 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContaining Analog Data Deluge at Edge through Frequency-Domain Compression in Collaborative Compute-in-Memory Networks
Paper and Code
Sep 20, 2023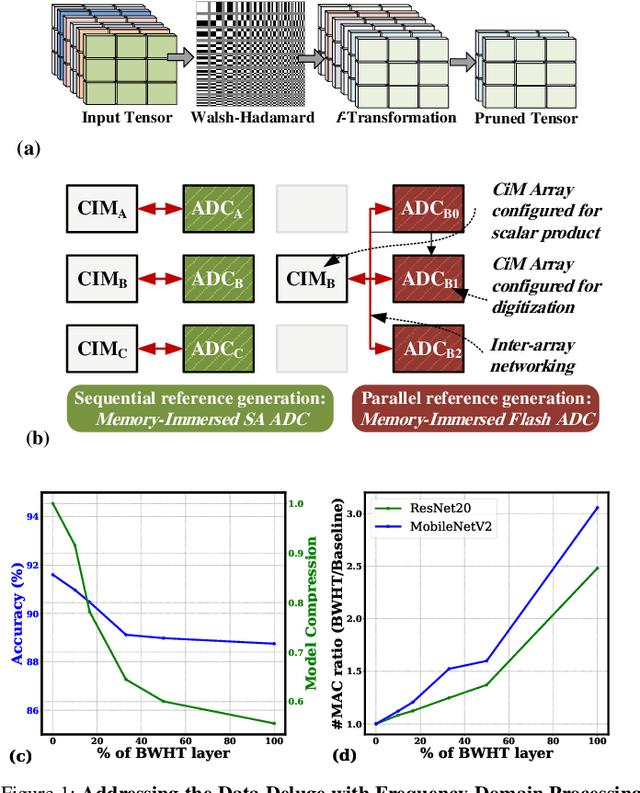
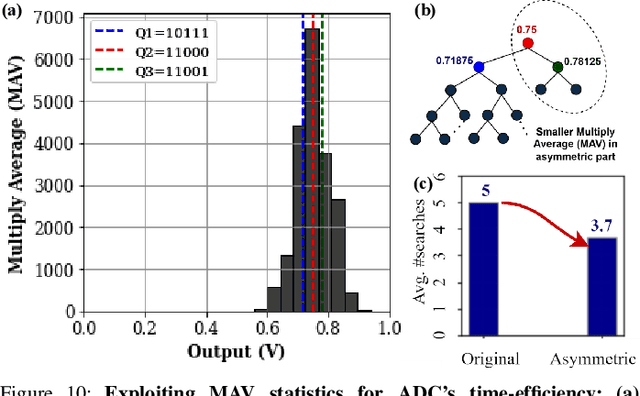
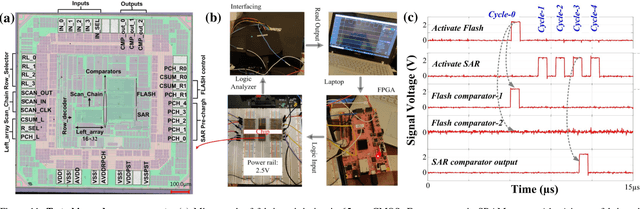
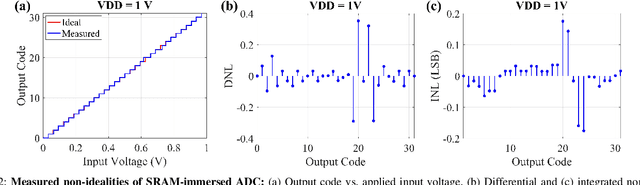
Edge computing is a promising solution for handling high-dimensional, multispectral analog data from sensors and IoT devices for applications such as autonomous drones. However, edge devices' limited storage and computing resources make it challenging to perform complex predictive modeling at the edge. Compute-in-memory (CiM) has emerged as a principal paradigm to minimize energy for deep learning-based inference at the edge. Nevertheless, integrating storage and processing complicates memory cells and/or memory peripherals, essentially trading off area efficiency for energy efficiency. This paper proposes a novel solution to improve area efficiency in deep learning inference tasks. The proposed method employs two key strategies. Firstly, a Frequency domain learning approach uses binarized Walsh-Hadamard Transforms, reducing the necessary parameters for DNN (by 87% in MobileNetV2) and enabling compute-in-SRAM, which better utilizes parallelism during inference. Secondly, a memory-immersed collaborative digitization method is described among CiM arrays to reduce the area overheads of conventional ADCs. This facilitates more CiM arrays in limited footprint designs, leading to better parallelism and reduced external memory accesses. Different networking configurations are explored, where Flash, SA, and their hybrid digitization steps can be implemented using the memory-immersed scheme. The results are demonstrated using a 65 nm CMOS test chip, exhibiting significant area and energy savings compared to a 40 nm-node 5-bit SAR ADC and 5-bit Flash ADC. By processing analog data more efficiently, it is possible to selectively retain valuable data from sensors and alleviate the challenges posed by the analog data deluge.