 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADC/DAC-Free Analog Acceleration of Deep Neural Networks with Frequency Transformation
Sep 04, 2023



The edge processing of deep neural networks (DNNs) is becoming increasingly important due to its ability to extract valuable information directly at the data source to minimize latency and energy consumption. Frequency-domain model compression, such as with the Walsh-Hadamard transform (WHT), has been identified as an efficient alternative. However, the benefits of frequency-domain processing are often offset by the increased multiply-accumulate (MAC) operations required. This paper proposes a novel approach to an energy-efficient acceleration of frequency-domain neural networks by utilizing analog-domain frequency-based tensor transformations. Our approach offers unique opportunities to enhance computational efficiency, resulting in several high-level advantages, including array micro-architecture with parallelism, ADC/DAC-free analog computations, and increased output sparsity. Our approach achieves more compact cells by eliminating the need for trainable parameters in the transformation matrix. Moreover, our novel array micro-architecture enables adaptive stitching of cells column-wise and row-wise, thereby facilitating perfect parallelism in computations. Additionally, our scheme enables ADC/DAC-free computations by training against highly quantized matrix-vector products, leveraging the parameter-free nature of matrix multiplications. Another crucial aspect of our design is its ability to handle signed-bit processing for frequency-based transformations. This leads to increased output sparsity and reduced digitization workload. On a 16$\times$16 crossbars, for 8-bit input processing, the proposed approach achieves the energy efficiency of 1602 tera operations per second per Watt (TOPS/W) without early termination strategy and 5311 TOPS/W with early termination strategy at VDD = 0.8 V.
Memory-Immersed Collaborative Digitization for Area-Efficient Compute-in-Memory Deep Learning
Jul 07, 2023



This work discusses memory-immersed collaborative digitization among compute-in-memory (CiM) arrays to minimize the area overheads of a conventional analog-to-digital converter (ADC) for deep learning inference. Thereby, using the proposed scheme, significantly more CiM arrays can be accommodated within limited footprint designs to improve parallelism and minimize external memory accesses. Under the digitization scheme, CiM arrays exploit their parasitic bit lines to form a within-memory capacitive digital-to-analog converter (DAC) that facilitates area-efficient successive approximation (SA) digitization. CiM arrays collaborate where a proximal array digitizes the analog-domain product-sums when an array computes the scalar product of input and weights. We discuss various networking configurations among CiM arrays where Flash, SA, and their hybrid digitization steps can be efficiently implemented using the proposed memory-immersed scheme. The results are demonstrated using a 65 nm CMOS test chip. Compared to a 40 nm-node 5-bit SAR ADC, our 65 nm design requires $\sim$25$\times$ less area and $\sim$1.4$\times$ less energy by leveraging in-memory computing structures. Compared to a 40 nm-node 5-bit Flash ADC, our design requires $\sim$51$\times$ less area and $\sim$13$\times$ less energy.
MC-CIM: Compute-in-Memory with Monte-Carlo Dropouts for Bayesian Edge Intelligence
Nov 13, 2021


