 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Sensing-to-Action for Robust Autonomy at the Edge: Opportunities and Challenges
Feb 04, 2025Autonomous edge computing in robotics, smart cities, and autonomous vehicles relies on the seamless integration of sensing, processing, and actuation for real-time decision-making in dynamic environments. At its core is the sensing-to-action loop, which iteratively aligns sensor inputs with computational models to drive adaptive control strategies. These loops can adapt to hyper-local conditions, enhancing resource efficiency and responsiveness, but also face challenges such as resource constraints, synchronization delays in multi-modal data fusion, and the risk of cascading errors in feedback loops. This article explores how proactive, context-aware sensing-to-action and action-to-sensing adaptations can enhance efficiency by dynamically adjusting sensing and computation based on task demands, such as sensing a very limited part of the environment and predicting the rest. By guiding sensing through control actions, action-to-sensing pathways can improve task relevance and resource use, but they also require robust monitoring to prevent cascading errors and maintain reliability. Multi-agent sensing-action loops further extend these capabilities through coordinated sensing and actions across distributed agents, optimizing resource use via collaboration. Additionally, neuromorphic computing, inspired by biological systems, provides an efficient framework for spike-based, event-driven processing that conserves energy, reduces latency, and supports hierarchical control--making it ideal for multi-agent optimization. This article highlights the importance of end-to-end co-design strategies that align algorithmic models with hardware and environmental dynamics and improve cross-layer interdependencies to improve throughput, precision, and adaptability for energy-efficient edge autonomy in complex environments.
SHIRE: Enhancing Sample Efficiency using Human Intuition in REinforcement Learning
Sep 16, 2024The ability of neural networks to perform robotic perception and control tasks such as depth and optical flow estimation, simultaneous localization and mapping (SLAM), and automatic control has led to their widespread adoption in recent years. Deep Reinforcement Learning has been used extensively in these settings, as it does not have the unsustainable training costs associated with supervised learning. However, DeepRL suffers from poor sample efficiency, i.e., it requires a large number of environmental interactions to converge to an acceptable solution. Modern RL algorithms such as Deep Q Learning and Soft Actor-Critic attempt to remedy this shortcoming but can not provide the explainability required in applications such as autonomous robotics. Humans intuitively understand the long-time-horizon sequential tasks common in robotics. Properly using such intuition can make RL policies more explainable while enhancing their sample efficiency. In this work, we propose SHIRE, a novel framework for encoding human intuition using Probabilistic Graphical Models (PGMs) and using it in the Deep RL training pipeline to enhance sample efficiency. Our framework achieves 25-78% sample efficiency gains across the environments we evaluate at negligible overhead cost. Additionally, by teaching RL agents the encoded elementary behavior, SHIRE enhances policy explainability. A real-world demonstration further highlights the efficacy of policies trained using our framework.
Best of Both Worlds: Hybrid SNN-ANN Architecture for Event-based Optical Flow Estimation
Jun 05, 2023



Event-based cameras offer a low-power alternative to frame-based cameras for capturing high-speed motion and high dynamic range scenes. They provide asynchronous streams of sparse events. Spiking Neural Networks (SNNs) with their asynchronous event-driven compute, show great potential for extracting the spatio-temporal features from these event streams. In contrast, the standard Analog Neural Networks (ANNs1) fail to process event data effectively. However, training SNNs is difficult due to additional trainable parameters (thresholds and leaks), vanishing spikes at deeper layers, non-differentiable binary activation function etc. Moreover, an additional data structure "membrane potential" responsible for keeping track of temporal information, must be fetched and updated at every timestep in SNNs. To overcome these, we propose a novel SNN-ANN hybrid architecture that combines the strengths of both. Specifically, we leverage the asynchronous compute capabilities of SNN layers to effectively extract the input temporal information. While the ANN layers offer trouble-free training and implementation on standard machine learning hardware such as GPUs. We provide extensive experimental analysis for assigning each layer to be spiking or analog in nature, leading to a network configuration optimized for performance and ease of training. We evaluate our hybrid architectures for optical flow estimation using event-data on DSEC-flow and Mutli-Vehicle Stereo Event-Camera (MVSEC) datasets. The results indicate that our configured hybrid architectures outperform the state-of-the-art ANN-only, SNN-only and past hybrid architectures both in terms of accuracy and efficiency. Specifically, our hybrid architecture exhibit a 31% and 24.8% lower average endpoint error (AEE) at 2.1x and 3.1x lower energy, compared to an SNN-only architecture on DSEC and MVSEC datasets, respectively.
