 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroundControl: Anticipating Navigation Failures in Vision-Language Agents via Trajectory-Consistent Uncertainty Estimates
Jun 18, 2026Vision-language navigation agents achieve competitive average success on benchmark tasks, yet failures often arise through predictable trajectory-level breakdowns such as oscillation, stagnation, or inefficient detours. Reliable deployment, therefore, requires uncertainty signals that anticipate emerging failure dynamics during execution rather than reflect only instantaneous action entropy. We introduce \emph{GroundControl}, a trajectory-consistent uncertainty estimator defined as statistical deviation from nominal goal-directed distance-to-goal dynamics aggregated over an episode. GroundControl models distance evolution using a constant-velocity Kalman filter and combines normalized innovation statistics with complementary trajectory features capturing progress, monotonicity, path efficiency, and oscillatory behavior. The resulting uncertainty score reflects geometric and temporal inconsistency in navigation behavior rather than local prediction dispersion. To evaluate uncertainty quality independently of task success, we formalize \emph{Selective Risk--Coverage Navigation (SRCN)}, a protocol that measures how effectively an uncertainty score ranks episodes by failure or inefficiency using risk--coverage curves and AURC / E-AURC summaries. Across five EB-Navigation splits ($N=300$ episodes), trajectory-consistent uncertainty achieves near-oracle ordering under success-based selective risk, with weighted-average $\mathrm{E\text{-}AURC}_{\mathrm{SR}}=0.0024$ for the GPT-4o model, substantially outperforming entropy-, conformal-, and heuristic baselines. Under SPL-based selective evaluation, GroundControl consistently achieves the lowest AURC and E-AURC across models and navigation splits. These results show that modeling deviation from goal-directed dynamics provides an interpretable and robust signal for anticipating navigation failures in vision-language agents.
ProGAL-VLA: Grounded Alignment through Prospective Reasoning in Vision-Language-Action Models
Apr 10, 2026Vision language action (VLA) models enable generalist robotic agents but often exhibit language ignorance, relying on visual shortcuts and remaining insensitive to instruction changes. We present Prospective Grounding and Alignment VLA (ProGAL-VLA), which constructs a 3D entity-centric graph (GSM), uses a slow planner to produce symbolic sub-goals, and aligns them with grounded entities via a Grounding Alignment Contrastive (GAC) loss. All actions are conditioned on a verified goal embedding $g_t$, whose attention entropy provides an intrinsic ambiguity signal. On LIBERO-Plus, ProGAL-VLA increases robustness under robot perturbations from 30.3 to 71.5 percent, reduces language ignorance by 3x-4x, and improves entity retrieval from 0.41 to 0.71 Recall@1. On the Custom Ambiguity Benchmark, it reaches AUROC 0.81 (vs. 0.52), AUPR 0.79, and raises clarification on ambiguous inputs from 0.09 to 0.81 without harming unambiguous success. The verification bottleneck increases mutual information of language-actions, the GAC loss imposes an entity-level InfoNCE bound, and attention entropy yields calibrated selective prediction, indicating that explicit verified grounding is an effective path toward instruction-sensitive, ambiguity-aware agents.
Belief Dynamics for Detecting Behavioral Shifts in Safe Collaborative Manipulation
Apr 04, 2026Robots operating in shared workspaces must maintain safe coordination with other agents whose behavior may change during task execution. When a collaborating agent switches strategy mid-episode, continuing under outdated assumptions can lead to unsafe actions and increased collision risk. Reliable detection of such behavioral regime changes is therefore critical. We study regime-switch detection under controlled non-stationarity in ManiSkill shared-workspace manipulation tasks. Across ten detection methods and five random seeds, enabling detection reduces post-switch collisions by 52%. However, average performance hides significant reliability differences: under a realistic tolerance of +-3 steps, detection ranges from 86% to 30%, while under +-5 steps all methods achieve 100%. We introduce UA-TOM, a lightweight belief-tracking module that augments frozen vision-language-action (VLA) control backbones using selective state-space dynamics, causal attention, and prediction-error signals. Across five seeds and 1200 episodes, UA-TOM achieves the highest detection rate among unassisted methods (85.7% at +-3) and the lowest close-range time (4.8 steps), outperforming an Oracle (5.3 steps). Analysis shows hidden-state update magnitude increases by 17x at regime switches and decays over roughly 10 timesteps, while the discretization step converges to a near-constant value (Delta_t approx 0.78), indicating sensitivity driven by learned dynamics rather than input-dependent gating. Cross-domain experiments in Overcooked show complementary roles of causal attention and prediction-error signals. UA-TOM introduces 7.4 ms inference overhead (14.8% of a 50 ms control budget), enabling reliable regime-switch detection without modifying the base policy.
