverages geometric, semantic, and task-specific features to produce context-aware uncertainty sets. LCP maintains CP's theoretical guarantees while reducing prediction set sizes by 18% in classification, tightening detection intervals by 52%, and improving path planning safety from 72% to 91% success with minimal overhead. Across three robotic tasks on seven benchmarks, LCP consistently outperforms Standard CP and ensemble baselines. In classification on CIFAR-100 and ImageNet, it achieves smaller set sizes (4.7-9.9% reduction) at target coverage. For object detection on COCO, BDD100K, and Cityscapes, it produces 46-54% tighter bounding boxes. In path planning through cluttered environments, it improves success to 91.5% with only 4.5% path inflation, compared to 12.2% for Standard CP. The method is lightweight (approximately 4.8% runtime overhead, 42 KB memory) and supports online adaptation, making it well suited to resource-constrained autonomous systems. Hardware evaluation shows LCP adds less than 1% memory and 15.9% inference overhead, yet sustains 39 FPS on detection tasks while being 7.4 times more energy-efficient than ensembles.
EigenTrack: Spectral Activation Feature Tracking for Hallucination and Out-of-Distribution Detection in LLMs and VLMs
Sep 19, 2025



Large language models (LLMs) offer broad utility but remain prone to hallucination and out-of-distribution (OOD) errors. We propose EigenTrack, an interpretable real-time detector that uses the spectral geometry of hidden activations, a compact global signature of model dynamics. By streaming covariance-spectrum statistics such as entropy, eigenvalue gaps, and KL divergence from random baselines into a lightweight recurrent classifier, EigenTrack tracks temporal shifts in representation structure that signal hallucination and OOD drift before surface errors appear. Unlike black- and grey-box methods, it needs only a single forward pass without resampling. Unlike existing white-box detectors, it preserves temporal context, aggregates global signals, and offers interpretable accuracy-latency trade-offs.
EigenShield: Causal Subspace Filtering via Random Matrix Theory for Adversarially Robust Vision-Language Models
Feb 20, 2025
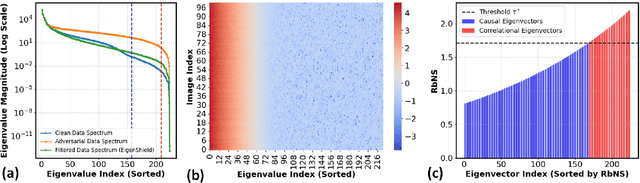
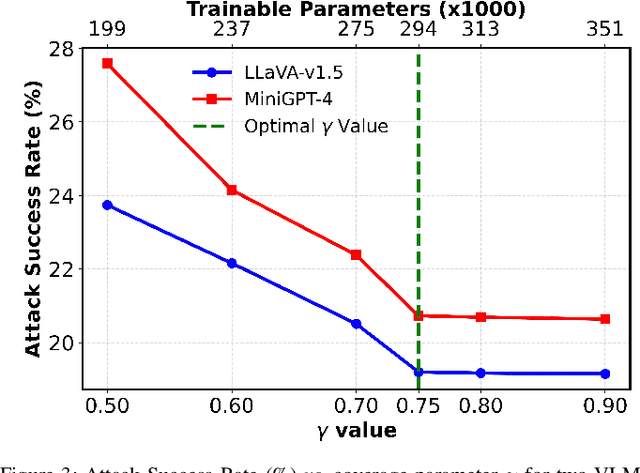
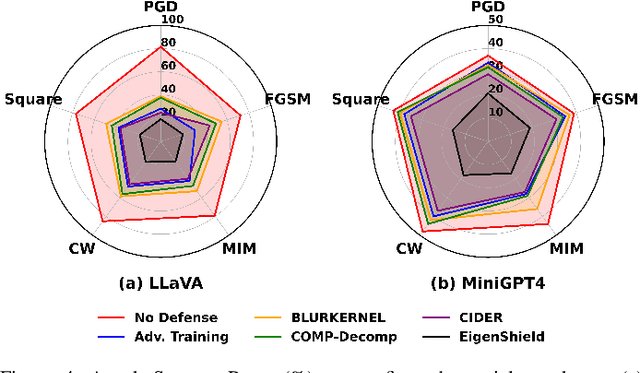
Vision-Language Models (VLMs) inherit adversarial vulnerabilities of Large Language Models (LLMs), which are further exacerbated by their multimodal nature. Existing defenses, including adversarial training, input transformations, and heuristic detection, are computationally expensive, architecture-dependent, and fragile against adaptive attacks. We introduce EigenShield, an inference-time defense leveraging Random Matrix Theory to quantify adversarial disruptions in high-dimensional VLM representations. Unlike prior methods that rely on empirical heuristics, EigenShield employs the spiked covariance model to detect structured spectral deviations. Using a Robustness-based Nonconformity Score (RbNS) and quantile-based thresholding, it separates causal eigenvectors, which encode semantic information, from correlational eigenvectors that are susceptible to adversarial artifacts. By projecting embeddings onto the causal subspace, EigenShield filters adversarial noise without modifying model parameters or requiring adversarial training. This architecture-independent, attack-agnostic approach significantly reduces the attack success rate, establishing spectral analysis as a principled alternative to conventional defenses. Our results demonstrate that EigenShield consistently outperforms all existing defenses, including adversarial training, UNIGUARD, and CIDER.