Hardware/Software co-design with ADC-Less In-memory Computing Hardware for Spiking Neural Networks
Nov 03, 2022Spiking Neural Networks (SNNs) are bio-plausible models that hold great potential for realizing energy-efficient implementations of sequential tasks on resource-constrained edge devices. However, commercial edge platforms based on standard GPUs are not optimized to deploy SNNs, resulting in high energy and latency. While analog In-Memory Computing (IMC) platforms can serve as energy-efficient inference engines, they are accursed by the immense energy, latency, and area requirements of high-precision ADCs (HP-ADC), overshadowing the benefits of in-memory computations. We propose a hardware/software co-design methodology to deploy SNNs into an ADC-Less IMC architecture using sense-amplifiers as 1-bit ADCs replacing conventional HP-ADCs and alleviating the above issues. Our proposed framework incurs minimal accuracy degradation by performing hardware-aware training and is able to scale beyond simple image classification tasks to more complex sequential regression tasks. Experiments on complex tasks of optical flow estimation and gesture recognition show that progressively increasing the hardware awareness during SNN training allows the model to adapt and learn the errors due to the non-idealities associated with ADC-Less IMC. Also, the proposed ADC-Less IMC offers significant energy and latency improvements, $2-7\times$ and $8.9-24.6\times$, respectively, depending on the SNN model and the workload, compared to HP-ADC IMC.
Adaptive-SpikeNet: Event-based Optical Flow Estimation using Spiking Neural Networks with Learnable Neuronal Dynamics
Sep 21, 2022
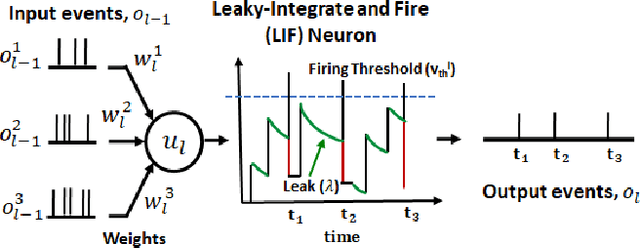
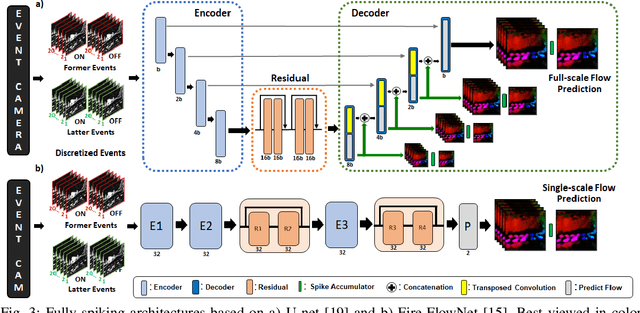
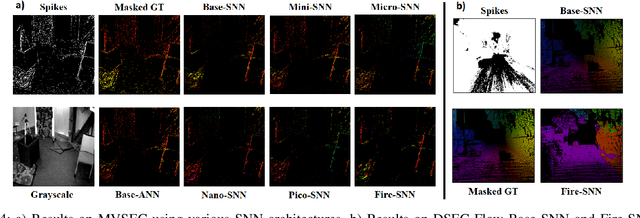
Event-based cameras have recently shown great potential for high-speed motion estimation owing to their ability to capture temporally rich information asynchronously. Spiking Neural Networks (SNNs), with their neuro-inspired event-driven processing can efficiently handle such asynchronous data, while neuron models such as the leaky-integrate and fire (LIF) can keep track of the quintessential timing information contained in the inputs. SNNs achieve this by maintaining a dynamic state in the neuron memory, retaining important information while forgetting redundant data over time. Thus, we posit that SNNs would allow for better performance on sequential regression tasks compared to similarly sized Analog Neural Networks (ANNs). However, deep SNNs are difficult to train due to vanishing spikes at later layers. To that effect, we propose an adaptive fully-spiking framework with learnable neuronal