 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeENOS: Energy-Aware Network Operator Search for Hybrid Digital and Compute-in-Memory DNN Accelerators
Apr 12, 2021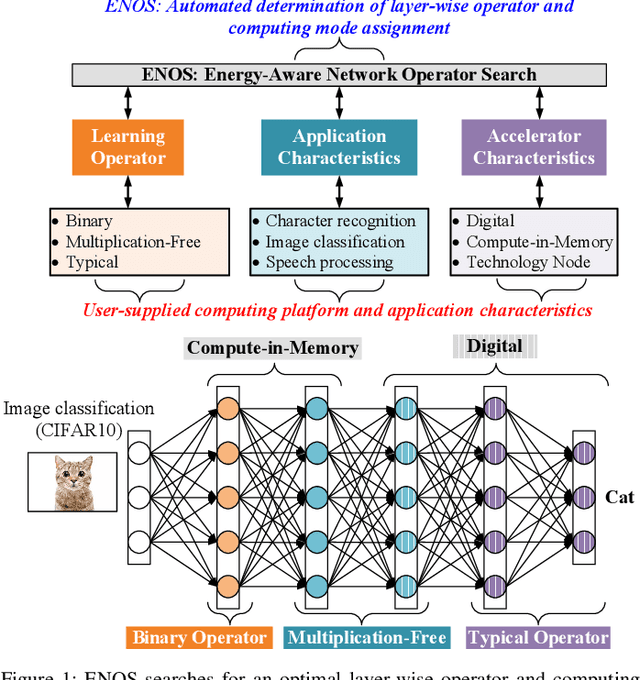
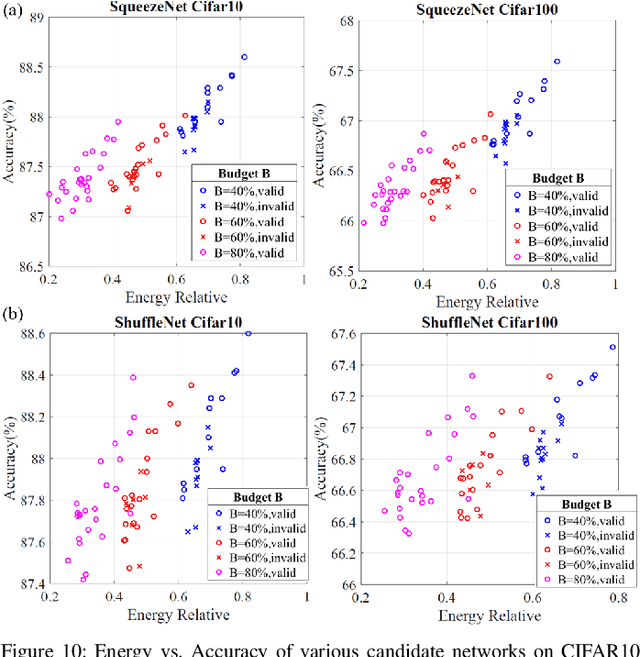
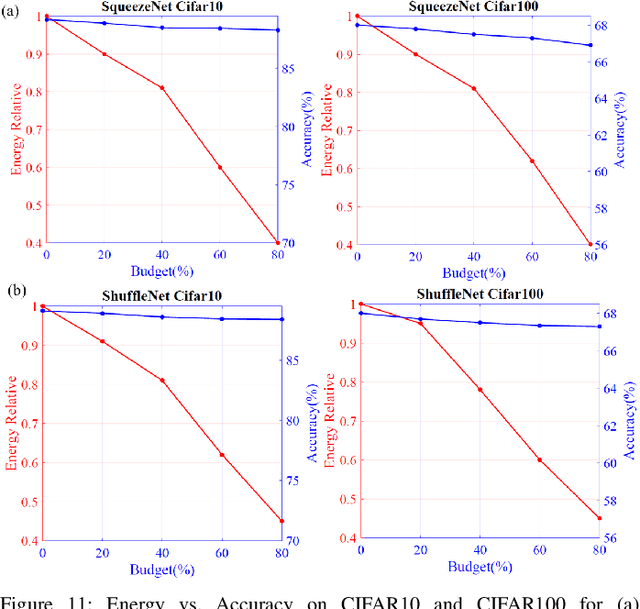

This work proposes a novel Energy-Aware Network Operator Search (ENOS) approach to address the energy-accuracy trade-offs of a deep neural network (DNN) accelerator. In recent years, novel inference operators have been proposed to improve the computational efficiency of a DNN. Augmenting the operators, their corresponding novel computing modes have also been explored. However, simplification of DNN operators invariably comes at the cost of lower accuracy, especially on complex processing tasks. Our proposed ENOS framework allows an optimal layer-wise integration of inference operators and computing modes to achieve the desired balance of energy and accuracy. The search in ENOS is formulated as a continuous optimization problem, solvable using typical gradient descent methods, thereby scalable to larger DNNs with minimal increase in training cost. We characterize ENOS under two settings. In the first setting, for digital accelerators, we discuss ENOS on multiply-accumulate (MAC) cores that can be reconfigured to different operators. ENOS training methods with single and bi-level optimization objectives are discussed and compared. We also discuss a sequential operator assignment strategy in ENOS that only learns the assignment for one layer in one training step, enabling greater flexibility in converging towards the optimal operator allocations. Furthermore, following Bayesian principles, a sampling-based variational mode of ENOS is also presented. ENOS is characterized on popular DNNs ShuffleNet and SqueezeNet on CIFAR10 and CIFAR100.
$MC^2RAM$: Markov Chain Monte Carlo Sampling in SRAM for Fast Bayesian Inference
Feb 28, 2020



This work discusses the implementation of Markov Chain Monte Carlo (MCMC) sampling from an arbitrary Gaussian mixture model (GMM) within SRAM. We show a novel architecture of SRAM by embedding it with random number generators (RNGs), digital-to-analog converters (DACs), and analog-to-digital converters (ADCs) so that SRAM arrays can be used for high performance Metropolis-Hastings (MH) algorithm-based MCMC sampling. Most of the expensive computations are performed within the SRAM and can be parallelized for high speed sampling. Our iterative compute flow minimizes data movement during sampling. We characterize power-performance trade-off of our design by simulating on 45 nm CMOS technology. For a two-dimensional, two mixture GMM, the implementation consumes ~ 91 micro-Watts power per sampling iteration and produces 500 samples in 2000 clock cycles on an average at 1 GHz clock frequency. Our study highlights interesting insights on how low-level hardware non-idealities can affect high-level sampling characteristics, and recommends ways to optimally operate SRAM within area/power constraints for high performance sampling.