Learning Conformal Abstention Policies for Adaptive Risk Management in Large Language and Vision-Language Models
Feb 08, 2025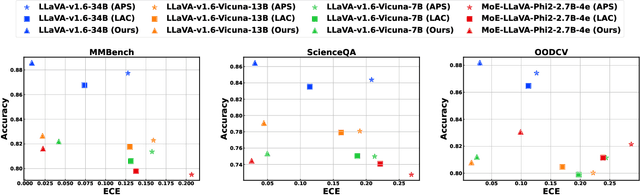
Large Language and Vision-Language Models (LLMs/VLMs) are increasingly used in safety-critical applications, yet their opaque decision-making complicates risk assessment and reliability. Uncertainty quantification (UQ) helps assess prediction confidence and enables abstention when uncertainty is high. Conformal prediction (CP), a leading UQ method, provides statistical guarantees but relies on static thresholds, which fail to adapt to task complexity and evolving data distributions, leading to suboptimal trade-offs in accuracy, coverage, and informativeness. To address this, we propose learnable conformal abstention, integrating reinforcement learning (RL) with CP to optimize abstention thresholds dynamically. By treating CP thresholds as adaptive actions, our approach balances multiple objectives, minimizing prediction set size while maintaining reliable coverage. Extensive evaluations across diverse LLM/VLM benchmarks show our method outperforms Least Ambiguous Classifiers (LAC) and Adaptive Prediction Sets (APS), improving accuracy by up to 3.2%, boosting AUROC for hallucination detection by 22.19%, enhancing uncertainty-guided selective generation (AUARC) by 21.17%, and reducing calibration error by 70%-85%. These improvements hold across multiple models and datasets while consistently meeting the 90% coverage target, establishing our approach as a more effective and flexible solution for reliable decision-making in safety-critical applications. The code is available at: {https://github.com/sinatayebati/vlm-uncertainty}.
SPARC: Subspace-Aware Prompt Adaptation for Robust Continual Learning in LLMs
Feb 05, 2025We propose SPARC, a lightweight continual learning framework for large language models (LLMs) that enables efficient task adaptation through prompt tuning in a lower-dimensional space. By leveraging principal component analysis (PCA), we identify a compact subspace of the training data. Optimizing prompts in this lower-dimensional space enhances training efficiency, as it focuses updates on the most relevant features while reducing computational overhead. Furthermore, since the model's internal structure remains unaltered, the extensive knowledge gained from pretraining is fully preserved, ensuring that previously learned information is not compromised during adaptation. Our method achieves high knowledge retention in both task-incremental and domain-incremental continual learning setups while fine-tuning only 0.04% of the model's parameters. Additionally, by integrating LoRA, we enhance adaptability to computational constraints, allowing for a tradeoff between accuracy and training cost. Experiments on the SuperGLUE benchmark demonstrate that our PCA-based prompt tuning combined with LoRA maintains full knowledge retention while improving accuracy, utilizing only 1% of the model's parameters. These results establish our approach as a scalable and resource-efficient solution for continual learning in LLMs.
