 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEFA-AI: Advancing Open-source LLMs for RTL generation using Progressive Error Feedback Agentic-AI
Nov 06, 2025We present an agentic flow consisting of multiple agents that combine specialized LLMs and hardware simulation tools to collaboratively complete the complex task of Register Transfer Level (RTL) generation without human intervention. A key feature of the proposed flow is the progressive error feedback system of agents (PEFA), a self-correcting mechanism that leverages iterative error feedback to progressively increase the complexity of the approach. The generated RTL includes checks for compilation, functional correctness, and synthesizable constructs. To validate this adaptive approach to code generation, benchmarking is performed using two opensource natural language-to-RTL datasets. We demonstrate the benefits of the proposed approach implemented on an open source agentic framework, using both open- and closed-source LLMs, effectively bridging the performance gap between them. Compared to previously published methods, our approach sets a new benchmark, providing state-of-the-art pass rates while being efficient in token counts.
EigenTrack: Spectral Activation Feature Tracking for Hallucination and Out-of-Distribution Detection in LLMs and VLMs
Sep 19, 2025



Large language models (LLMs) offer broad utility but remain prone to hallucination and out-of-distribution (OOD) errors. We propose EigenTrack, an interpretable real-time detector that uses the spectral geometry of hidden activations, a compact global signature of model dynamics. By streaming covariance-spectrum statistics such as entropy, eigenvalue gaps, and KL divergence from random baselines into a lightweight recurrent classifier, EigenTrack tracks temporal shifts in representation structure that signal hallucination and OOD drift before surface errors appear. Unlike black- and grey-box methods, it needs only a single forward pass without resampling. Unlike existing white-box detectors, it preserves temporal context, aggregates global signals, and offers interpretable accuracy-latency trade-offs.
Parameter-Efficient Active Learning for Foundational models
Jun 14, 2024Foundational vision transformer models have shown impressive few shot performance on many vision tasks. This research presents a novel investigation into the application of parameter efficient fine-tuning methods within an active learning (AL) framework, to advance the sampling selection process in extremely budget constrained classification tasks. The focus on image datasets, known for their out-of-distribution characteristics, adds a layer of complexity and relevance to our study. Through a detailed evaluation, we illustrate the improved AL performance on these challenging datasets, highlighting the strategic advantage of merging parameter efficient fine tuning methods with foundation models. This contributes to the broader discourse on optimizing AL strategies, presenting a promising avenue for future exploration in leveraging foundation models for efficient and effective data annotation in specialized domains.
Improving Robustness and Efficiency in Active Learning with Contrastive Loss
Sep 13, 2021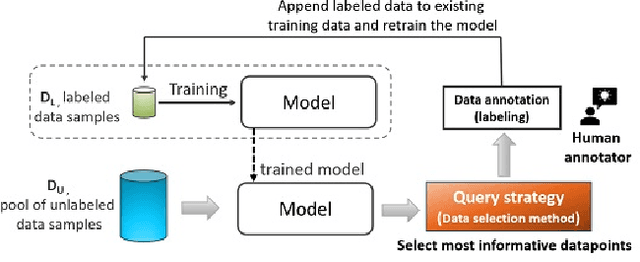
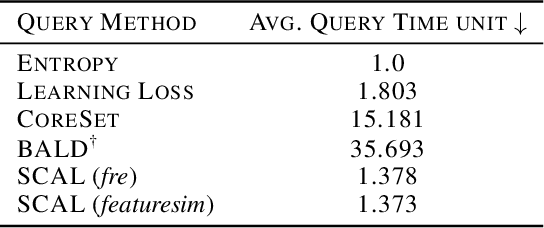
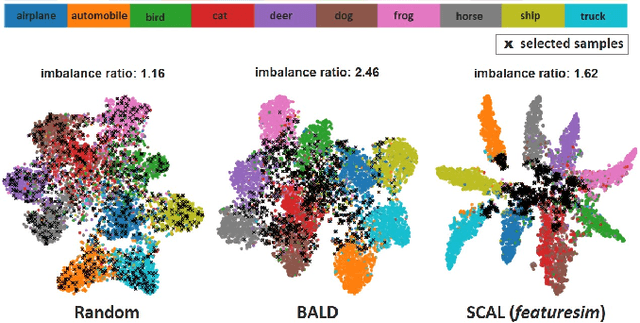
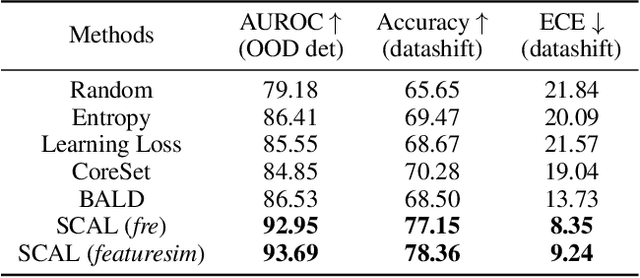
This paper introduces supervised contrastive active learning (SCAL) by leveraging the contrastive loss for active learning in a supervised setting. We propose efficient query strategies in active learning to select unbiased and informative data samples of diverse feature representations. We demonstrate our proposed method reduces sampling bias, achieves state-of-the-art accuracy and model calibration in an active learning setup with the query computation 11x faster than CoreSet and 26x faster than Bayesian active learning by disagreement. Our method yields well-calibrated models even with imbalanced datasets. We also evaluate robustness to dataset shift and out-of-distribution in active learning setup and demonstrate our proposed SCAL method outperforms high performing compute-intensive methods by a bigger margin (average 8.9% higher AUROC for out-of-distribution detection and average 7.2% lower ECE under dataset shift).
