 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAPID-RL: A Reconfigurable Architecture with Preemptive-Exits for Efficient Deep-Reinforcement Learning
Sep 16, 2021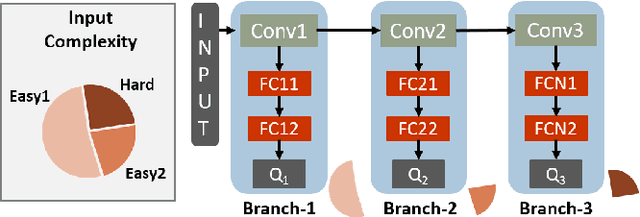
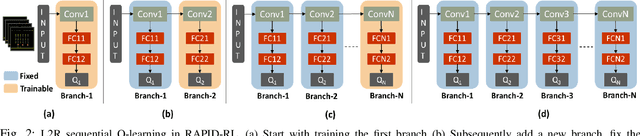
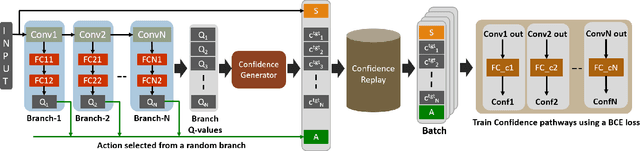
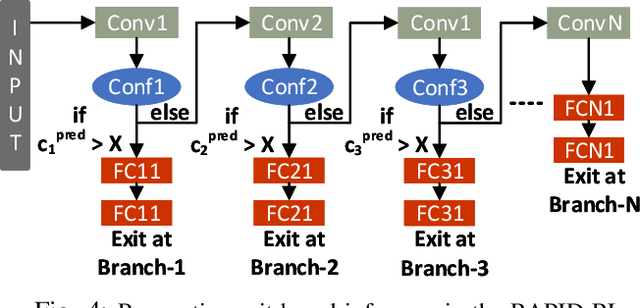
Present-day Deep Reinforcement Learning (RL) systems show great promise towards building intelligent agents surpassing human-level performance. However, the computational complexity associated with the underlying deep neural networks (DNNs) leads to power-hungry implementations. This makes deep RL systems unsuitable for deployment on resource-constrained edge devices. To address this challenge, we propose a reconfigurable architecture with preemptive exits for efficient deep RL (RAPID-RL). RAPID-RL enables conditional activation of DNN layers based on the difficulty level of inputs. This allows to dynamically adjust the compute effort during inference while maintaining competitive performance. We achieve this by augmenting a deep Q-network (DQN) with side-branches capable of generating intermediate predictions along with an associated confidence score. We also propose a novel training methodology for learning the actions and branch confidence scores in a dynamic RL setting. Our experiments evaluate the proposed framework for Atari 2600 gaming tasks and a realistic Drone navigation task on an open-source drone simulator (PEDRA). We show that RAPID-RL incurs 0.34x (0.25x) number of operations (OPS) while maintaining performance above 0.88x (0.91x) on Atari (Drone navigation) tasks, compared to a baseline-DQN without any side-branches. The reduction in OPS leads to fast and efficient inference, proving to be highly beneficial for the resource-constrained edge where making quick decisions with minimal compute is essential.
NAVREN-RL: Learning to fly in real environment via end-to-end deep reinforcement learning using monocular images
Jul 22, 2018


We present NAVREN-RL, an approach to NAVigate an unmanned aerial vehicle in an indoor Real ENvironment via end-to-end reinforcement learning RL. A suitable reward function is designed keeping in mind the cost and weight constraints for micro drone with minimum number of sensing modalities. Collection of small number of expert data and knowledge based data aggregation is integrated into the RL process to aid convergence. Experimentation is carried out on a Parrot AR drone in different indoor arenas and the results are compared with other baseline technologies. We demonstrate how the drone successfully avoids obstacles and navigates across different arenas.