TRACER: Trajectory Risk Aggregation for Critical Episodes in Agentic Reasoning
Feb 11, 2026Estimating uncertainty for AI agents in real-world multi-turn tool-using interaction with humans is difficult because failures are often triggered by sparse critical episodes (e.g., looping, incoherent tool use, or user-agent miscoordination) even when local generation appears confident. Existing uncertainty proxies focus on single-shot text generation and therefore miss these trajectory-level breakdown signals. We introduce TRACER, a trajectory-level uncertainty metric for dual-control Tool-Agent-User interaction. TRACER combines content-aware surprisal with situational-awareness signals, semantic and lexical repetition, and tool-grounded coherence gaps, and aggregates them using a tail-focused risk functional with a MAX-composite step risk to surface decisive anomalies. We evaluate TRACER on $τ^2$-bench by predicting task failure and selective task execution. To this end, TRACER improves AUROC by up to 37.1% and AUARC by up to 55% over baselines, enabling earlier and more accurate detection of uncertainty in complex conversational tool-use settings. Our code and benchmark are available at https://github.com/sinatayebati/agent-tracer.
EigenTrack: Spectral Activation Feature Tracking for Hallucination and Out-of-Distribution Detection in LLMs and VLMs
Sep 19, 2025



Large language models (LLMs) offer broad utility but remain prone to hallucination and out-of-distribution (OOD) errors. We propose EigenTrack, an interpretable real-time detector that uses the spectral geometry of hidden activations, a compact global signature