 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification in Continual Open-World Learning
Dec 21, 2024



AI deployed in the real-world should be capable of autonomously adapting to novelties encountered after deployment. Yet, in the field of continual learning, the reliance on novelty and labeling oracles is commonplace albeit unrealistic. This paper addresses a challenging and under-explored problem: a deployed AI agent that continuously encounters unlabeled data - which may include both unseen samples of known classes and samples from novel (unknown) classes - and must adapt to it continuously. To tackle this challenge, we propose our method COUQ "Continual Open-world Uncertainty Quantification", an iterative uncertainty estimation algorithm tailored for learning in generalized continual open-world multi-class settings. We rigorously apply and evaluate COUQ on key sub-tasks in the Continual Open-World: continual novelty detection, uncertainty guided active learning, and uncertainty guided pseudo-labeling for semi-supervised CL. We demonstrate the effectiveness of our method across multiple datasets, ablations, backbones and performance superior to state-of-the-art.
Subspace Modeling for Fast Out-Of-Distribution and Anomaly Detection
Mar 20, 2022

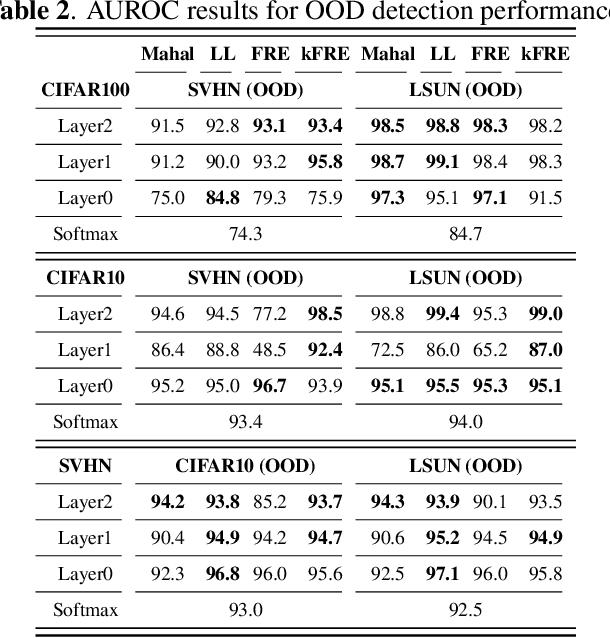
This paper presents a fast, principled approach for detecting anomalous and out-of-distribution (OOD) samples in deep neural networks (DNN). We propose the application of linear statistical dimensionality reduction techniques on the semantic features produced by a DNN, in order to capture the low-dimensional subspace truly spanned by said features. We show that the "feature reconstruction error" (FRE), which is the $\ell_2$-norm of the difference between the original feature in the high-dimensional space and the pre-image of its low-dimensional reduced embedding, is highly effective for OOD and anomaly detection. To generalize to intermediate features produced at any given layer, we extend the methodology by applying nonlinear kernel-based methods. Experiments using standard image datasets and DNN architectures demonstrate that our method meets or exceeds best-in-class quality performance, but at a fraction of the computational and memory cost required by the state of the art. It can be trained and run very efficiently, even on a traditional CPU.
Deep Probabilistic Models to Detect Data Poisoning Attacks
Dec 03, 2019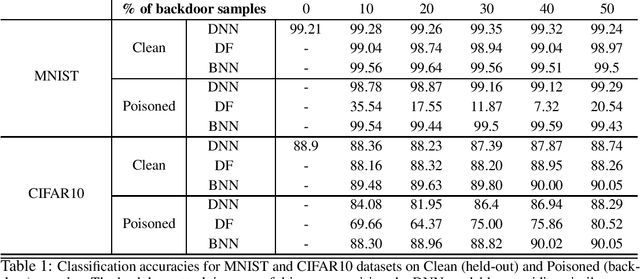
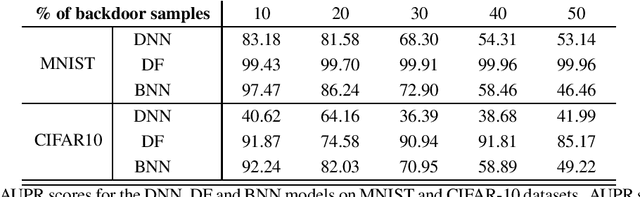
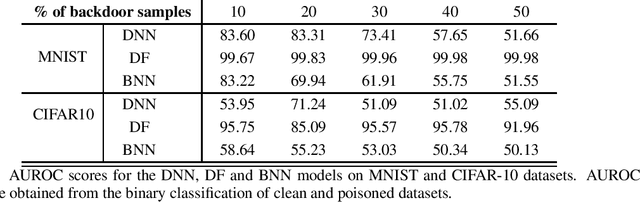
Data poisoning attacks compromise the integrity of machine-learning models by introducing malicious training samples to influence the results during test time. In this work, we investigate backdoor data poisoning attack on deep neural networks (DNNs) by inserting a backdoor pattern in the training images. The resulting attack will misclassify poisoned test samples while maintaining high accuracies for the clean test-set. We present two approaches for detection of such poisoned samples by quantifying the uncertainty estimates associated with the trained models. In the first approach, we model the outputs of the various layers (deep features) with parametric probability distributions learnt from the clean held-out dataset. At inference, the likelihoods of deep features w.r.t these distributions are calculated to derive uncertainty estimates. In the second approach, we use Bayesian deep neural networks trained with mean-field variational inference to estimate model uncertainty associated with the predictions. The uncertainty estimates from these methods are used to discriminate clean from the poisoned samples.