Enhancing Trust in Large Language Models with Uncertainty-Aware Fine-Tuning
Dec 03, 2024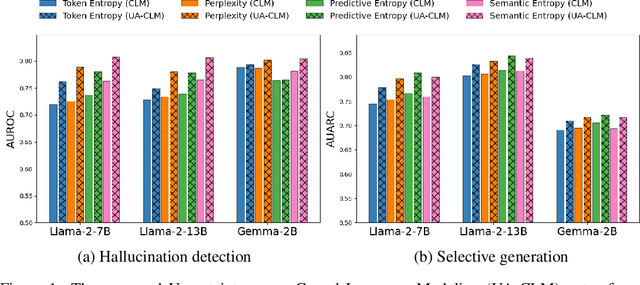
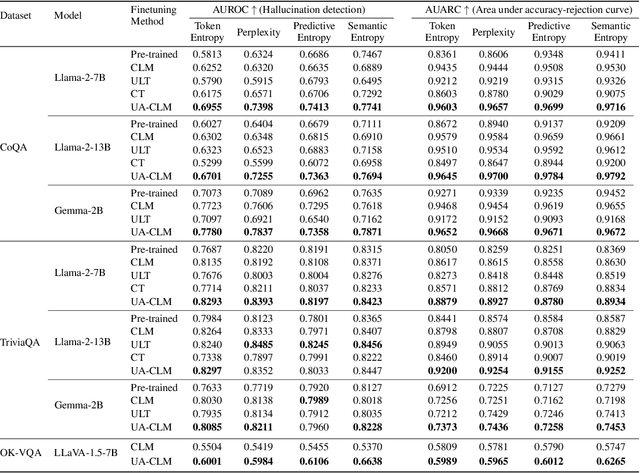

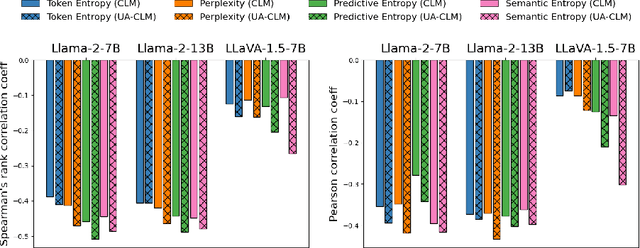
Large language models (LLMs) have revolutionized the field of natural language processing with their impressive reasoning and question-answering capabilities. However, these models are sometimes prone to generating credible-sounding but incorrect information, a phenomenon known as LLM hallucinations. Reliable uncertainty estimation in LLMs is essential for fostering trust in their generated responses and serves as a critical tool for the detection and prevention of erroneous or hallucinated outputs. To achieve reliable and well-calibrated uncertainty quantification in open-ended and free-form natural language generation, we propose an uncertainty-aware fine-tuning approach for LLMs. This approach enhances the model's ability to provide reliable uncertainty estimates without compromising accuracy, thereby guiding them to produce more trustworthy responses. We introduce a novel uncertainty-aware causal language modeling loss function, grounded in the principles of decision theory. Through rigorous evaluation on multiple free-form question-answering datasets and models, we demonstrate that our uncertainty-aware fine-tuning approach yields better calibrated uncertainty estimates in natural language generation tasks than fine-tuning with the standard causal language modeling loss. Furthermore, the experimental results show that the proposed method significantly improves the model's ability to detect hallucinations and identify out-of-domain prompts.
Parameter-Efficient Active Learning for Foundational models
Jun 14, 2024Foundational vision transformer models have shown impressive few shot performance on many vision tasks. This research presents a novel investigation into the application of parameter efficient fine-tuning methods within an active learning (AL) framework, to advance the sampling selection process in extremely budget constrained classification tasks. The focus on image datasets, known for their out-of-distribution characteristics, adds a layer of complexity and relevance to our study. Through a detailed evaluation, we illustrate the improved AL performance on these challenging datasets, highlighting the strategic advantage of merging parameter efficient fine tuning methods with foundation models. This contributes to the broader discourse on optimizing AL strategies, presenting a promising avenue for future exploration in leveraging foundation models for efficient and effective data annotation in specialized domains.