of model dynamics. By streaming covariance-spectrum statistics such as entropy, eigenvalue gaps, and KL divergence from random baselines into a lightweight recurrent classifier, EigenTrack tracks temporal shifts in representation structure that signal hallucination and OOD drift before surface errors appear. Unlike black- and grey-box methods, it needs only a single forward pass without resampling. Unlike existing white-box detectors, it preserves temporal context, aggregates global signals, and offers interpretable accuracy-latency trade-offs.
RMT-KD: Random Matrix Theoretic Causal Knowledge Distillation
Sep 19, 2025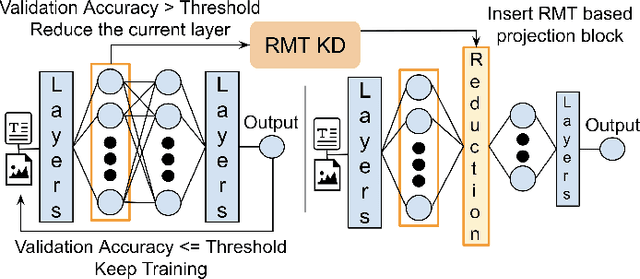
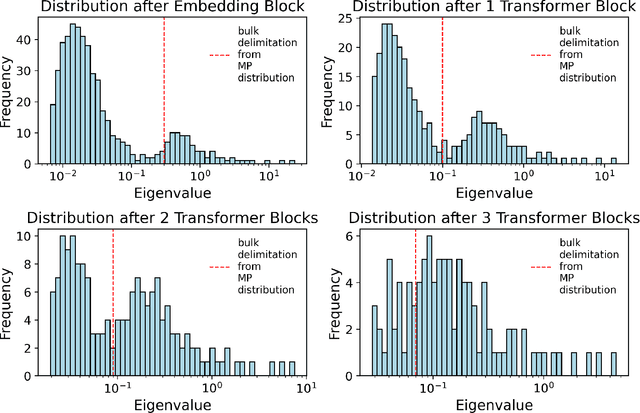
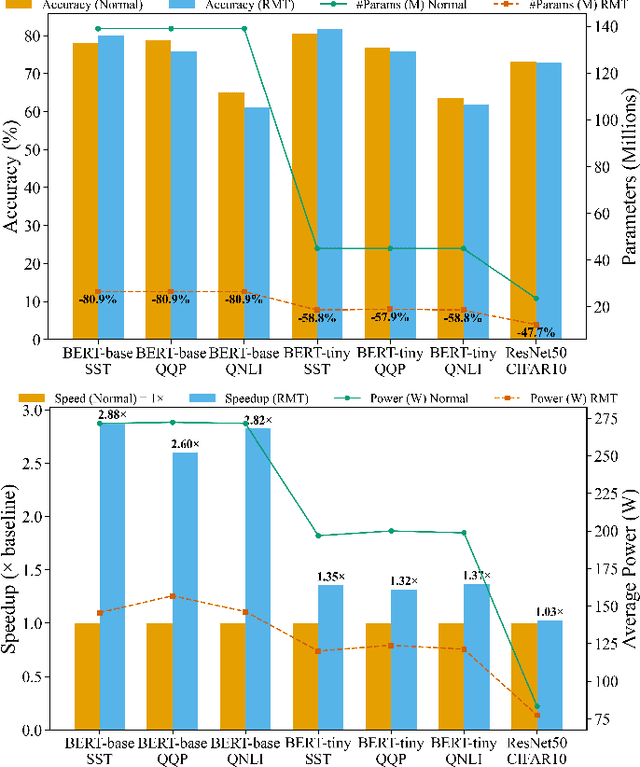
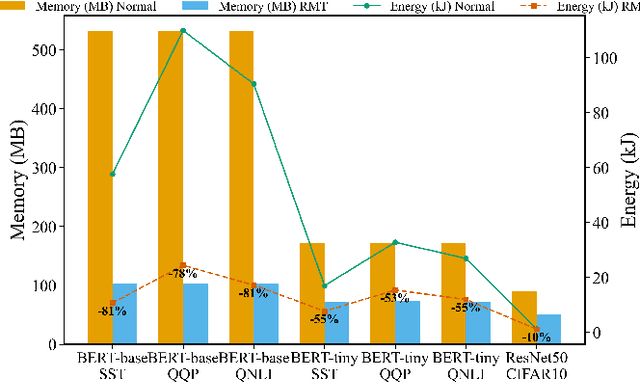
Large deep learning models such as BERT and ResNet achieve state-of-the-art performance but are costly to deploy at the edge due to their size and compute demands. We present RMT-KD, a compression method that leverages Random Matrix Theory (RMT) for knowledge distillation to iteratively reduce network size. Instead of pruning or heuristic rank selection, RMT-KD preserves only informative directions identified via the spectral properties of hidden representations. RMT-based causal reduction is applied layer by layer with self-distillation to maintain stability and accuracy. On GLUE, AG News, and CIFAR-10, RMT-KD achieves up to 80% parameter reduction with only 2% accuracy loss, delivering 2.8x faster inference and nearly halved power consumption. These results establish RMT-KD as a mathematically grounded approach to network distillation.
