 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXPR: An Extensible Cross-Platform Point-Based Differentiable Renderer
Jun 10, 2026Point-based differentiable rendering underpins modern 3D reconstruction, novel-view synthesis, and learning-based graphics pipelines, but developing new rendering methods often requires extensive low-level implementation, hardware-specific kernels, and manually written backward passes. This limits rapid prototyping, reproducibility, exploration, and deployment, especially across diverse hardware platforms. This paper presents XPR, an extensible cross-platform framework for point-based differentiable rendering. XPR introduces a high-level programming interface that separates method-specific logic from the shared rendering pipeline, allowing users to implement new methods in a few lines of code. Its pipeline decomposes rendering into modular, statically shaped parallel operations that can be lowered by a cross-platform compiler to GPUs, TPUs, CPUs, and other ML accelerators. We demonstrate implementations of 3DGS, 3DGUT, and LinPrim, with only a few 100s lines of Python code, each of which can be compiled to a range of hardware platforms with the XLA compiler. These results show that XPR enables fast experimentation and portable execution for emerging point-based differentiable rendering systems.
TRIAGE: Type-Routed Interventions via Aleatoric-Epistemic Gated Estimation in Robotic Manipulation and Adaptive Perception -- Don't Treat All Uncertainty the Same
Mar 09, 2026Most uncertainty-aware robotic systems collapse prediction uncertainty into a single scalar score and use it to trigger uniform corrective responses. This aggregation obscures whether uncertainty arises from corrupted observations or from mismatch between the learned model and the true system dynamics. As a result, corrective actions may be applied to the wrong component of the closed loop, degrading performance relative to leaving the policy unchanged. We introduce a lightweight post hoc framework that decomposes uncertainty into aleatoric and epistemic components and uses these signals to regulate system responses at inference time. Aleatoric uncertainty is estimated from deviations in the observation distribution using a Mahalanobis density model, while epistemic uncertainty is detected using a noise robust forward dynamics ensemble that isolates model mismatch from measurement corruption. The two signals remain empirically near orthogonal during closed loop execution and enable type specific responses. High aleatoric uncertainty triggers observation recovery, while high epistemic uncertainty moderates control actions. The same signals also regulate adaptive perception by guiding model capacity selection during tracking inference. Experiments demonstrate consistent improvements across both control and perception tasks. In robotic manipulation, the decomposed controller improves task success from 59.4% to 80.4% under compound perturbations and outperforms a combined uncertainty baseline by up to 21.0%. In adaptive tracking inference on MOT17, uncertainty-guided model selection reduces average compute by 58.2% relative to a fixed high capacity detector while preserving detection quality within 0.4%. Code and demo videos are available at https://divake.github.io/uncertainty-decomposition/.
