 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerforated Backpropagation: A Neuroscience Inspired Extension to Artificial Neural Networks
Jan 29, 2025



The neurons of artificial neural networks were originally invented when much less was known about biological neurons than is known today. Our work explores a modification to the core neuron unit to make it more parallel to a biological neuron. The modification is made with the knowledge that biological dendrites are not simply passive activation funnels, but also compute complex non-linear functions as they transmit activation to the cell body. The paper explores a novel system of "Perforated" backpropagation empowering the artificial neurons of deep neural networks to achieve better performance coding for the same features they coded for in the original architecture. After an initial network training phase, additional "Dendrite Nodes" are added to the network and separately trained with a different objective: to correlate their output with the remaining error of the original neurons. The trained Dendrite Nodes are then frozen, and the original neurons are further trained, now taking into account the additional error signals provided by the Dendrite Nodes. The cycle of training the original neurons and then adding and training Dendrite Nodes can be repeated several times until satisfactory performance is achieved. Our algorithm was successfully added to modern state-of-the-art PyTorch networks across multiple domains, improving upon original accuracies and allowing for significant model compression without a loss in accuracy.
BEHAVIOR Vision Suite: Customizable Dataset Generation via Simulation
May 15, 2024



The systematic evaluation and understanding of computer vision models under varying conditions require large amounts of data with comprehensive and customized labels, which real-world vision datasets rarely satisfy. While current synthetic data generators offer a promising alternative, particularly for embodied AI tasks, they often fall short for computer vision tasks due to low asset and rendering quality, limited diversity, and unrealistic physical properties. We introduce the BEHAVIOR Vision Suite (BVS), a set of tools and assets to generate fully customized synthetic data for systematic evaluation of computer vision models, based on the newly developed embodied AI benchmark, BEHAVIOR-1K. BVS supports a large number of adjustable parameters at the scene level (e.g., lighting, object placement), the object level (e.g., joint configuration, attributes such as "filled" and "folded"), and the camera level (e.g., field of view, focal length). Researchers can arbitrarily vary these parameters during data generation to perform controlled experiments. We showcase three example application scenarios: systematically evaluating the robustness of models across different continuous axes of domain shift, evaluating scene understanding models on the same set of images, and training and evaluating simulation-to-real transfer for a novel vision task: unary and binary state prediction. Project website: https://behavior-vision-suite.github.io/
DreamDistribution: Prompt Distribution Learning for Text-to-Image Diffusion Models
Dec 21, 2023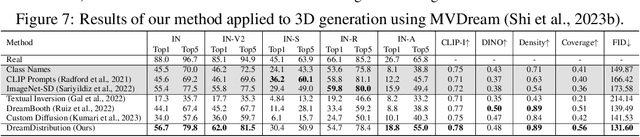
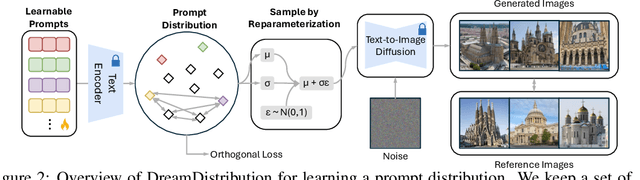
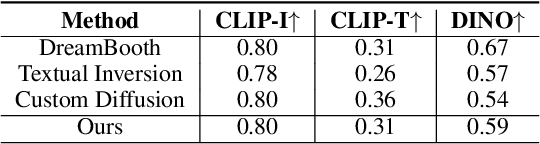

The popularization of Text-to-Image (T2I) diffusion models enables the generation of high-quality images from text descriptions. However, generating diverse customized images with reference visual attributes remains challenging. This work focuses on personalizing T2I diffusion models at a more abstract concept or category level, adapting commonalities from a set of reference images while creating new instances with sufficient variations. We introduce a solution that allows a pretrained T2I diffusion model to learn a set of soft prompts, enabling the generation of novel images by sampling prompts from the learned distribution. These prompts offer text-guided editing capabilities and additional flexibility in controlling variation and mixing between multiple distributions. We also show the adaptability of the learned prompt distribution to other tasks, such as text-to-3D. Finally we demonstrate effectiveness of our approach through quantitative analysis including automatic evaluation and human assessment. Project website: https://briannlongzhao.github.io/DreamDistribution
Value Explicit Pretraining for Goal-Based Transfer Learning
Dec 19, 2023



