 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONCLAD: COntinuous Novel CLAss Detector
Dec 13, 2024


In the field of continual learning, relying on so-called oracles for novelty detection is commonplace albeit unrealistic. This paper introduces CONCLAD ("COntinuous Novel CLAss Detector"), a comprehensive solution to the under-explored problem of continual novel class detection in post-deployment data. At each new task, our approach employs an iterative uncertainty estimation algorithm to differentiate between known and novel class(es) samples, and to further discriminate between the different novel classes themselves. Samples predicted to be from a novel class with high-confidence are automatically pseudo-labeled and used to update our model. Simultaneously, a tiny supervision budget is used to iteratively query ambiguous novel class predictions, which are also used during update. Evaluation across multiple datasets, ablations and experimental settings demonstrate our method's effectiveness at separating novel and old class samples continuously. We will release our code upon acceptance.
CUAL: Continual Uncertainty-aware Active Learner
Dec 12, 2024



AI deployed in many real-world use cases should be capable of adapting to novelties encountered after deployment. Here, we consider a challenging, under-explored and realistic continual adaptation problem: a deployed AI agent is continuously provided with unlabeled data that may contain not only unseen samples of known classes but also samples from novel (unknown) classes. In such a challenging setting, it has only a tiny labeling budget to query the most informative samples to help it continuously learn. We present a comprehensive solution to this complex problem with our model "CUAL" (Continual Uncertainty-aware Active Learner). CUAL leverages an uncertainty estimation algorithm to prioritize active labeling of ambiguous (uncertain) predicted novel class samples while also simultaneously pseudo-labeling the most certain predictions of each class. Evaluations across multiple datasets, ablations, settings and backbones (e.g. ViT foundation model) demonstrate our method's effectiveness. We will release our code upon acceptance.
Lifelong Learning Without a Task Oracle
Nov 09, 2020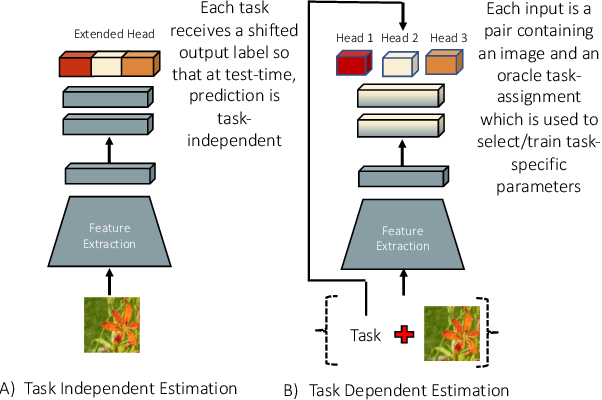
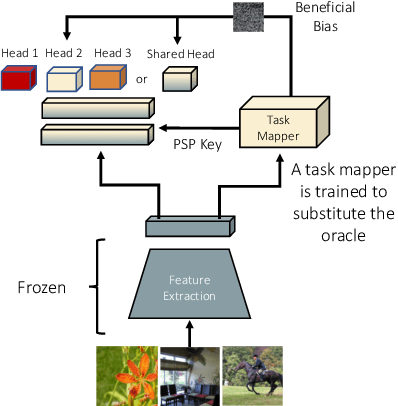
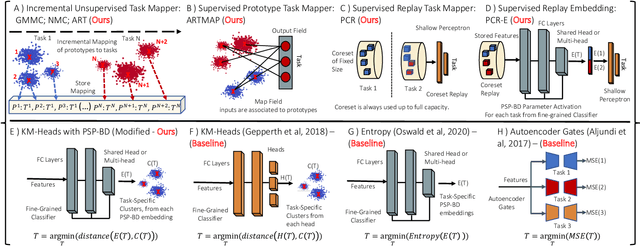
Supervised deep neural networks are known to undergo a sharp decline in the accuracy of older tasks when new tasks are learned, termed "catastrophic forgetting". Many state-of-the-art solutions to continual learning rely on biasing and/or partitioning a model to accommodate successive tasks incrementally. However, these methods largely depend on the availability of a task-oracle to confer task identities to each test sample, without which the models are entirely unable to perform. To address this shortcoming, we propose and compare several candidate task-assigning mappers which require very little memory overhead: (1) Incremental unsupervised prototype assignment using either nearest means, Gaussian Mixture Models or fuzzy ART backbones; (2) Supervised incremental prototype assignment with fast fuzzy ARTMAP; (3) Shallow perceptron trained via a dynamic coreset. Our proposed model variants are trained either from pre-trained feature extractors or task-dependent feature embeddings of the main classifier network. We apply these pipeline variants to continual learning benchmarks, comprised of either sequences of several datasets or within one single dataset. Overall, these methods, despite their simplicity and compactness, perform very close to a ground truth oracle, especially in experiments of inter-dataset task assignment. Moreover, best-performing variants only impose an average cost of 1.7% parameter memory increase.