Mitigating Sampling Bias and Improving Robustness in Active Learning
Sep 13, 2021
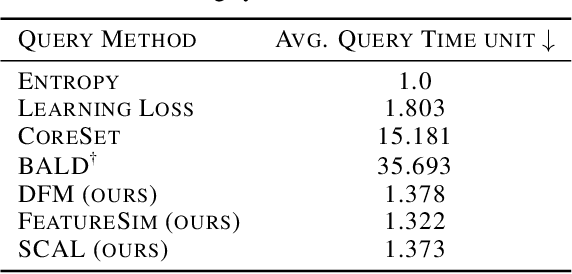


This paper presents simple and efficient methods to mitigate sampling bias in active learning while achieving state-of-the-art accuracy and model robustness. We introduce supervised contrastive active learning by leveraging the contrastive loss for active learning under a supervised setting. We propose an unbiased query strategy that selects informative data samples of diverse feature representations with our methods: supervised contrastive active learning (SCAL) and deep feature modeling (DFM). We empirically demonstrate our proposed methods reduce sampling bias, achieve state-of-the-art accuracy and model calibration in an active learning setup with the query computation 26x faster than Bayesian active learning by disagreement and 11x faster than CoreSet. The proposed SCAL method outperforms by a big margin in robustness to dataset shift and out-of-distribution.
Partially-supervised novel object captioning leveraging context from paired data
Sep 10, 2021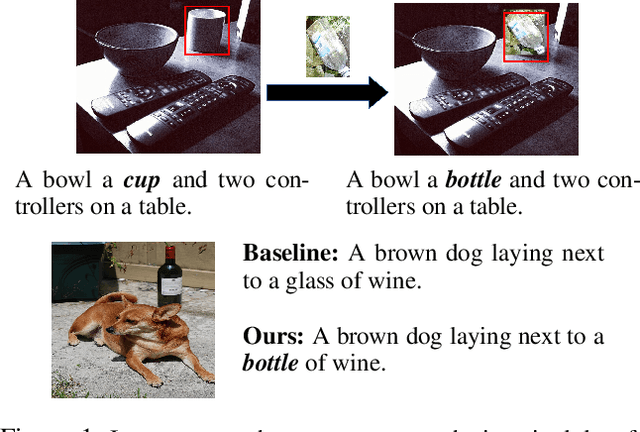
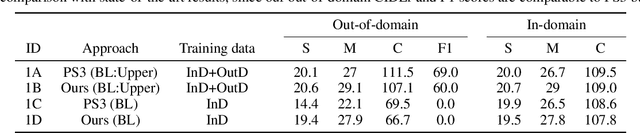
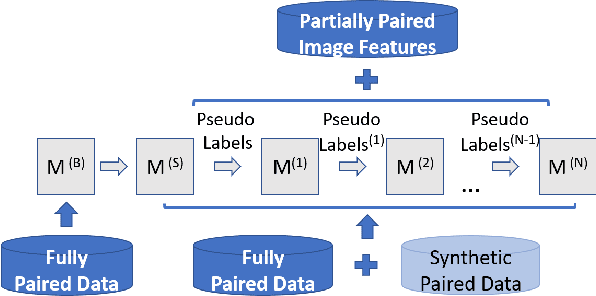
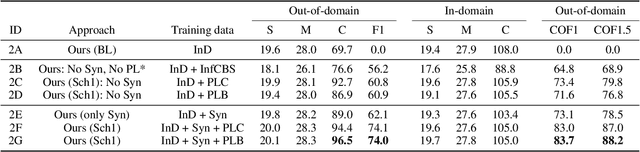
In this paper, we propose an approach to improve image captioning solutions for images with novel objects that do not have caption labels in the training dataset. Our approach is agnostic to model architecture, and primarily focuses on training technique that uses existing fully paired image-caption data and the images with only the novel object detection labels (partially paired data). We create synthetic paired captioning data for these novel objects by leveraging context from existing image-caption pairs. We further re-use these partially paired images with novel objects to create pseudo-label captions that are used to fine-tune the captioning model. Using a popular captioning model (Up-Down) as baseline, our approach achieves state-of-the-art results on held-out MS COCO out-of-domain test split, and improves F1 metric and CIDEr for novel object images by 75.8 and 26.6 points respectively, compared to baseline model that does not use partially paired images during training.
