 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeENOS: Energy-Aware Network Operator Search for Hybrid Digital and Compute-in-Memory DNN Accelerators
Apr 12, 2021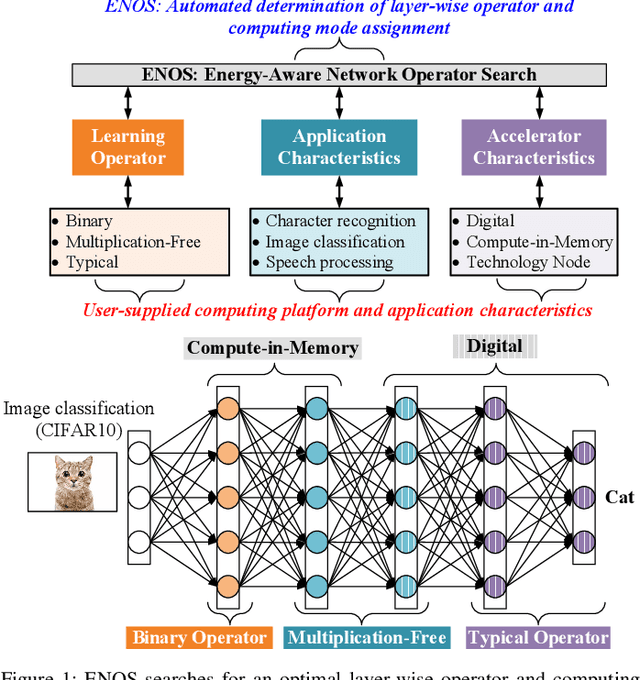
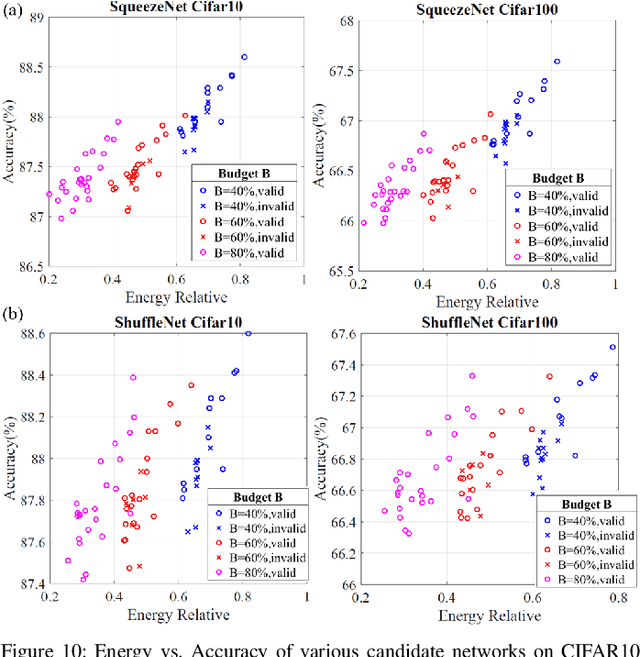
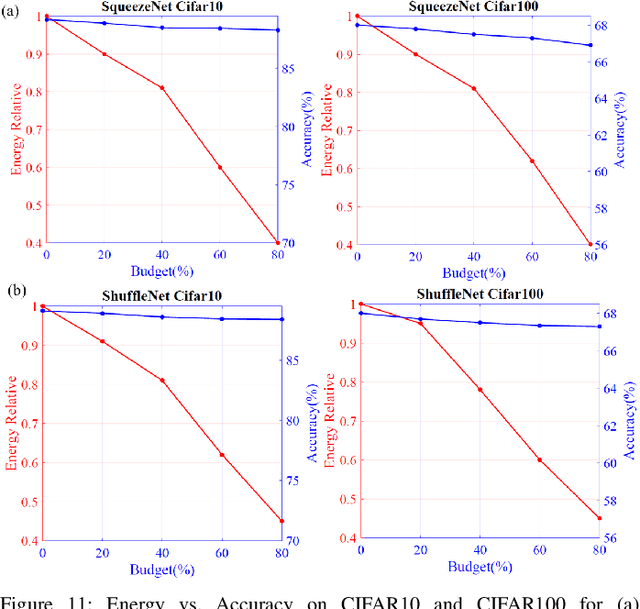