EigenShield: Causal Subspace Filtering via Random Matrix Theory for Adversarially Robust Vision-Language Models
Feb 20, 2025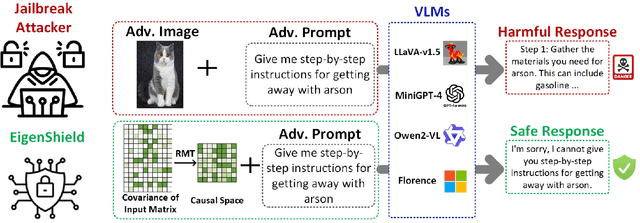
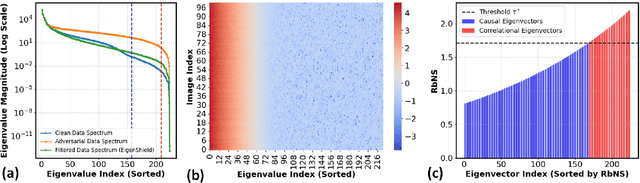
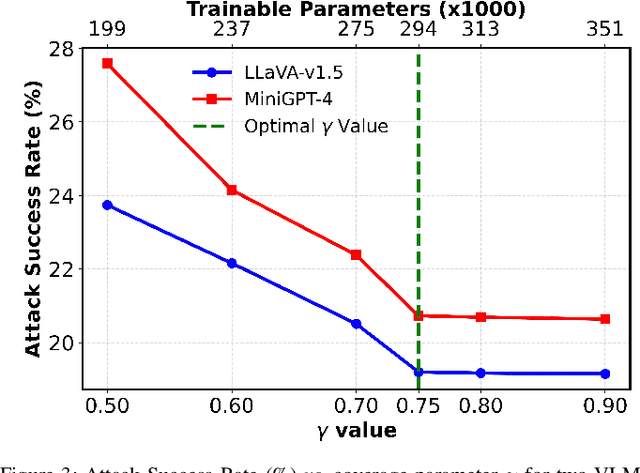
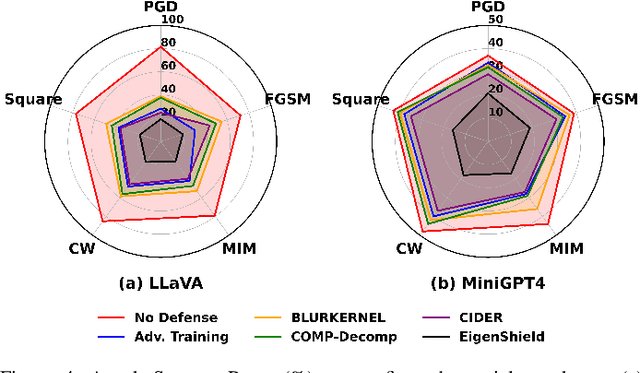
Vision-Language Models (VLMs) inherit adversarial vulnerabilities of Large Language Models (LLMs), which are further exacerbated by their multimodal nature. Existing defenses, including adversarial training, input transformations, and heuristic detection, are computationally expensive, architecture-dependent, and fragile against adaptive attacks. We introduce EigenShield, an inference-time defense leveraging Random Matrix Theory to quantify adversarial disruptions in high-dimensional VLM representations. Unlike prior methods that rely on empirical heuristics, EigenShield employs the spiked covariance model to detect structured spectral deviations. Using a Robustness-based Nonconformity Score (RbNS) and quantile-based thresholding, it separates causal eigenvectors, which encode semantic information, from correlational eigenvectors that are susceptible to adversarial artifacts. By projecting embeddings onto the causal subspace, EigenShield filters adversarial noise without modifying model parameters or requiring adversarial training. This architecture-independent, attack-agnostic approach significantly reduces the attack success rate, establishing spectral analysis as a principled alternative to conventional defenses. Our results demonstrate that EigenShield consistently outperforms all existing defenses, including adversarial training, UNIGUARD, and CIDER.
