 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOPED: Efficient priors for scalable variational inference in Bayesian deep neural networks
Paper and Code
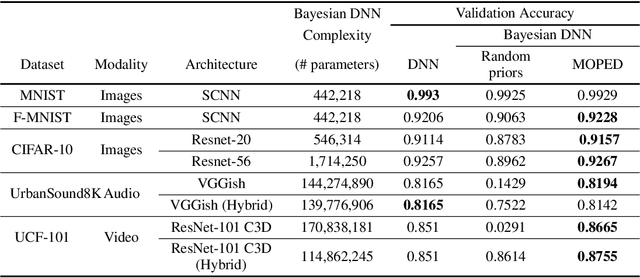
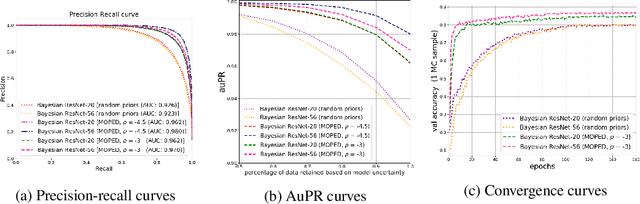


Variational inference for Bayesian deep neural networks (DNNs) requires specifying priors and approximate posterior distributions for neural network weights. Specifying meaningful weight priors is a challenging problem, particularly for scaling variational inference to deeper architectures involving high dimensional weight space. We propose Bayesian MOdel Priors Extracted from Deterministic DNN (MOPED) method for stochastic variational inference to choose meaningful prior distributions over weight space using deterministic weights derived from the pretrained DNNs of equivalent architecture. We evaluate the proposed approach on multiple datasets and real-world application domains with a range of varying complex model architectures to demonstrate MOPED enables scalable variational inference for Bayesian DNNs. The proposed method achieves faster training convergence and provides reliable uncertainty quantification, without compromising on the accuracy provided by the deterministic DNNs. We also propose hybrid architectures to Bayesian DNNs where deterministic and variational layers are combined to balance computation complexity during prediction phase and while providing benefits of Bayesian inference. We will release the source code for this work.