 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-Loop GAN for continual Learning
Paper and Code
Nov 03, 2018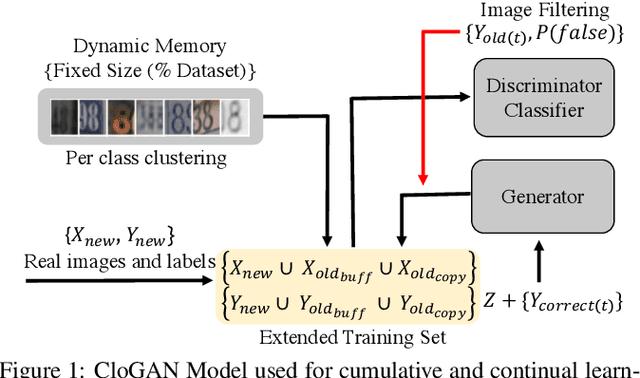


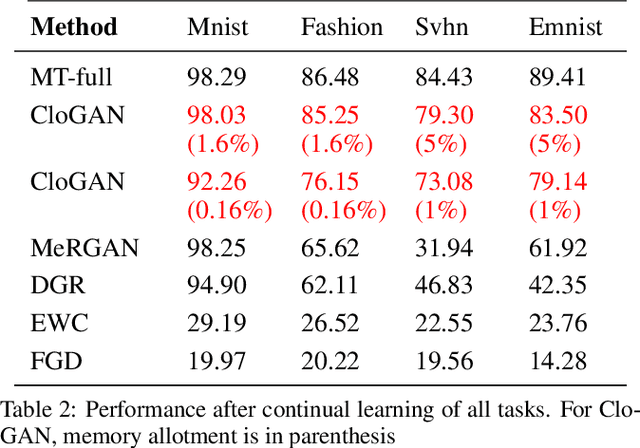
Sequential learning of tasks using gradient descent leads to an unremitting decline in the accuracy of tasks for which training data is no longer available, termed catastrophic forgetting. Generative models have been explored as a means to approximate the distribution of old tasks and bypass storage of real data. Here we propose a cumulative closed-loop generator and embedded classifier using an AC-GAN architecture provided with external regularization by a small buffer. We evaluate incremental learning using a notoriously hard paradigm, single headed learning, in which each task is a disjoint subset of classes in the overall dataset, and performance is evaluated on all previous classes. First, we show that the variability contained in a small percentage of a dataset (memory buffer) accounts for a significant portion of the reported accuracy, both in multi-task and continual learning settings. Second, we show that using a generator to continuously output new images while training provides an up-sampling of the buffer, which prevents catastrophic forgetting and yields superior performance when compared to a fixed buffer. We achieve an average accuracy for all classes of 92.26% in MNIST and 76.15% in FASHION-MNIST after 5 tasks using GAN sampling with a buffer of only 0.17% of the entire dataset size. We compare to a network with regularization (EWC) which shows a deteriorated average performance of 29.19% (MNIST) and 26.5% (FASHION). The baseline of no regularization (plain gradient descent) performs at 99.84% (MNIST) and 99.79% (FASHION) for the last task, but below 3% for all previous tasks. Our method has very low long-term memory cost, the buffer, as well as negligible intermediate memory storage.