Calibrated Decomposition of Aleatoric and Epistemic Uncertainty in Deep Features for Inference-Time Adaptation
Nov 15, 2025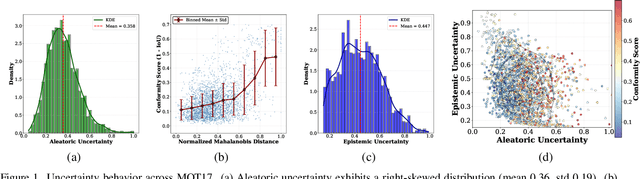
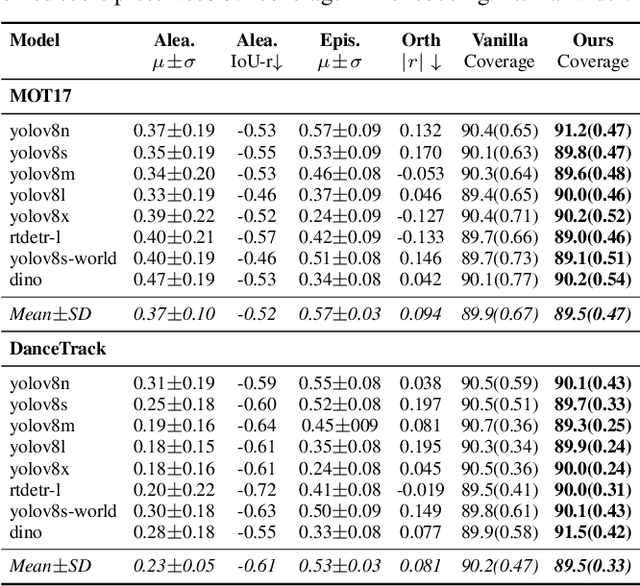
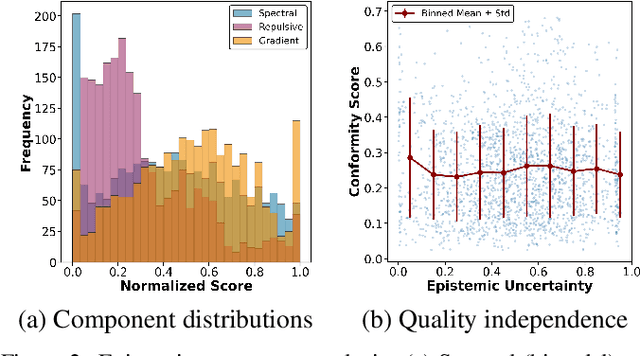
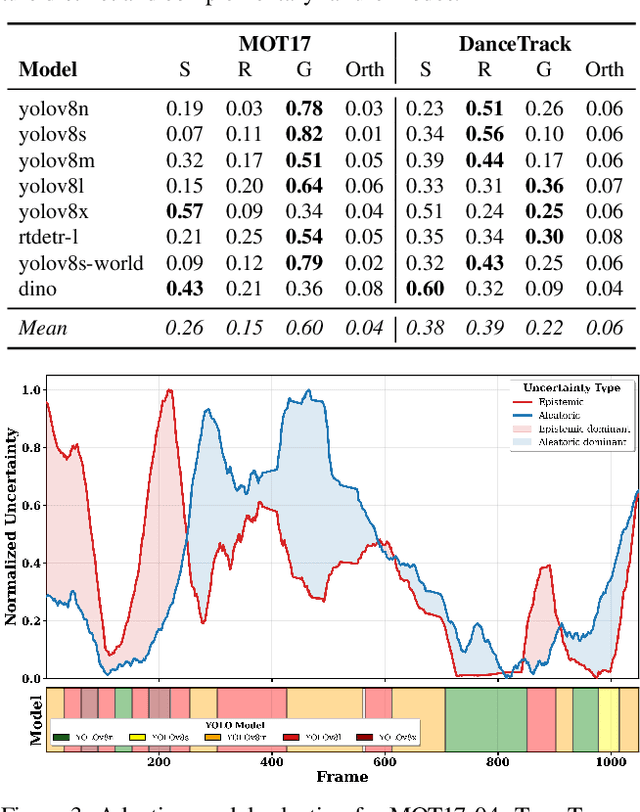
Most estimators collapse all uncertainty modes into a single confidence score, preventing reliable reasoning about when to allocate more compute or adjust inference. We introduce Uncertainty-Guided Inference-Time Selection, a lightweight inference time framework that disentangles aleatoric (data-driven) and epistemic (model-driven) uncertainty directly in deep feature space. Aleatoric uncertainty is estimated using a regularized global density model, while epistemic uncertainty is formed from three complementary components that capture local support deficiency, manifold spectral collapse, and cross-layer feature inconsistency. These components are empirically orthogonal and require no sampling, no ensembling, and no additional forward passes. We integrate the decomposed uncertainty into a distribution free conformal calibration procedure that yields significantly tighter prediction intervals at matched coverage. Using these components for uncertainty guided adaptive model selection reduces compute by approximately 60 percent on MOT17 with negligible accuracy loss, enabling practical self regulating visual inference. Additionally, our ablation results show that the proposed orthogonal uncertainty decomposition consistently yields higher computational savings across all MOT17 sequences, improving margins by 13.6 percentage points over the total-uncertainty baseline.
MoRA: Missing Modality Low-Rank Adaptation for Visual Recognition
Nov 09, 2025Pre-trained vision language models have shown remarkable performance on visual recognition tasks, but they typically assume the availability of complete multimodal inputs during both training and inference. In real-world scenarios, however, modalities may be missing due to privacy constraints, collection difficulties, or resource limitations. While previous approaches have addressed this challenge using prompt learning techniques, they fail to capture the cross-modal relationships necessary for effective multimodal visual recognition and suffer from inevitable computational overhead. In this paper, we introduce MoRA, a parameter-efficient fine-tuning method that explicitly models cross-modal interactions while maintaining modality-specific adaptations. MoRA introduces modality-common parameters between text and vision encoders, enabling bidirectional knowledge transfer. Additionally, combined with the modality-specific parameters, MoRA allows the backbone model to maintain inter-modality interaction and enable intra-modality flexibility. Extensive experiments on standard benchmarks demonstrate that MoRA achieves an average performance improvement in missing-modality scenarios by 5.24% and uses only 25.90% of the inference time compared to the SOTA method while requiring only 0.11% of trainable parameters compared to full fine-tuning.
