 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Prompt Distribution Learning for Animal Pose Estimation
Mar 20, 2025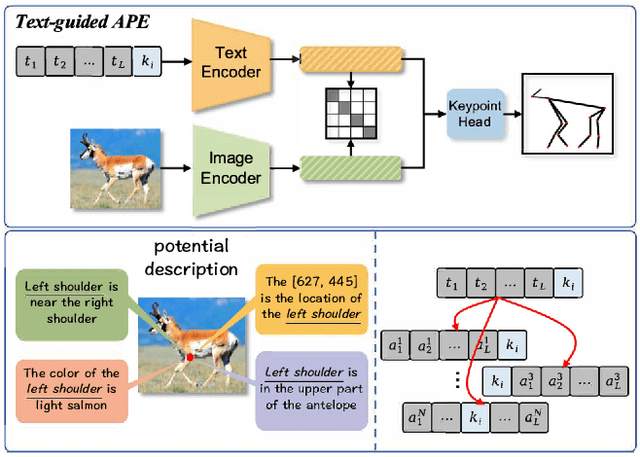
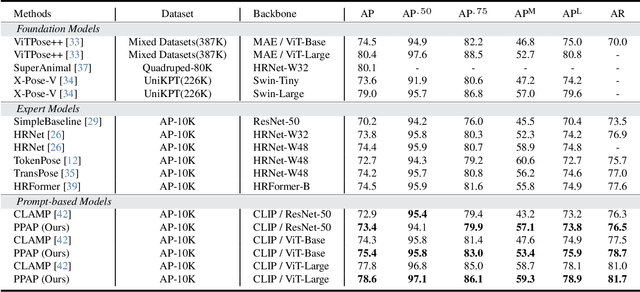
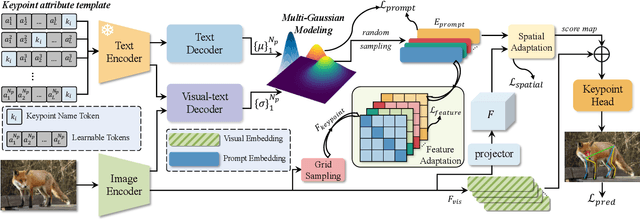

Multi-species animal pose estimation has emerged as a challenging yet critical task, hindered by substantial visual diversity and uncertainty. This paper challenges the problem by efficient prompt learning for Vision-Language Pretrained (VLP) models, \textit{e.g.} CLIP, aiming to resolve the cross-species generalization problem. At the core of the solution lies in the prompt designing, probabilistic prompt modeling and cross-modal adaptation, thereby enabling prompts to compensate for cross-modal information and effectively overcome large data variances under unbalanced data distribution. To this end, we propose a novel probabilistic prompting approach to fully explore textual descriptions, which could alleviate the diversity issues caused by long-tail property and increase the adaptability of prompts on unseen category instance. Specifically, we first introduce a set of learnable prompts and propose a diversity loss to maintain distinctiveness among prompts, thus representing diverse image attributes. Diverse textual probabilistic representations are sampled and used as the guidance for the pose estimation. Subsequently, we explore three different cross-modal fusion strategies at spatial level to alleviate the adverse impacts of visual uncertainty. Extensive experiments on multi-species animal pose benchmarks show that our method achieves the state-of-the-art performance under both supervised and zero-shot settings. The code is available at https://github.com/Raojiyong/PPAP.