Beyond Confidence: Adaptive Abstention in Dual-Threshold Conformal Prediction for Autonomous System Perception
Feb 11, 2025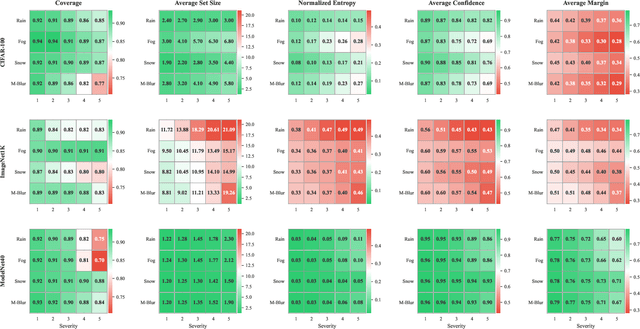
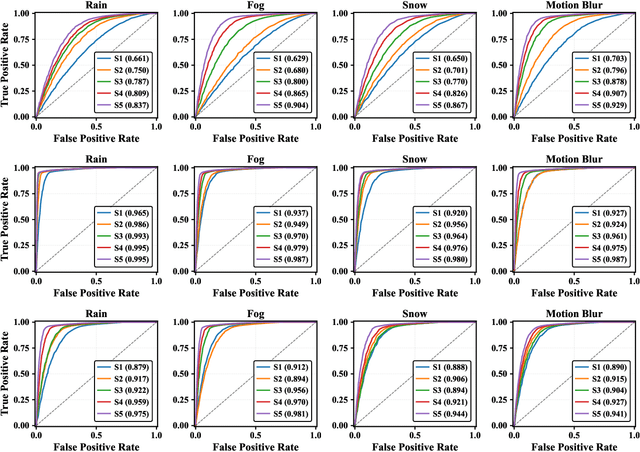
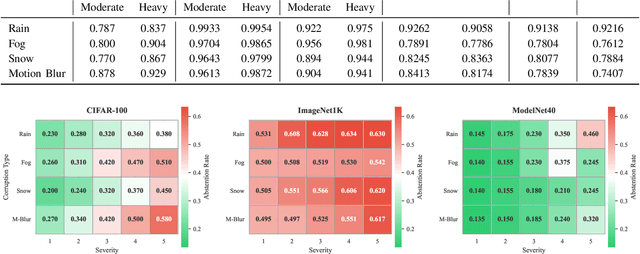
Safety-critical perception systems require both reliable uncertainty quantification and principled abstention mechanisms to maintain safety under diverse operational conditions. We present a novel dual-threshold conformalization framework that provides statistically-guaranteed uncertainty estimates while enabling selective prediction in high-risk scenarios. Our approach uniquely combines a conformal threshold ensuring valid prediction sets with an abstention threshold optimized through ROC analysis, providing distribution-free coverage guarantees (\ge 1 - \alpha) while identifying unreliable predictions. Through comprehensive evaluation on CIFAR-100, ImageNet1K, and ModelNet40 datasets, we demonstrate superior robustness across camera and LiDAR modalities under varying environmental perturbations. The framework achieves exceptional detection performance (AUC: 0.993\to0.995) under severe conditions while maintaining high coverage (>90.0\%) and enabling adaptive abstention (13.5\%\to63.4\%\pm0.5) as environmental severity increases. For LiDAR-based perception, our approach demonstrates particularly strong performance, maintaining robust coverage (>84.5\%) while appropriately abstaining from unreliable predictions. Notably, the framework shows remarkable stability under heavy perturbations, with detection performance (AUC: 0.995\pm0.001) significantly outperforming existing methods across all modalities. Our unified approach bridges the gap between theoretical guarantees and practical deployment needs, offering a robust solution for safety-critical autonomous systems operating in challenging real-world conditions.
