 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Prompt Distribution Learning for Animal Pose Estimation
Mar 20, 2025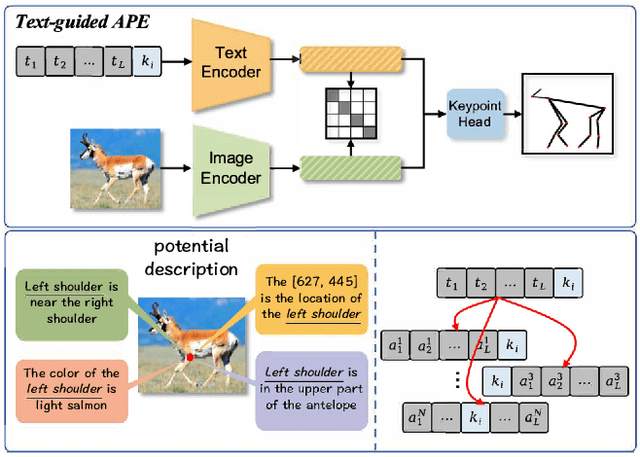
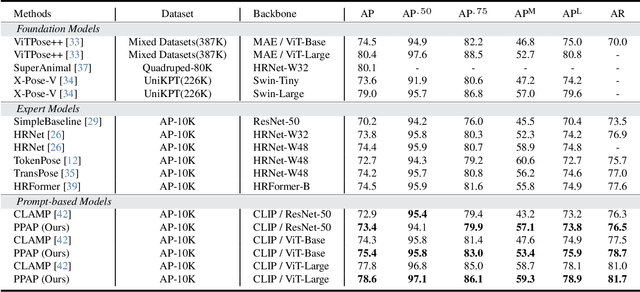
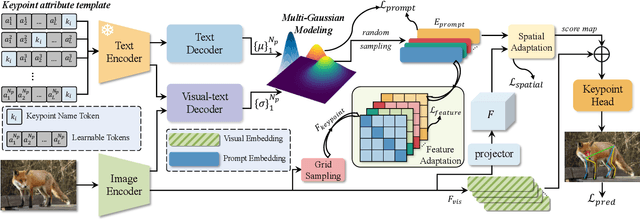

Multi-species animal pose estimation has emerged as a challenging yet critical task, hindered by substantial visual diversity and uncertainty. This paper challenges the problem by efficient prompt learning for Vision-Language Pretrained (VLP) models, \textit{e.g.} CLIP, aiming to resolve the cross-species generalization problem. At the core of the solution lies in the prompt designing, probabilistic prompt modeling and cross-modal adaptation, thereby enabling prompts to compensate for cross-modal information and effectively overcome large data variances under unbalanced data distribution. To this end, we propose a novel probabilistic prompting approach to fully explore textual descriptions, which could alleviate the diversity issues caused by long-tail property and increase the adaptability of prompts on unseen category instance. Specifically, we first introduce a set of learnable prompts and propose a diversity loss to maintain distinctiveness among prompts, thus representing diverse image attributes. Diverse textual probabilistic representations are sampled and used as the guidance for the pose estimation. Subsequently, we explore three different cross-modal fusion strategies at spatial level to alleviate the adverse impacts of visual uncertainty. Extensive experiments on multi-species animal pose benchmarks show that our method achieves the state-of-the-art performance under both supervised and zero-shot settings. The code is available at https://github.com/Raojiyong/PPAP.
Learning Structure-Supporting Dependencies via Keypoint Interactive Transformer for General Mammal Pose Estimation
Feb 25, 2025General mammal pose estimation is an important and challenging task in computer vision, which is essential for understanding mammal behaviour in real-world applications. However, existing studies are at their preliminary research stage, which focus on addressing the problem for only a few specific mammal species. In principle, from specific to general mammal pose estimation, the biggest issue is how to address the huge appearance and pose variances for different species. We argue that given appearance context, instance-level prior and the structural relation among keypoints can serve as complementary evidence. To this end, we propose a Keypoint Interactive Transformer (KIT) to learn instance-level structure-supporting dependencies for general mammal pose estimation. Specifically, our KITPose consists of two coupled components. The first component is to extract keypoint features and generate body part prompts. The features are supervised by a dedicated generalised heatmap regression loss (GHRL). Instead of introducing external visual/text prompts, we devise keypoints clustering to generate body part biases, aligning them with image context to generate corresponding instance-level prompts. Second, we propose a novel interactive transformer that takes feature slices as input tokens without performing spatial splitting. In addition, to enhance the capability of the KIT model, we design an adaptive weight strategy to address the imbalance issue among different keypoints.