Windsock is Dancing: Adaptive Multimodal Retrieval-Augmented Generation
Oct 26, 2025Multimodal Retrieval-Augmented Generation (MRAG) has emerged as a promising method to generate factual and up-to-date responses of Multimodal Large Language Models (MLLMs) by incorporating non-parametric knowledge from external knowledge bases. However, existing MRAG approaches suffer from static retrieval strategies, inflexible modality selection, and suboptimal utilization of retrieved information, leading to three critical challenges: determining when to retrieve, what modality to incorporate, and how to utilize retrieved information effectively. To address these challenges, we introduce Windsock, a query-dependent module making decisions on retrieval necessity and modality selection, effectively reducing computational overhead and improving response quality. Additionally, we propose Dynamic Noise-Resistance (DANCE) Instruction Tuning, an adaptive training strategy that enhances MLLMs' ability to utilize retrieved information while maintaining robustness against noise. Moreover, we adopt a self-assessment approach leveraging knowledge within MLLMs to convert question-answering datasets to MRAG training datasets. Extensive experiments demonstrate that our proposed method significantly improves the generation quality by 17.07% while reducing 8.95% retrieval times.
ContraGS: Codebook-Condensed and Trainable Gaussian Splatting for Fast, Memory-Efficient Reconstruction
Sep 03, 20253D Gaussian Splatting (3DGS) is a state-of-art technique to model real-world scenes with high quality and real-time rendering. Typically, a higher quality representation can be achieved by using a large number of 3D Gaussians. However, using large 3D Gaussian counts significantly increases the GPU device memory for storing model parameters. A large model thus requires powerful GPUs with high memory capacities for training and has slower training/rendering latencies due to the inefficiencies of memory access and data movement. In this work, we introduce ContraGS, a method to enable training directly on compressed 3DGS representations without reducing the Gaussian Counts, and thus with a little loss in model quality. ContraGS leverages codebooks to compactly store a set of Gaussian parameter vectors throughout the training process, thereby significantly reducing memory consumption. While codebooks have been demonstrated to be highly effective at compressing fully trained 3DGS models, directly training using codebook representations is an unsolved challenge. ContraGS solves the problem of learning non-differentiable parameters in codebook-compressed representations by posing parameter estimation as a Bayesian inference problem. To this end, ContraGS provides a framework that effectively uses MCMC sampling to sample over a posterior distribution of these compressed representations. With ContraGS, we demonstrate that ContraGS significantly reduces the peak memory during training (on average 3.49X) and accelerated training and rendering (1.36X and 1.88X on average, respectively), while retraining close to state-of-art quality.
TS-OOD: Evaluating Time-Series Out-of-Distribution Detection and Prospective Directions for Progress
Feb 21, 2025
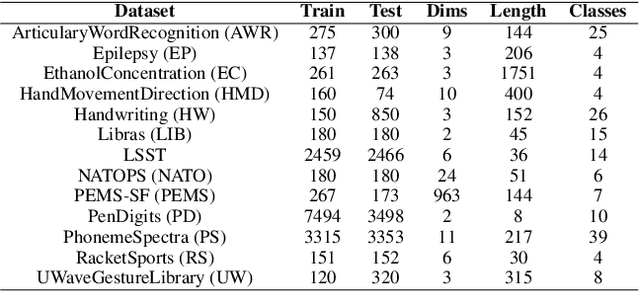
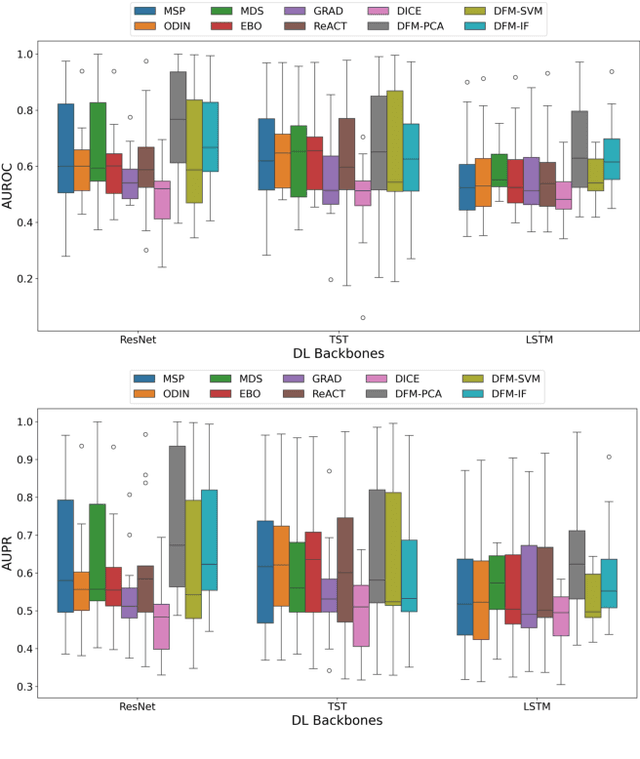
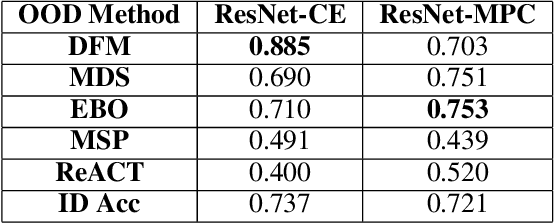
Detecting out-of-distribution (OOD) data is a fundamental challenge in the deployment of machine learning models. From a security standpoint, this is particularly important because OOD test data can result in misleadingly confident yet erroneous predictions, which undermine the reliability of the deployed model. Although numerous models for OOD detection have been developed in computer vision and language, their adaptability to the time-series data domain remains limited and under-explored. Yet, time-series data is ubiquitous across manufacturing and security applications for which OOD is essential. This paper seeks to address this research gap by conducting a comprehensive analysis of modality-agnostic OOD detection algorithms. We evaluate over several multivariate time-series datasets, deep learning architectures, time-series specific data augmentations, and loss functions. Our results demonstrate that: 1) the majority of state-of-the-art OOD methods exhibit limited performance on time-series data, and 2) OOD methods based on deep feature modeling may offer greater advantages for time-series OOD detection, highlighting a promising direction for future time-series OOD detection algorithm development.