Beneficial Perturbation Network for designing general adaptive artificial intelligence systems
Sep 27, 2020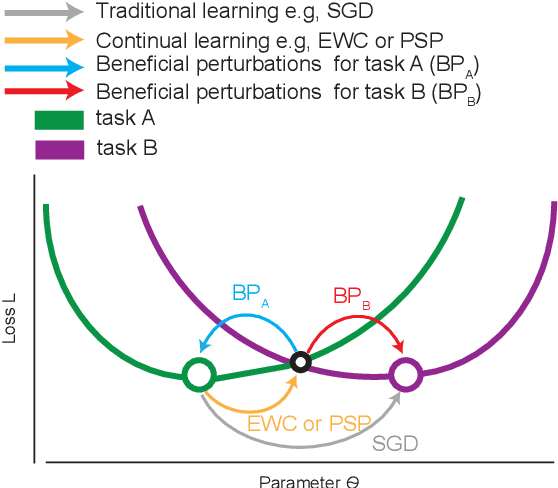
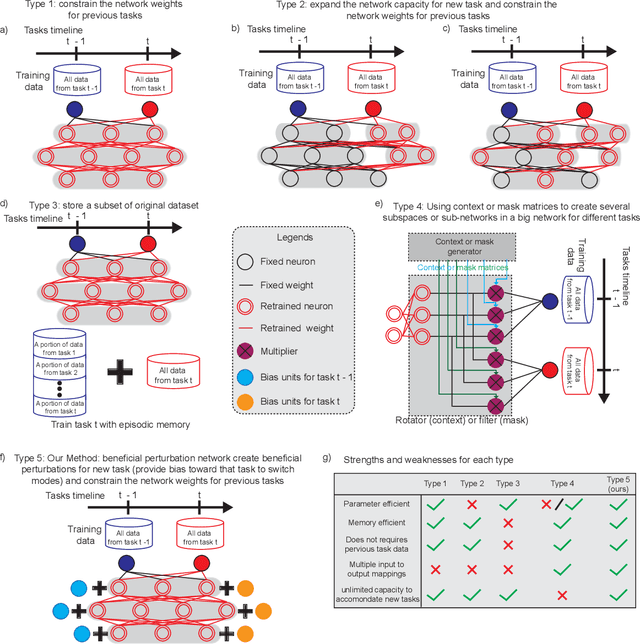
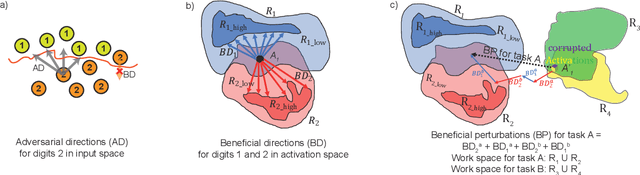
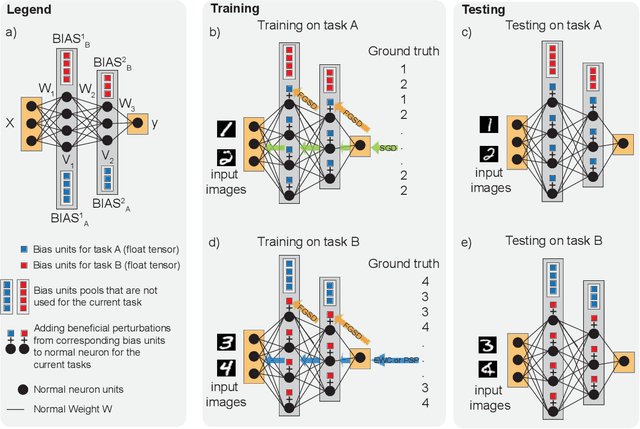
The human brain is the gold standard of adaptive learning. It not only can learn and benefit from experience, but also can adapt to new situations. In contrast, deep neural networks only learn one sophisticated but fixed mapping from inputs to outputs. This limits their applicability to more dynamic situations, where input to output mapping may change with different contexts. A salient example is continual learning - learning new independent tasks sequentially without forgetting previous tasks. Continual learning of multiple tasks in artificial neural networks using gradient descent leads to catastrophic forgetting, whereby a previously learned mapping of an old task is erased when learning new mappings for new tasks. Here, we propose a new biologically plausible type of deep neural network with extra, out-of-network, task-dependent biasing units to accommodate these dynamic situations. This allows, for the first time, a single network to learn potentially unlimited parallel input to output mappings, and to switch on the fly between them at runtime. Biasing units are programmed by leveraging beneficial perturbations (opposite to well-known adversarial perturbations) for each task. Beneficial perturbations for a given task bias the network toward that task, essentially switching the network into a different mode to process that task. This largely eliminates catastrophic interference between tasks. Our approach is memory-efficient and parameter-efficient, can accommodate many tasks, and achieves state-of-the-art performance across different tasks and domains.