Data augmentation to improve robustness of image captioning solutions
Jun 10, 2021

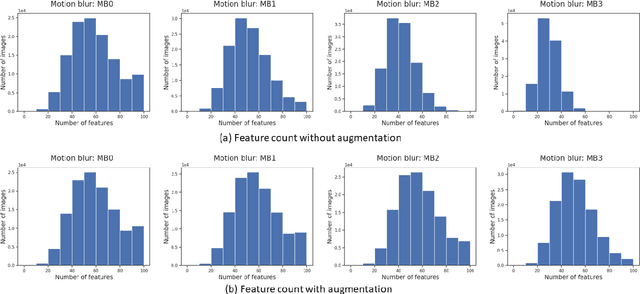
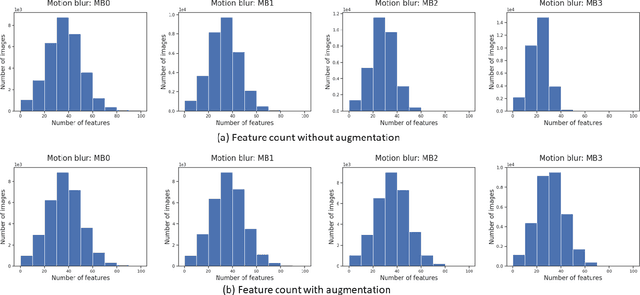
In this paper, we study the impact of motion blur, a common quality flaw in real world images, on a state-of-the-art two-stage image captioning solution, and notice a degradation in solution performance as blur intensity increases. We investigate techniques to improve the robustness of the solution to motion blur using training data augmentation at each or both stages of the solution, i.e., object detection and captioning, and observe improved results. In particular, augmenting both the stages reduces the CIDEr-D degradation for high motion blur intensity from 68.7 to 11.7 on MS COCO dataset, and from 22.4 to 6.8 on Vizwiz dataset.
B-SCST: Bayesian Self-Critical Sequence Training for Image Captioning
Apr 06, 2020
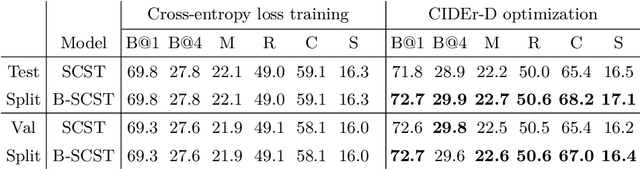
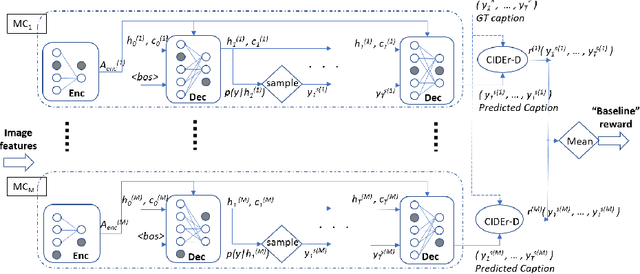
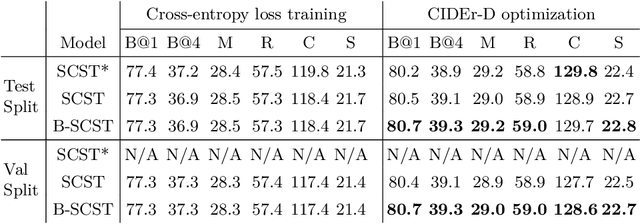
Bayesian deep neural networks (DNN) provide a mathematically grounded framework to quantify uncertainty in their predictions. We propose a Bayesian variant of policy-gradient based reinforcement learning training technique for image captioning models to directly optimize non-differentiable image captioning quality metrics such as CIDEr-D. We extend the well-known Self-Critical Sequence Training (SCST) approach for image captioning models by incorporating Bayesian inference, and refer to it as B-SCST. The "baseline" reward for the policy-gradients in B-SCST is generated by averaging predictive quality metrics (CIDEr-D) of the captions drawn from the distribution obtained using a Bayesian DNN model. This predictive distribution is inferred using Monte Carlo (MC) dropout, which is one of the standard ways to approximate variational inference. We observe that B-SCST improves all the standard captioning quality scores on both Flickr30k and MS COCO datasets, compared to the SCST approach. We also provide a detailed study of uncertainty quantification for the predicted captions, and demonstrate that it correlates well with the CIDEr-D scores. To our knowledge, this is the first such analysis, and it can pave way to more practical image captioning solutions with interpretable models.