DreamDistribution: Prompt Distribution Learning for Text-to-Image Diffusion Models
Dec 21, 2023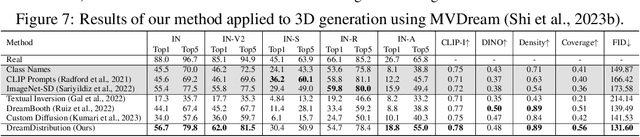
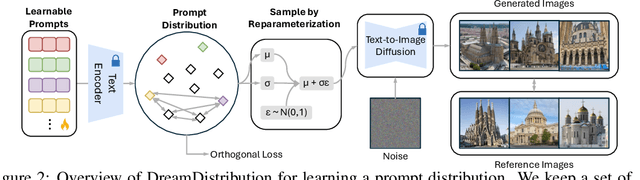
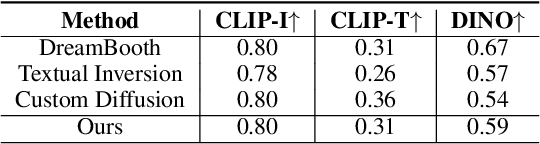

The popularization of Text-to-Image (T2I) diffusion models enables the generation of high-quality images from text descriptions. However, generating diverse customized images with reference visual attributes remains challenging. This work focuses on personalizing T2I diffusion models at a more abstract concept or category level, adapting commonalities from a set of reference images while creating new instances with sufficient variations. We introduce a solution that allows a pretrained T2I diffusion model to learn a set of soft prompts, enabling the generation of novel images by sampling prompts from the learned distribution. These prompts offer text-guided editing capabilities and additional flexibility in controlling variation and mixing between multiple distributions. We also show the adaptability of the learned prompt distribution to other tasks, such as text-to-3D. Finally we demonstrate effectiveness of our approach through quantitative analysis including automatic evaluation and human assessment. Project website: https://briannlongzhao.github.io/DreamDistribution
Beyond Generation: Harnessing Text to Image Models for Object Detection and Segmentation
Sep 12, 2023



We propose a new paradigm to automatically generate training data with accurate labels at scale using the text-to-image synthesis frameworks (e.g., DALL-E, Stable Diffusion, etc.). The proposed approach1 decouples training data generation into foreground object generation, and contextually coherent background generation. To generate foreground objects, we employ a straightforward textual template, incorporating the object class name as input prompts. This is fed into a text-to-image synthesis framework, producing various foreground images set against isolated backgrounds. A foreground-background segmentation algorithm is then used to generate foreground object masks. To generate context images, we begin by creating language descriptions of the context. This is achieved by applying an image captioning method to a small set of images representing the desired context. These textual descriptions are then transformed into a diverse array of context images via a text-to-image synthesis framework. Subsequently, we composite these with the foreground object masks produced in the initial step, utilizing a cut-and-paste method, to formulate the training data. We demonstrate the advantages of our approach on five object detection and segmentation datasets, including Pascal VOC and COCO. We found that detectors trained solely on synthetic data produced by our method achieve performance comparable to those trained on real data (Fig. 1). Moreover, a combination of real and synthetic data yields even much better results. Further analysis indicates that the synthetic data distribution complements the real data distribution effectively. Additionally, we emphasize the compositional nature of our data generation approach in out-of-distribution and zero-shot data generation scenarios. We open-source our code at https://github.com/gyhandy/Text2Image-for-Detection