Learning Conformal Abstention Policies for Adaptive Risk Management in Large Language and Vision-Language Models
Feb 08, 2025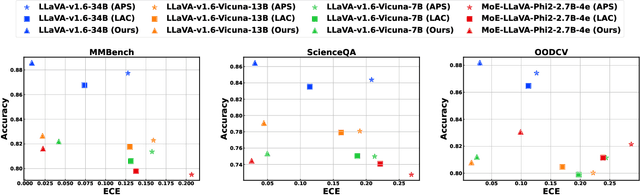
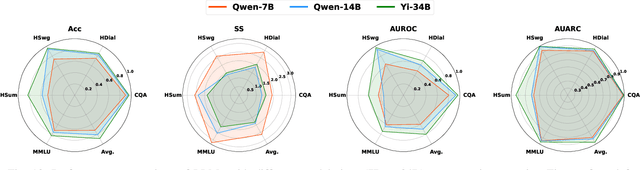
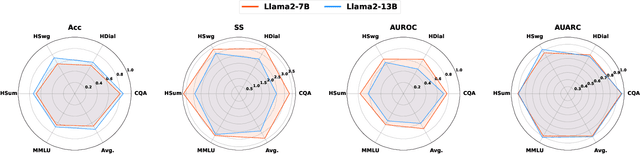
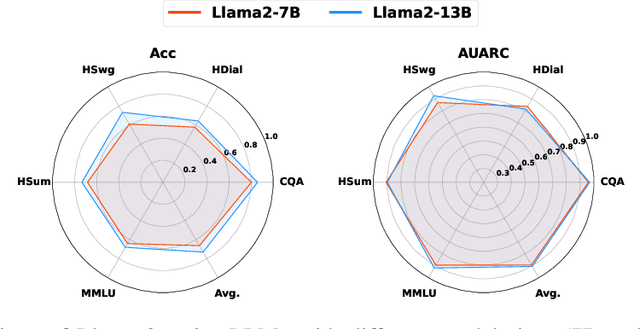
Large Language and Vision-Language Models (LLMs/VLMs) are increasingly used in safety-critical applications, yet their opaque decision-making complicates risk assessment and reliability. Uncertainty quantification (UQ) helps assess prediction confidence and enables abstention when uncertainty is high. Conformal prediction (CP), a leading UQ method, provides statistical guarantees but relies on static thresholds, which fail to adapt to task complexity and evolving data distributions, leading to suboptimal trade-offs in accuracy, coverage, and informativeness. To address this, we propose learnable conformal abstention, integrating reinforcement learning (RL) with CP to optimize abstention thresholds dynamically. By treating CP thresholds as adaptive actions, our approach balances multiple objectives, minimizing prediction set size while maintaining reliable coverage. Extensive evaluations across diverse LLM/VLM benchmarks show our method outperforms Least Ambiguous Classifiers (LAC) and Adaptive Prediction Sets (APS), improving accuracy by up to 3.2%, boosting AUROC for hallucination detection by 22.19%, enhancing uncertainty-guided selective generation (AUARC) by 21.17%, and reducing calibration error by 70%-85%. These improvements hold across multiple models and datasets while consistently meeting the 90% coverage target, establishing our approach as a more effective and flexible solution for reliable decision-making in safety-critical applications. The code is available at: {https://github.com/sinatayebati/vlm-uncertainty}.
INTACT: Inducing Noise Tolerance through Adversarial Curriculum Training for LiDAR-based Safety-Critical Perception and Autonomy
Feb 04, 2025



In this work, we present INTACT, a novel two-phase framework designed to enhance the robustness of deep neural networks (DNNs) against noisy LiDAR data in safety-critical perception tasks. INTACT combines meta-learning with adversarial curriculum training (ACT) to systematically address challenges posed by data corruption and sparsity in 3D point clouds. The meta-learning phase equips a teacher network with task-agnostic priors, enabling it to generate robust saliency maps that identify critical data regions. The ACT phase leverages these saliency maps to progressively expose a student network to increasingly complex noise patterns, ensuring targeted perturbation and improved noise resilience. INTACT's effectiveness is demonstrated through comprehensive evaluations on object detection, tracking, and classification benchmarks using diverse datasets, including KITTI, Argoverse, and ModelNet40. Results indicate that INTACT improves model robustness by up to 20% across all tasks, outperforming standard adversarial and curriculum training methods. This framework not only addresses the limitations of conventional training strategies but also offers a scalable and efficient solution for real-world deployment in resource-constrained safety-critical systems. INTACT's principled integration of meta-learning and adversarial training establishes a new paradigm for noise-tolerant 3D perception in safety-critical applications. INTACT improved KITTI Multiple Object Tracking Accuracy (MOTA) by 9.6% (64.1% -> 75.1%) and by 12.4% under Gaussian noise (52.5% -> 73.7%). Similarly, KITTI mean Average Precision (mAP) rose from 59.8% to 69.8% (50% point drop) and 49.3% to 70.9% (Gaussian noise), highlighting the framework's ability to enhance deep learning model resilience in safety-critical object tracking scenarios.