We propose a method that allows for learning task-agnostic representations based on value function estimates from a sequence of observations where the last frame corresponds to a goal. These representations would learn to relate states across different tasks, based on the temporal distance to the goal state, irrespective of the appearance changes and dynamics. This method could be used to transfer learnt policies/skills to unseen related tasks.
3D Copy-Paste: Physically Plausible Object Insertion for Monocular 3D Detection
Dec 08, 2023

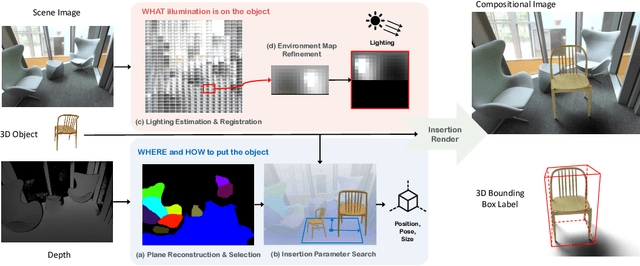

A major challenge in monocular 3D object detection is the limited diversity and quantity of objects in real datasets. While augmenting real scenes with virtual objects holds promise to improve both the diversity and quantity of the objects, it remains elusive due to the lack of an effective 3D object insertion method in complex real captured scenes. In this work, we study augmenting complex real indoor scenes with virtual objects for monocular 3D object detection. The main challenge is to automatically identify plausible physical properties for virtual assets (e.g., locations, appearances, sizes, etc.) in cluttered real scenes. To address this challenge, we propose a physically plausible indoor 3D object insertion approach to automatically copy virtual objects and paste them into real scenes. The resulting objects in scenes have 3D bounding boxes with plausible physical locations and appearances. In particular, our method first identifies physically feasible locations and poses for the inserted objects to prevent collisions with the existing room layout. Subsequently, it estimates spatially-varying illumination for the insertion location, enabling the immersive blending of the virtual objects into the original scene with plausible appearances and cast shadows. We show that our augmentation method significantly improves existing monocular 3D object models and achieves state-of-the-art performance. For the first time, we demonstrate that a physically plausible 3D object insertion, serving as a generative data augmentation technique, can lead to significant improvements for discriminative downstream tasks such as monocular 3D object detection. Project website: https://gyhandy.github.io/3D-Copy-Paste/
Evaluating Pretrained models for Deployable Lifelong Learning