HEAL: Brain-inspired Hyperdimensional Efficient Active Learning
Feb 17, 2024



Drawing inspiration from the outstanding learning capability of our human brains, Hyperdimensional Computing (HDC) emerges as a novel computing paradigm, and it leverages high-dimensional vector presentation and operations for brain-like lightweight Machine Learning (ML). Practical deployments of HDC have significantly enhanced the learning efficiency compared to current deep ML methods on a broad spectrum of applications. However, boosting the data efficiency of HDC classifiers in supervised learning remains an open question. In this paper, we introduce Hyperdimensional Efficient Active Learning (HEAL), a novel Active Learning (AL) framework tailored for HDC classification. HEAL proactively annotates unlabeled data points via uncertainty and diversity-guided acquisition, leading to a more efficient dataset annotation and lowering labor costs. Unlike conventional AL methods that only support classifiers built upon deep neural networks (DNN), HEAL operates without the need for gradient or probabilistic computations. This allows it to be effortlessly integrated with any existing HDC classifier architecture. The key design of HEAL is a novel approach for uncertainty estimation in HDC classifiers through a lightweight HDC ensemble with prior hypervectors. Additionally, by exploiting hypervectors as prototypes (i.e., compact representations), we develop an extra metric for HEAL to select diverse samples within each batch for annotation. Our evaluation shows that HEAL surpasses a diverse set of baselines in AL quality and achieves notably faster acquisition than many BNN-powered or diversity-guided AL methods, recording 11 times to 40,000 times speedup in acquisition runtime per batch.
Reliable Multimodal Trajectory Prediction via Error Aligned Uncertainty Optimization
Dec 09, 2022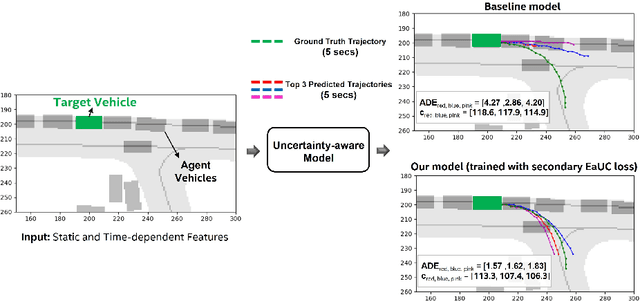
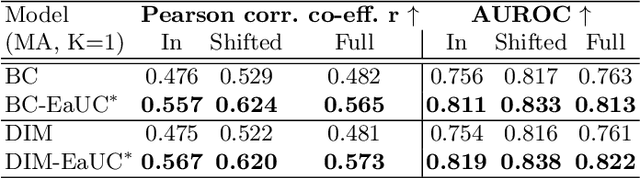
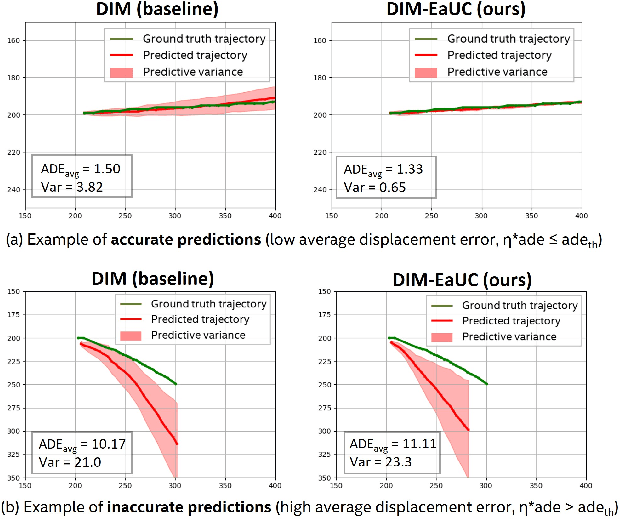

Reliable uncertainty quantification in deep neural networks is very crucial in safety-critical applications such as automated driving for trustworthy and informed decision-making. Assessing the quality of uncertainty estimates is challenging as ground truth for uncertainty estimates is not available. Ideally, in a well-calibrated model, uncertainty estimates should perfectly correlate with model error. We propose a novel error aligned uncertainty optimization method and introduce a trainable loss function to guide the models to yield good quality uncertainty estimates aligning with the model error. Our approach targets continuous structured prediction and regression tasks, and is evaluated on multiple datasets including a large-scale vehicle motion prediction task involving real-world distributional shifts. We demonstrate that our method improves average displacement error by 1.69% and 4.69%, and the uncertainty correlation with model error by 17.22% and 19.13% as quantified by Pearson correlation coefficient on two state-of-the-art baselines.