This work proposes a novel Energy-Aware Network Operator Search (ENOS) approach to address the energy-accuracy trade-offs of a deep neural network (DNN) accelerator. In recent years, novel inference operators have been proposed to improve the computational efficiency of a DNN. Augmenting the operators, their corresponding novel computing modes have also been explored. However, simplification of DNN operators invariably comes at the cost of lower accuracy, especially on complex processing tasks. Our proposed ENOS framework allows an optimal layer-wise integration of inference operators and computing modes to achieve the desired balance of energy and accuracy. The search in ENOS is formulated as a continuous optimization problem, solvable using typical gradient descent methods, thereby scalable to larger DNNs with minimal increase in training cost. We characterize ENOS under two settings. In the first setting, for digital accelerators, we discuss ENOS on multiply-accumulate (MAC) cores that can be reconfigured to different operators. ENOS training methods with single and bi-level optimization objectives are discussed and compared. We also discuss a sequential operator assignment strategy in ENOS that only learns the assignment for one layer in one training step, enabling greater flexibility in converging towards the optimal operator allocations. Furthermore, following Bayesian principles, a sampling-based variational mode of ENOS is also presented. ENOS is characterized on popular DNNs ShuffleNet and SqueezeNet on CIFAR10 and CIFAR100.
Probabilistic Localization of Insect-Scale Drones on Floating-Gate Inverter Arrays
Feb 16, 2021



We propose a novel compute-in-memory (CIM)-based ultra-low-power framework for probabilistic localization of insect-scale drones. The conventional probabilistic localization approaches rely on the three-dimensional (3D) Gaussian Mixture Model (GMM)-based representation of a 3D map. A GMM model with hundreds of mixture functions is typically needed to adequately learn and represent the intricacies of the map. Meanwhile, localization using complex GMM map models is computationally intensive. Since insect-scale drones operate under extremely limited area/power budget, continuous localization using GMM models entails much higher operating energy -- thereby, limiting flying duration and/or size of the drone due to a larger battery. Addressing the computational challenges of localization in an insect-scale drone using a CIM approach, we propose a novel framework of 3D map representation using a harmonic mean of "Gaussian-like" mixture (HMGM) model. The likelihood function useful for drone localization can be efficiently implemented by connecting many multi-input inverters in parallel, each programmed with the parameters of the 3D map model represented as HMGM. When the depth measurements are projected to the input of the implementation, the summed current of the inverters emulates the likelihood of the measurement. We have characterized our approach on an RGB-D indoor localization dataset. The average localization error in our approach is $\sim$0.1125 m which is only slightly degraded than software-based evaluation ($\sim$0.08 m). Meanwhile, our localization framework is ultra-low-power, consuming as little as $\sim$17 $\mu$W power while processing a depth frame in 1.33 ms over hundred pose hypotheses in the particle-filtering (PF) algorithm used to localize the drone.
Low Latency CMOS Hardware Acceleration for Fully Connected Layers in Deep Neural Networks
Nov 25, 2020



We present a novel low latency CMOS hardware accelerator for fully connected (FC) layers in deep neural networks (DNNs). The FC accelerator, FC-ACCL, is based on 128 8x8 or 16x16 processing elements (PEs) for matrix-vector multiplication, and 128 multiply-accumulate (MAC) units integrated with 128 High Bandwidth Memory (HBM) units for storing the pretrained weights. Micro-architectural details for CMOS ASIC implementations are presented and simulated performance is compared to recent hardware accelerators for DNNs for AlexNet and VGG 16. When comparing simulated processing latency for a 4096-1000 FC8 layer, our FC-ACCL is able to achieve 48.4 GOPS (with a 100 MHz clock) which improves on a recent FC8 layer accelerator quoted at 28.8 GOPS with a 150 MHz clock. We have achieved this considerable improvement by fully utilizing the HBM units for storing and reading out column-specific FClayer weights in 1 cycle with a novel colum-row-column schedule, and implementing a maximally parallel datapath for processing these weights with the corresponding MAC and PE units. When up-scaled to 128 16x16 PEs, for 16x16 tiles of weights, the design can reduce latency for the large FC6 layer by 60 % in AlexNet and by 3 % in VGG16 when compared to an alternative EIE solution which uses compression.