Deep Probabilistic Models to Detect Data Poisoning Attacks
Dec 03, 2019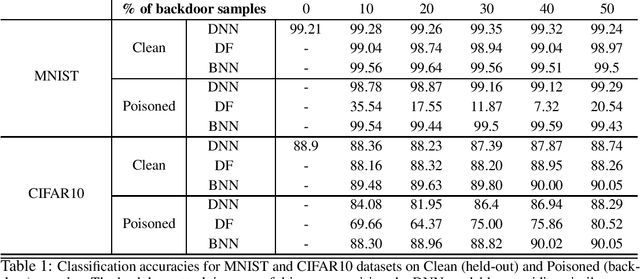
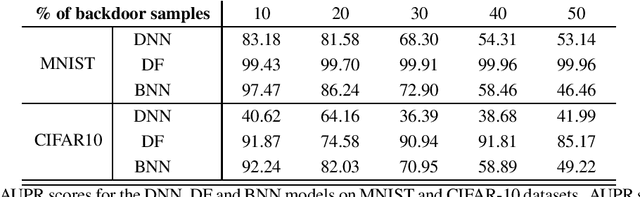
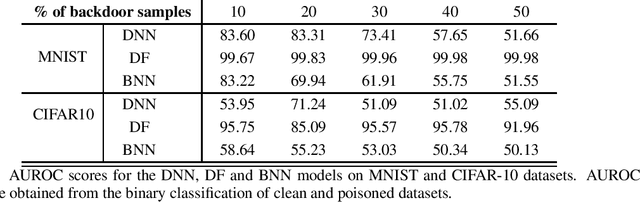
Data poisoning attacks compromise the integrity of machine-learning models by introducing malicious training samples to influence the results during test time. In this work, we investigate backdoor data poisoning attack on deep neural networks (DNNs) by inserting a backdoor pattern in the training images. The resulting attack will misclassify poisoned test samples while maintaining high accuracies for the clean test-set. We present two approaches for detection of such poisoned samples by quantifying the uncertainty estimates associated with the trained models. In the first approach, we model the outputs of the various layers (deep features) with parametric probability distributions learnt from the clean held-out dataset. At inference, the likelihoods of deep features w.r.t these distributions are calculated to derive uncertainty estimates. In the second approach, we use Bayesian deep neural networks trained with mean-field variational inference to estimate model uncertainty associated with the predictions. The uncertainty estimates from these methods are used to discriminate clean from the poisoned samples.
MOPED: Efficient priors for scalable variational inference in Bayesian deep neural networks
Jun 12, 2019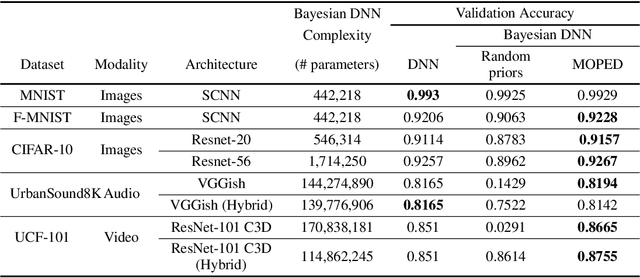
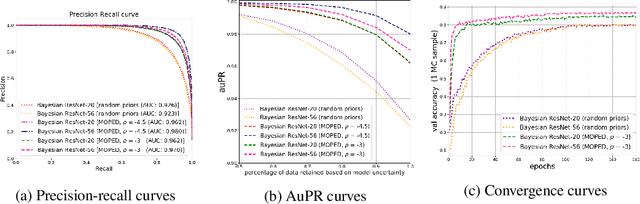


Variational inference for Bayesian deep neural networks (DNNs) requires specifying priors and approximate posterior distributions for neural network weights. Specifying meaningful weight priors is a challenging problem, particularly for scaling variational inference to deeper architectures involving high dimensional weight space. We propose Bayesian MOdel Priors Extracted from Deterministic DNN (MOPED) method for stochastic variational inference to choose meaningful prior distributions over weight space using deterministic weights derived from the pretrained DNNs of equivalent architecture. We evaluate the proposed approach on multiple datasets and real-world application domains with a range of varying complex model architectures to demonstrate MOPED enables scalable variational inference for Bayesian DNNs. The proposed method achieves faster training convergence and provides reliable uncertainty quantification, without compromising on the accuracy provided by the deterministic DNNs. We also propose hybrid architectures to Bayesian DNNs where deterministic and variational layers are combined to balance computation complexity during prediction phase and while providing benefits of Bayesian inference. We will release the source code for this work.