dynamics to alleviate the spike vanishing problem. We utilize surrogate gradient-based backpropagation through time (BPTT) to train our deep SNNs from scratch. We validate our approach for the task of optical flow estimation on the Multi-Vehicle Stereo Event-Camera (MVSEC) dataset and the DSEC-Flow dataset. Our experiments on these datasets show an average reduction of 13% in average endpoint error (AEE) compared to state-of-the-art ANNs. We also explore several down-scaled models and observe that our SNN models consistently outperform similarly sized ANNs offering 10%-16% lower AEE. These results demonstrate the importance of SNNs for smaller models and their suitability at the edge. In terms of efficiency, our SNNs offer substantial savings in network parameters (48x) and computational energy (51x) while attaining ~10% lower EPE compared to the state-of-the-art ANN implementations.
RAPID-RL: A Reconfigurable Architecture with Preemptive-Exits for Efficient Deep-Reinforcement Learning
Sep 16, 2021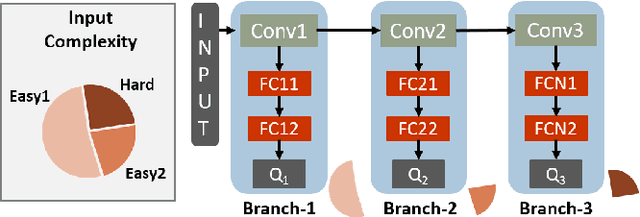
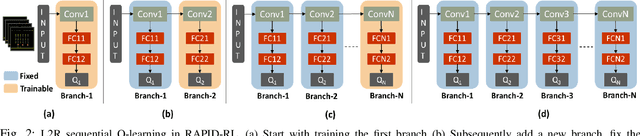
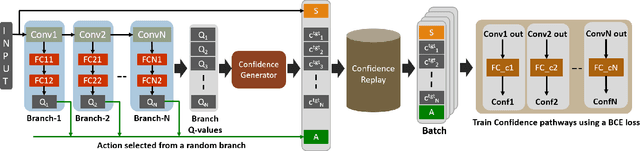
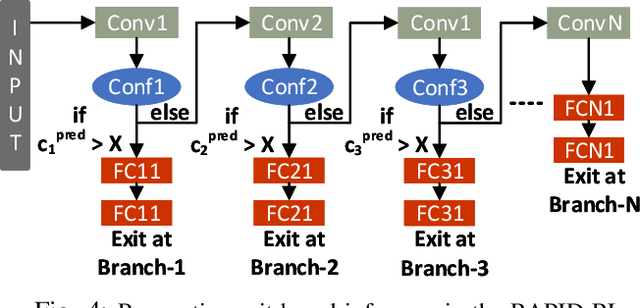
Present-day Deep Reinforcement Learning (RL) systems show great promise towards building intelligent agents surpassing human-level performance. However, the computational complexity associated with the underlying deep neural networks (DNNs) leads to power-hungry implementations. This makes deep RL systems unsuitable for deployment on resource-constrained edge devices. To address this challenge, we propose a reconfigurable architecture with preemptive exits for efficient deep RL (RAPID-RL). RAPID-RL enables conditional activation of DNN layers based on the difficulty level of inputs. This allows to dynamically adjust the compute effort during inference while maintaining competitive performance. We achieve this by augmenting a deep Q-network (DQN) with side-branches capable of generating intermediate predictions along with an associated confidence score. We also propose a novel training methodology for learning the actions and branch confidence scores in a dynamic RL setting. Our experiments evaluate the proposed framework for Atari 2600 gaming tasks and a realistic Drone navigation task on an open-source drone simulator (PEDRA). We show that RAPID-RL incurs 0.34x (0.25x) number of operations (OPS) while maintaining performance above 0.88x (0.91x) on Atari (Drone navigation) tasks, compared to a baseline-DQN without any side-branches. The reduction in OPS leads to fast and efficient inference, proving to be highly beneficial for the resource-constrained edge where making quick decisions with minimal compute is essential.