INRet: A General Framework for Accurate Retrieval of INRs for Shapes
Jan 27, 2025



Implicit neural representations (INRs) have become an important method for encoding various data types, such as 3D objects or scenes, images, and videos. They have proven to be particularly effective at representing 3D content, e.g., 3D scene reconstruction from 2D images, novel 3D content creation, as well as the representation, interpolation, and completion of 3D shapes. With the widespread generation of 3D data in an INR format, there is a need to support effective organization and retrieval of INRs saved in a data store. A key aspect of retrieval and clustering of INRs in a data store is the formulation of similarity between INRs that would, for example, enable retrieval of similar INRs using a query INR. In this work, we propose INRet, a method for determining similarity between INRs that represent shapes, thus enabling accurate retrieval of similar shape INRs from an INR data store. INRet flexibly supports different INR architectures such as INRs with octree grids, triplanes, and hash grids, as well as different implicit functions including signed/unsigned distance function and occupancy field. We demonstrate that our method is more general and accurate than the existing INR retrieval method, which only supports simple MLP INRs and requires the same architecture between the query and stored INRs. Furthermore, compared to converting INRs to other representations (e.g., point clouds or multi-view images) for 3D shape retrieval, INRet achieves higher accuracy while avoiding the conversion overhead.
Uncertainty Quantification in Continual Open-World Learning
Dec 21, 2024



AI deployed in the real-world should be capable of autonomously adapting to novelties encountered after deployment. Yet, in the field of continual learning, the reliance on novelty and labeling oracles is commonplace albeit unrealistic. This paper addresses a challenging and under-explored problem: a deployed AI agent that continuously encounters unlabeled data - which may include both unseen samples of known classes and samples from novel (unknown) classes - and must adapt to it continuously. To tackle this challenge, we propose our method COUQ "Continual Open-world Uncertainty Quantification", an iterative uncertainty estimation algorithm tailored for learning in generalized continual open-world multi-class settings. We rigorously apply and evaluate COUQ on key sub-tasks in the Continual Open-World: continual novelty detection, uncertainty guided active learning, and uncertainty guided pseudo-labeling for semi-supervised CL. We demonstrate the effectiveness of our method across multiple datasets, ablations, backbones and performance superior to state-of-the-art.
CONCLAD: COntinuous Novel CLAss Detector
Dec 13, 2024


In the field of continual learning, relying on so-called oracles for novelty detection is commonplace albeit unrealistic. This paper introduces CONCLAD ("COntinuous Novel CLAss Detector"), a comprehensive solution to the under-explored problem of continual novel class detection in post-deployment data. At each new task, our approach employs an iterative uncertainty estimation algorithm to differentiate between known and novel class(es) samples, and to further discriminate between the different novel classes themselves. Samples predicted to be from a novel class with high-confidence are automatically pseudo-labeled and used to update our model. Simultaneously, a tiny supervision budget is used to iteratively query ambiguous novel class predictions, which are also used during update. Evaluation across multiple datasets, ablations and experimental settings demonstrate our method's effectiveness at separating novel and old class samples continuously. We will release our code upon acceptance.