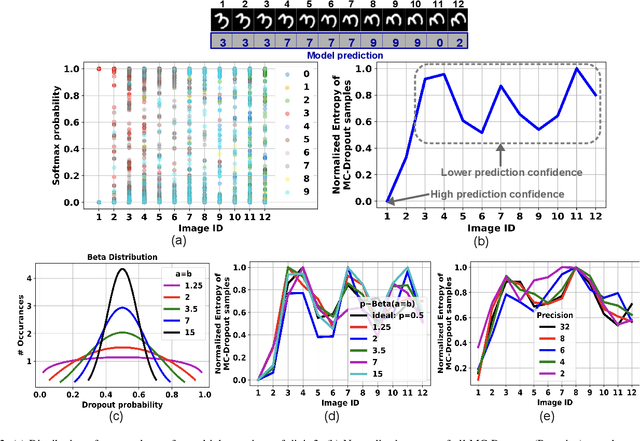
We propose MC-CIM, a compute-in-memory (CIM) framework for robust, yet low power, Bayesian edge intelligence. Deep neural networks (DNN) with deterministic weights cannot express their prediction uncertainties, thereby pose critical risks for applications where the consequences of mispredictions are fatal such as surgical robotics. To address this limitation, Bayesian inference of a DNN has gained attention. Using Bayesian inference, not only the prediction itself, but the prediction confidence can also be extracted for planning risk-aware actions. However, Bayesian inference of a DNN is computationally expensive, ill-suited for real-time and/or edge deployment. An approximation to Bayesian DNN using Monte Carlo Dropout (MC-Dropout) has shown high robustness along with low computational complexity. Enhancing the computational efficiency of the method, we discuss a novel CIM module that can perform in-memory probabilistic dropout in addition to in-memory weight-input scalar product to support the method. We also propose a compute-reuse reformulation of MC-Dropout where each successive instance can utilize the product-sum computations from the previous iteration. Even more, we discuss how the random instances can be optimally ordered to minimize the overall MC-Dropout workload by exploiting combinatorial optimization methods. Application of the proposed CIM-based MC-Dropout execution is discussed for MNIST character recognition and visual odometry (VO) of autonomous drones. The framework reliably gives prediction confidence amidst non-idealities imposed by MC-CIM to a good extent. Proposed MC-CIM with 16x31 SRAM array, 0.85 V supply, 16nm low-standby power (LSTP) technology consumes 27.8 pJ for 30 MC-Dropout instances of probabilistic inference in its most optimal computing and peripheral configuration, saving 43% energy compared to typical execution.
ENOS: Energy-Aware Network Operator Search for Hybrid Digital and Compute-in-Memory DNN Accelerators
Apr 12, 2021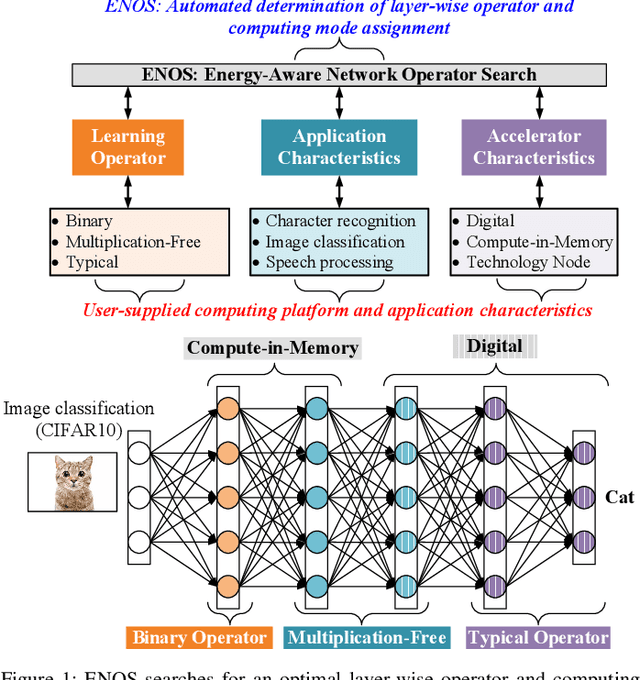
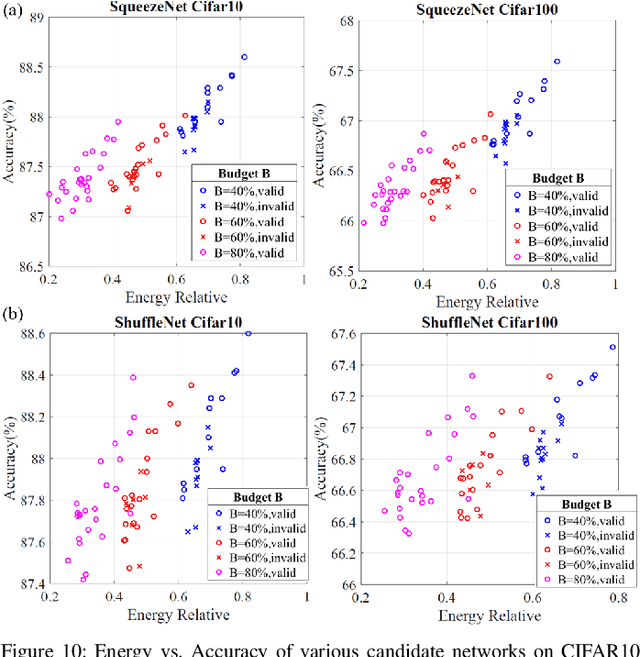
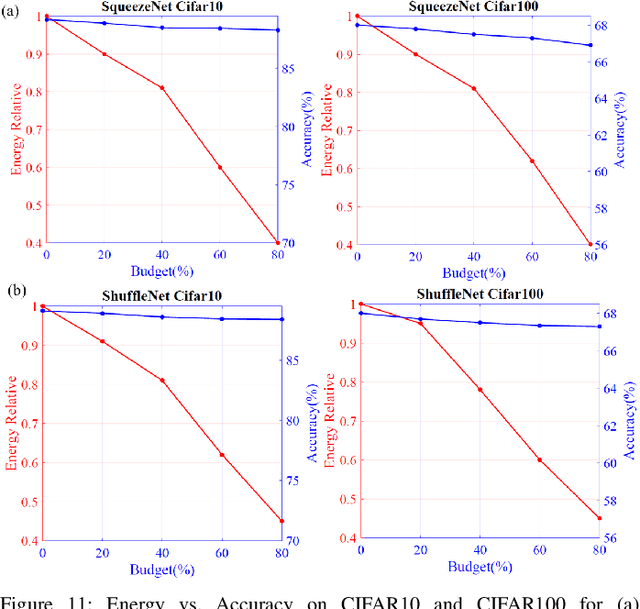

This work proposes a novel Energy-Aware Network Operator Search (ENOS) approach to address the energy-accuracy trade-offs of a deep neural network (DNN) accelerator. In recent years, novel inference operators have been proposed to improve the computational efficiency of a DNN. Augmenting the operators, their corresponding novel computing modes have also been explored. However, simplification of DNN operators invariably comes at the cost of lower accuracy, especially on complex processing tasks. Our proposed ENOS framework allows an optimal layer-wise integration of inference operators and computing modes to achieve the desired balance of energy and accuracy. The search in ENOS is formulated as a continuous optimization problem, solvable using typical gradient descent methods, thereby scalable to larger DNNs with minimal increase in training cost. We characterize ENOS under two settings. In the first setting, for digital accelerators, we discuss ENOS on multiply-accumulate (MAC) cores that can be reconfigured to different operators. ENOS training methods with single and bi-level optimization objectives are discussed and compared. We also discuss a sequential operator assignment strategy in ENOS that only learns the assignment for one layer in one training step, enabling greater flexibility in converging towards the optimal operator allocations. Furthermore, following Bayesian principles, a sampling-based variational mode of ENOS is also presented. ENOS is characterized on popular DNNs ShuffleNet and SqueezeNet on CIFAR10 and CIFAR100.