EM-Paste: EM-guided Cut-Paste with DALL-E Augmentation for Image-level Weakly Supervised Instance Segmentation
Dec 15, 2022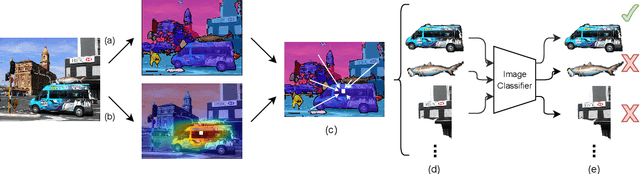
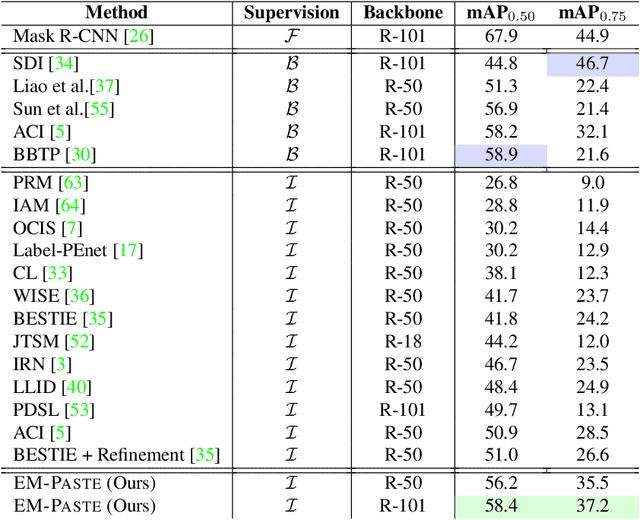
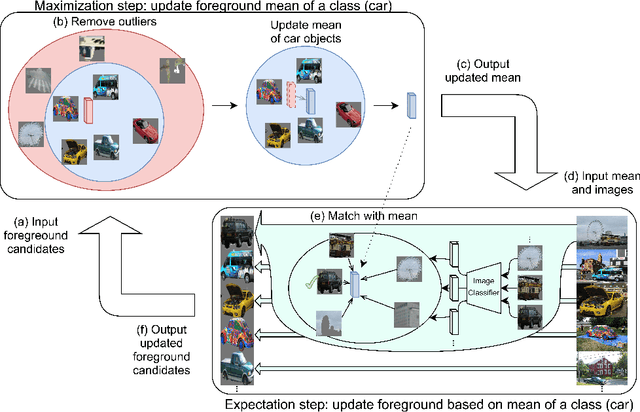
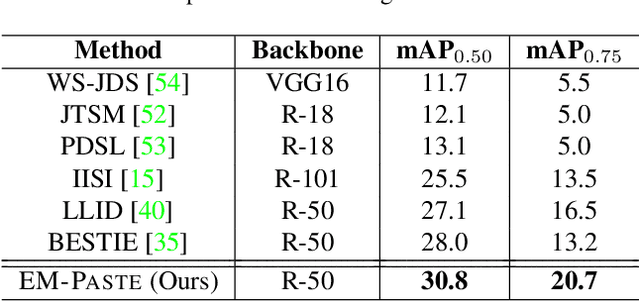
We propose EM-PASTE: an Expectation Maximization(EM) guided Cut-Paste compositional dataset augmentation approach for weakly-supervised instance segmentation using only image-level supervision. The proposed method consists of three main components. The first component generates high-quality foreground object masks. To this end, an EM-like approach is proposed that iteratively refines an initial set of object mask proposals generated by a generic region proposal method. Next, in the second component, high-quality context-aware background images are generated using a text-to-image compositional synthesis method like DALL-E. Finally, the third component creates a large-scale pseudo-labeled instance segmentation training dataset by compositing the foreground object masks onto the original and generated background images. The proposed approach achieves state-of-the-art weakly-supervised instance segmentation results on both the PASCAL VOC 2012 and MS COCO datasets by using only image-level, weak label information. In particular, it outperforms the best baseline by +7.4 and +2.8 mAP0.50 on PASCAL and COCO, respectively. Further, the method provides a new solution to the long-tail weakly-supervised instance segmentation problem (when many classes may only have few training samples), by selectively augmenting under-represented classes.
DALL-E for Detection: Language-driven Context Image Synthesis for Object Detection
Jun 20, 2022
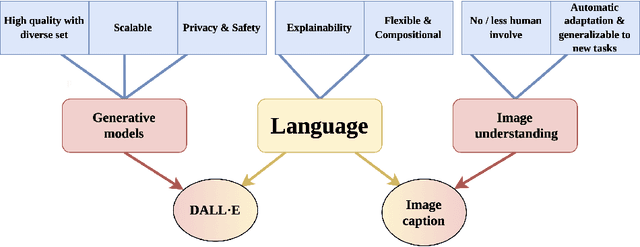


Object cut-and-paste has become a promising approach to efficiently generate large sets of labeled training data. It involves compositing foreground object masks onto background images. The background images, when congruent with the objects, provide helpful context information for training object recognition models. While the approach can easily generate large labeled data, finding congruent context images for downstream tasks has remained an elusive problem. In this work, we propose a new paradigm for automatic context image generation at scale. At the core of our approach lies utilizing an interplay between language description of context and language-driven image generation. Language description of a context is provided by applying an image captioning method on a small set of images representing the context. These language descriptions are then used to generate diverse sets of context images using the language-based DALL-E image generation framework. These are then composited with objects to provide an augmented training set for a classifier. We demonstrate the advantages of our approach over the prior context image generation approaches on four object detection datasets. Furthermore, we also highlight the compositional nature of our data generation approach on out-of-distribution and zero-shot data generation scenarios.