Nov 22, 2023We create a novel benchmark for evaluating a Deployable Lifelong Learning system for Visual Reinforcement Learning (RL) that is pretrained on a curated dataset, and propose a novel Scalable Lifelong Learning system capable of retaining knowledge from the previously learnt RL tasks. Our benchmark measures the efficacy of a deployable Lifelong Learning system that is evaluated on scalability, performance and resource utilization. Our proposed system, once pretrained on the dataset, can be deployed to perform continual learning on unseen tasks. Our proposed method consists of a Few Shot Class Incremental Learning (FSCIL) based task-mapper and an encoder/backbone trained entirely using the pretrain dataset. The policy parameters corresponding to the recognized task are then loaded to perform the task. We show that this system can be scaled to incorporate a large number of tasks due to the small memory footprint and fewer computational resources. We perform experiments on our DeLL (Deployment for Lifelong Learning) benchmark on the Atari games to determine the efficacy of the system.
World Model Based Sim2Real Transfer for Visual Navigation
Oct 28, 2023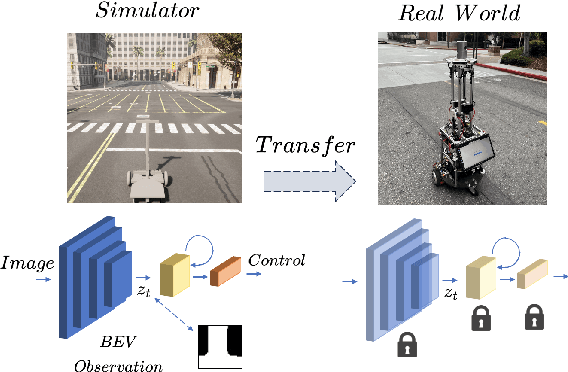
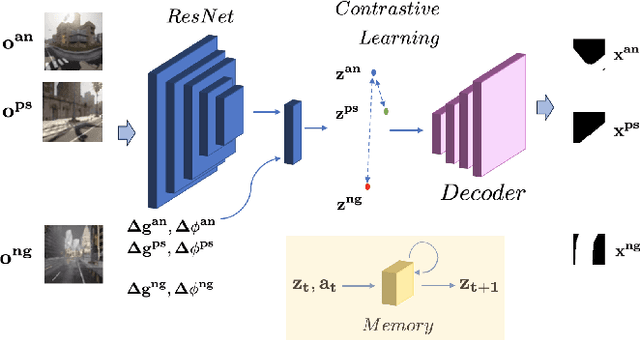
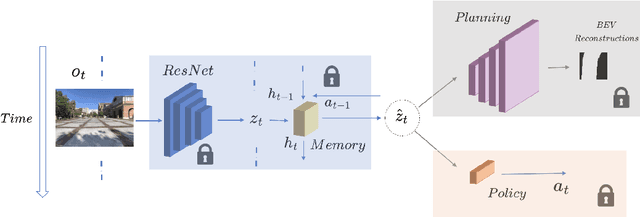
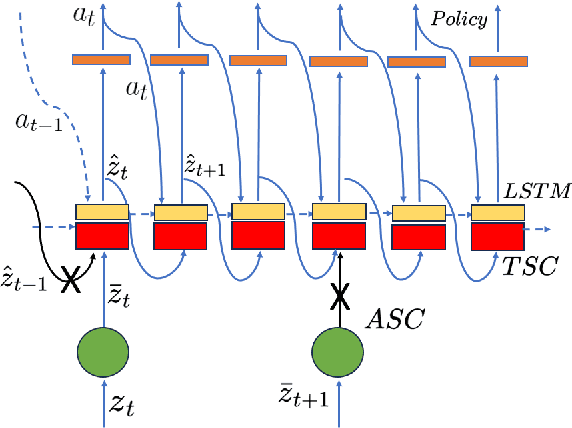
Sim2Real transfer has gained popularity because it helps transfer from inexpensive simulators to real world. This paper presents a novel system that fuses components in a traditional \textit{World Model} into a robust system, trained entirely within a simulator, that \textit{Zero-Shot} transfers to the real world. To facilitate transfer, we use an intermediary representation that are based on \textit{Bird's Eye View (BEV)} images. Thus, our robot learns to navigate in a simulator by first learning to translate from complex \textit{First-Person View (FPV)} based RGB images to BEV representations, then learning to navigate using those representations. Later, when tested in the real world, the robot uses the perception model that translates FPV-based RGB images to embeddings that are used by the downstream policy. The incorporation of state-checking modules using \textit{Anchor images} and \textit{Mixture Density LSTM} not only interpolates uncertain and missing observations but also enhances the robustness of the model when exposed to the real-world environment. We trained the model using data collected using a \textit{Differential drive} robot in the CARLA simulator. Our methodology's effectiveness is shown through the deployment of trained models onto a \textit{Real world Differential drive} robot. Lastly we release a comprehensive codebase, dataset and models for training and deployment that are available to the public.
RoboCLIP: One Demonstration is Enough to Learn Robot Policies
Oct 11, 2023