Fusion-FlowNet: Energy-Efficient Optical Flow Estimation using Sensor Fusion and Deep Fused Spiking-Analog Network Architectures
Mar 19, 2021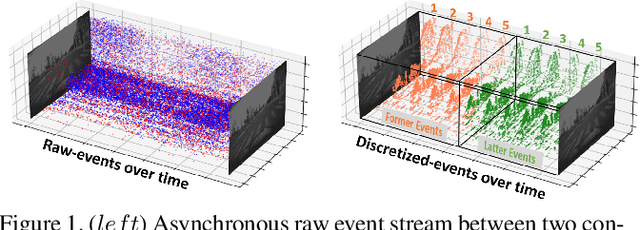
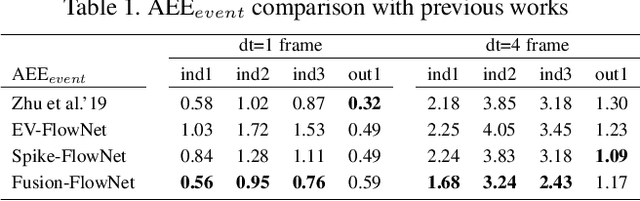
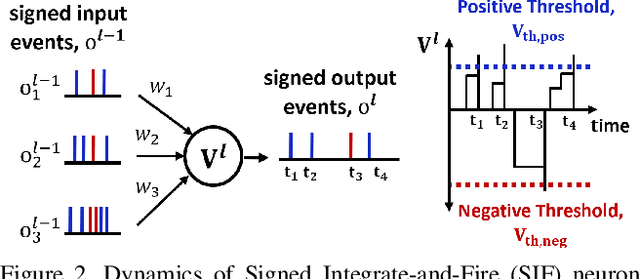
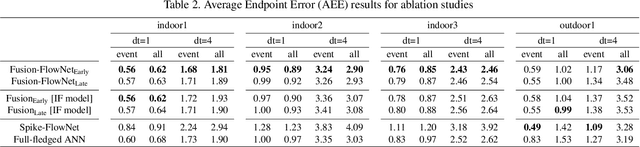
Standard frame-based cameras that sample light intensity frames are heavily impacted by motion blur for high-speed motion and fail to perceive scene accurately when the dynamic range is high. Event-based cameras, on the other hand, overcome these limitations by asynchronously detecting the variation in individual pixel intensities. However, event cameras only provide information about pixels in motion, leading to sparse data. Hence, estimating the overall dense behavior of pixels is difficult. To address such issues associated with the sensors, we present Fusion-FlowNet, a sensor fusion framework for energy-efficient optical flow estimation using both frame- and event-based sensors, leveraging their complementary characteristics. Our proposed network architecture is also a fusion of Spiking Neural Networks (SNNs) and Analog Neural Networks (ANNs) where each network is designed to simultaneously process asynchronous event streams and regular frame-based images, respectively. Our network is end-to-end trained using unsupervised learning to avoid expensive video annotations. The method generalizes well across distinct environments (rapid motion and challenging lighting conditions) and demonstrates state-of-the-art optical flow prediction on the Multi-Vehicle Stereo Event Camera (MVSEC) dataset. Furthermore, our network offers substantial savings in terms of the number of network parameters and computational energy cost.