 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartially-supervised novel object captioning leveraging context from paired data
Paper and Code
Sep 10, 2021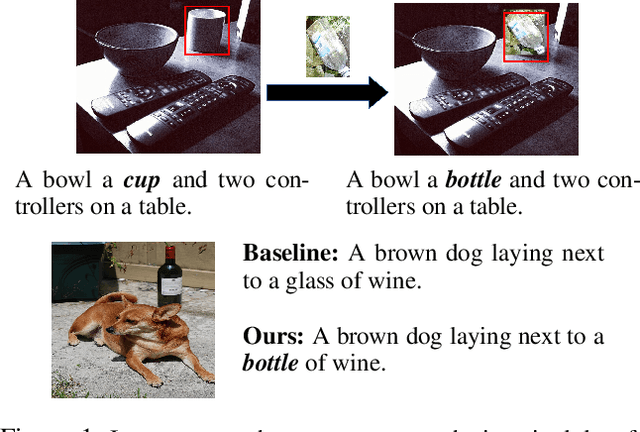
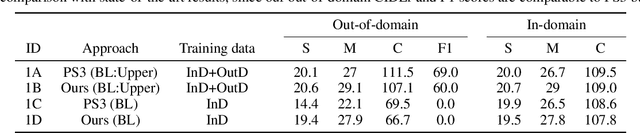
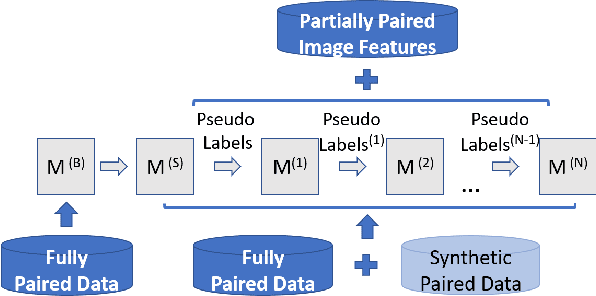
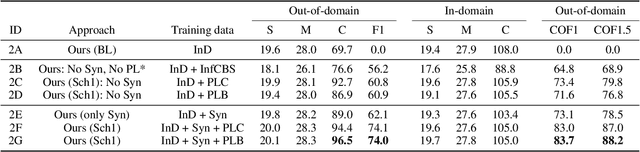
In this paper, we propose an approach to improve image captioning solutions for images with novel objects that do not have caption labels in the training dataset. Our approach is agnostic to model architecture, and primarily focuses on training technique that uses existing fully paired image-caption data and the images with only the novel object detection labels (partially paired data). We create synthetic paired captioning data for these novel objects by leveraging context from existing image-caption pairs. We further re-use these partially paired images with novel objects to create pseudo-label captions that are used to fine-tune the captioning model. Using a popular captioning model (Up-Down) as baseline, our approach achieves state-of-the-art results on held-out MS COCO out-of-domain test split, and improves F1 metric and CIDEr for novel object images by 75.8 and 26.6 points respectively, compared to baseline model that does not use partially paired images during training.