 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartially-supervised novel object captioning leveraging context from paired data
Sep 10, 2021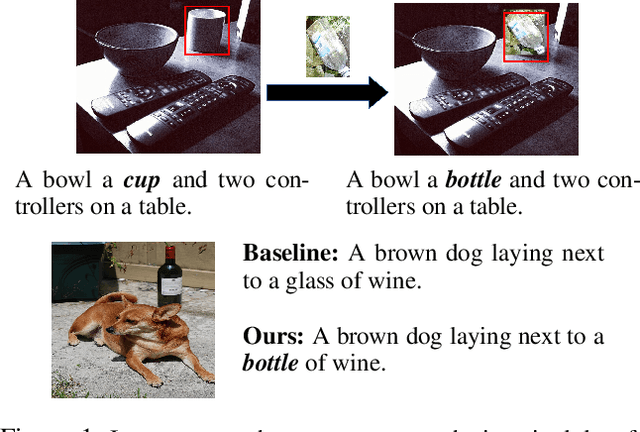
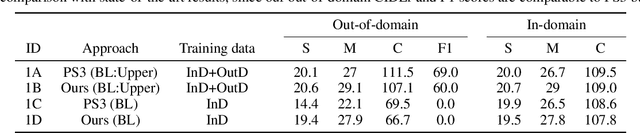
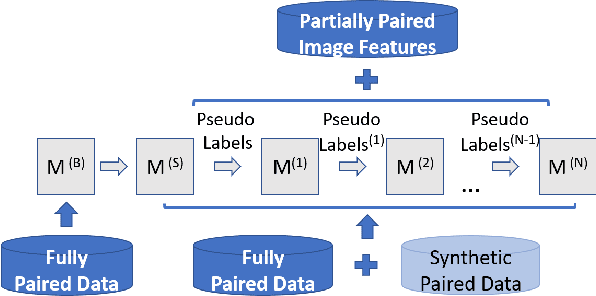
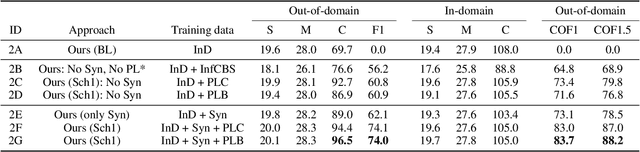
In this paper, we propose an approach to improve image captioning solutions for images with novel objects that do not have caption labels in the training dataset. Our approach is agnostic to model architecture, and primarily focuses on training technique that uses existing fully paired image-caption data and the images with only the novel object detection labels (partially paired data). We create synthetic paired captioning data for these novel objects by leveraging context from existing image-caption pairs. We further re-use these partially paired images with novel objects to create pseudo-label captions that are used to fine-tune the captioning model. Using a popular captioning model (Up-Down) as baseline, our approach achieves state-of-the-art results on held-out MS COCO out-of-domain test split, and improves F1 metric and CIDEr for novel object images by 75.8 and 26.6 points respectively, compared to baseline model that does not use partially paired images during training.
Data augmentation to improve robustness of image captioning solutions
Jun 10, 2021

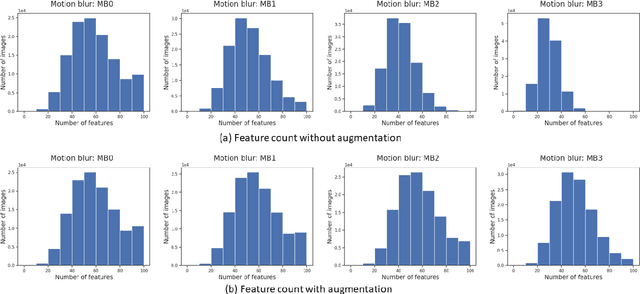
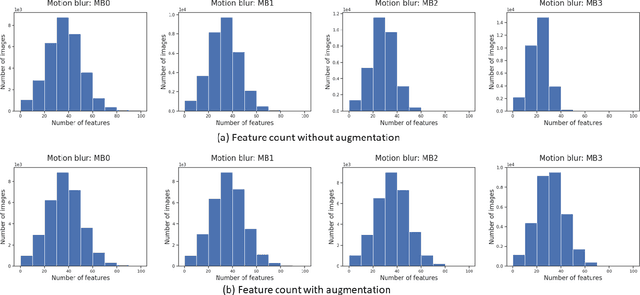
In this paper, we study the impact of motion blur, a common quality flaw in real world images, on a state-of-the-art two-stage image captioning solution, and notice a degradation in solution performance as blur intensity increases. We investigate techniques to improve the robustness of the solution to motion blur using training data augmentation at each or both stages of the solution, i.e., object detection and captioning, and observe improved results. In particular, augmenting both the stages reduces the CIDEr-D degradation for high motion blur intensity from 68.7 to 11.7 on MS COCO dataset, and from 22.4 to 6.8 on Vizwiz dataset.
B-SCST: Bayesian Self-Critical Sequence Training for Image Captioning
Apr 06, 2020
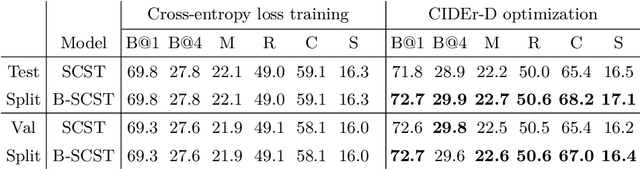
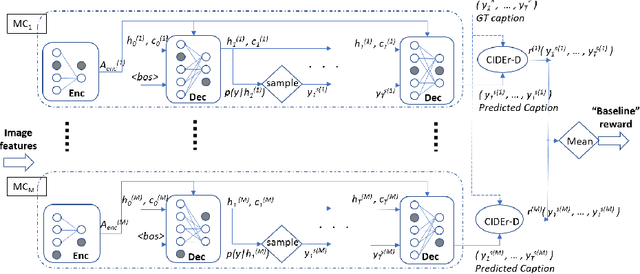
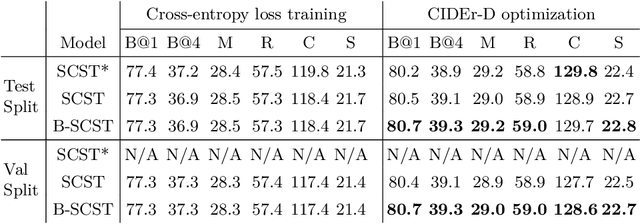
Bayesian deep neural networks (DNN) provide a mathematically grounded framework to quantify uncertainty in their predictions. We propose a Bayesian variant of policy-gradient based reinforcement learning training technique for image captioning models to directly optimize non-differentiable image captioning quality metrics such as CIDEr-D. We extend the well-known Self-Critical Sequence Training (SCST) approach for image captioning models by incorporating Bayesian inference, and refer to it as B-SCST. The "baseline" reward for the policy-gradients in B-SCST is generated by averaging predictive quality metrics (CIDEr-D) of the captions drawn from the distribution obtained using a Bayesian DNN model. This predictive distribution is inferred using Monte Carlo (MC) dropout, which is one of the standard ways to approximate variational inference. We observe that B-SCST improves all the standard captioning quality scores on both Flickr30k and MS COCO datasets, compared to the SCST approach. We also provide a detailed study of uncertainty quantification for the predicted captions, and demonstrate that it correlates well with the CIDEr-D scores. To our knowledge, this is the first such analysis, and it can pave way to more practical image captioning solutions with interpretable models.