Reward specification is a notoriously difficult problem in reinforcement learning, requiring extensive expert supervision to design robust reward functions. Imitation learning (IL) methods attempt to circumvent these problems by utilizing expert demonstrations but typically require a large number of in-domain expert demonstrations. Inspired by advances in the field of Video-and-Language Models (VLMs), we present RoboCLIP, an online imitation learning method that uses a single demonstration (overcoming the large data requirement) in the form of a video demonstration or a textual description of the task to generate rewards without manual reward function design. Additionally, RoboCLIP can also utilize out-of-domain demonstrations, like videos of humans solving the task for reward generation, circumventing the need to have the same demonstration and deployment domains. RoboCLIP utilizes pretrained VLMs without any finetuning for reward generation. Reinforcement learning agents trained with RoboCLIP rewards demonstrate 2-3 times higher zero-shot performance than competing imitation learning methods on downstream robot manipulation tasks, doing so using only one video/text demonstration.
Beyond Generation: Harnessing Text to Image Models for Object Detection and Segmentation
Sep 12, 2023



We propose a new paradigm to automatically generate training data with accurate labels at scale using the text-to-image synthesis frameworks (e.g., DALL-E, Stable Diffusion, etc.). The proposed approach1 decouples training data generation into foreground object generation, and contextually coherent background generation. To generate foreground objects, we employ a straightforward textual template, incorporating the object class name as input prompts. This is fed into a text-to-image synthesis framework, producing various foreground images set against isolated backgrounds. A foreground-background segmentation algorithm is then used to generate foreground object masks. To generate context images, we begin by creating language descriptions of the context. This is achieved by applying an image captioning method to a small set of images representing the desired context. These textual descriptions are then transformed into a diverse array of context images via a text-to-image synthesis framework. Subsequently, we composite these with the foreground object masks produced in the initial step, utilizing a cut-and-paste method, to formulate the training data. We demonstrate the advantages of our approach on five object detection and segmentation datasets, including Pascal VOC and COCO. We found that detectors trained solely on synthetic data produced by our method achieve performance comparable to those trained on real data (Fig. 1). Moreover, a combination of real and synthetic data yields even much better results. Further analysis indicates that the synthetic data distribution complements the real data distribution effectively. Additionally, we emphasize the compositional nature of our data generation approach in out-of-distribution and zero-shot data generation scenarios. We open-source our code at https://github.com/gyhandy/Text2Image-for-Detection
CLR: Channel-wise Lightweight Reprogramming for Continual Learning
Jul 21, 2023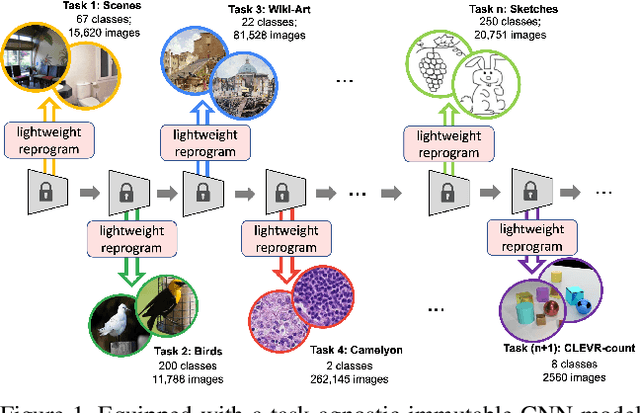

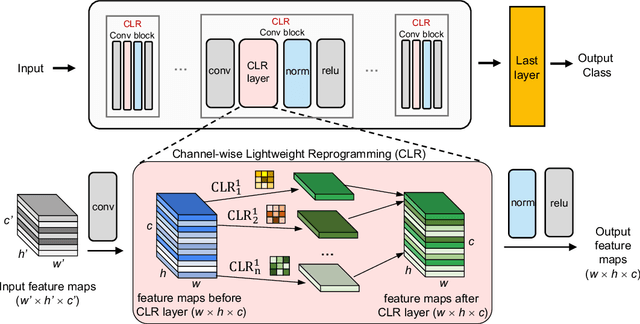
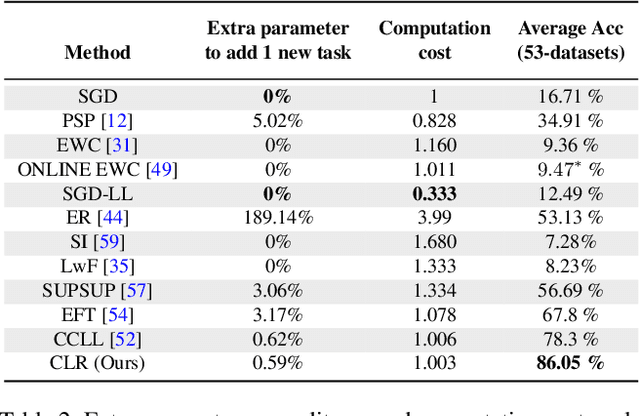
Continual learning aims to emulate the human ability to continually accumulate knowledge over sequential tasks. The main challenge is to maintain performance on previously learned tasks after learning new tasks, i.e., to avoid catastrophic forgetting. We propose a Channel-wise Lightweight Reprogramming (CLR) approach that helps convolutional neural networks (CNNs) overcome catastrophic forgetting during continual learning. We show that a CNN model trained on an old task (or self-supervised proxy task) could be ``reprogrammed" to solve a new task by using our proposed lightweight (very cheap) reprogramming parameter. With the help of CLR, we have a better stability-plasticity trade-off to solve continual learning problems: To maintain stability and retain previous task ability, we use a common task-agnostic immutable part as the shared ``anchor" parameter set. We then add task-specific lightweight reprogramming parameters to reinterpret the outputs of the immutable parts, to enable plasticity and integrate new knowledge. To learn sequential tasks, we only train the lightweight reprogramming parameters to learn each new task. Reprogramming parameters are task-specific and exclusive to each task, which makes our method immune to catastrophic forgetting. To minimize the parameter requirement of reprogramming to learn new tasks, we make reprogramming lightweight by only adjusting essential kernels and learning channel-wise linear mappings from anchor parameters to task-specific domain knowledge. We show that, for general CNNs, the CLR parameter increase is less than 0.6\% for any new task. Our method outperforms 13 state-of-the-art continual learning baselines on a new challenging sequence of 53 image classification datasets. Code and data are available at https://github.com/gyhandy/Channel-wise-Lightweight-Reprogramming