Closed-Loop GAN for continual Learning
Nov 03, 2018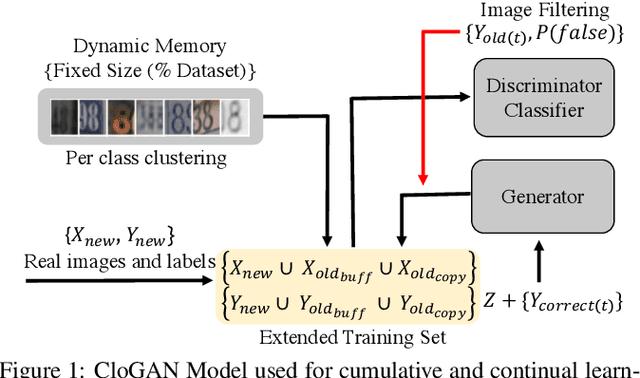


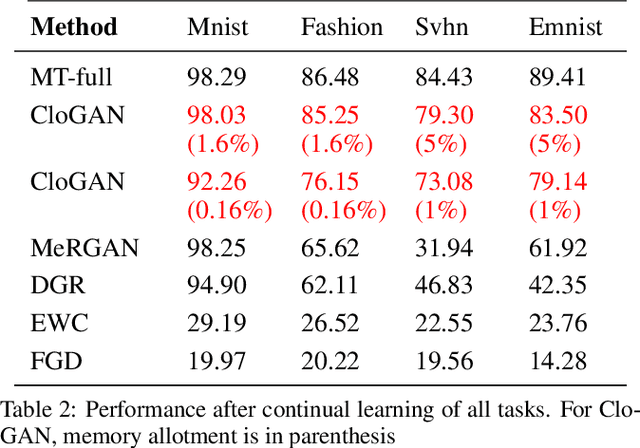
Sequential learning of tasks using gradient descent leads to an unremitting decline in the accuracy of tasks for which training data is no longer available, termed catastrophic forgetting. Generative models have been explored as a means to approximate the distribution of old tasks and bypass storage of real data. Here we propose a cumulative closed-loop generator and embedded classifier using an AC-GAN architecture provided with external regularization by a small buffer. We evaluate incremental learning using a notoriously hard paradigm, single headed learning, in which each task is a disjoint subset of classes in the overall dataset, and performance is evaluated on all previous classes. First, we show that the variability contained in a small percentage of a dataset (memory buffer) accounts for a significant portion of the reported accuracy, both in multi-task and continual learning settings. Second, we show that using a generator to continuously output new images while training provides an up-sampling of the buffer, which prevents catastrophic forgetting and yields superior performance when compared to a fixed buffer. We achieve an average accuracy for all classes of 92.26% in MNIST and 76.15% in FASHION-MNIST after 5 tasks using GAN sampling with a buffer of only 0.17% of the entire dataset size. We compare to a network with regularization (EWC) which shows a deteriorated average performance of 29.19% (MNIST) and 26.5% (FASHION). The baseline of no regularization (plain gradient descent) performs at 99.84% (MNIST) and 99.79% (FASHION) for the last task, but below 3% for all previous tasks. Our method has very low long-term memory cost, the buffer, as well as negligible intermediate memory storage.