 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwinSRGAN: Swin Transformer-based Generative Adversarial Network for High-Fidelity Speech Super-Resolution
Sep 04, 2025Speech super-resolution (SR) reconstructs high-frequency content from low-resolution speech signals. Existing systems often suffer from representation mismatch in two-stage mel-vocoder pipelines and from over-smoothing of hallucinated high-band content by CNN-only generators. Diffusion and flow models are computationally expensive, and their robustness across domains and sampling rates remains limited. We propose SwinSRGAN, an end-to-end framework operating on Modified Discrete Cosine Transform (MDCT) magnitudes. It is a Swin Transformer-based U-Net that captures long-range spectro-temporal dependencies with a hybrid adversarial scheme combines time-domain MPD/MSD discriminators with a multi-band MDCT discriminator specialized for the high-frequency band. We employs a sparse-aware regularizer on arcsinh-compressed MDCT to better preserve transient components. The system upsamples inputs at various sampling rates to 48 kHz in a single pass and operates in real time. On standard benchmarks, SwinSRGAN reduces objective error and improves ABX preference scores. In zero-shot tests on HiFi-TTS without fine-tuning, it outperforms NVSR and mdctGAN, demonstrating strong generalization across datasets
DreamDistribution: Prompt Distribution Learning for Text-to-Image Diffusion Models
Dec 21, 2023
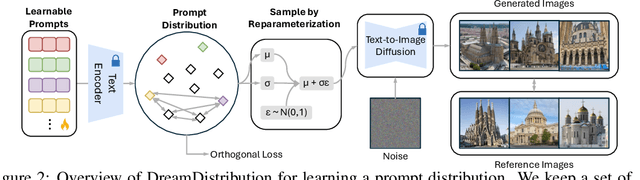
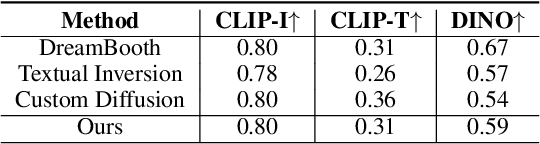

The popularization of Text-to-Image (T2I) diffusion models enables the generation of high-quality images from text descriptions. However, generating diverse customized images with reference visual attributes remains challenging. This work focuses on personalizing T2I diffusion models at a more abstract concept or category level, adapting commonalities from a set of reference images while creating new instances with sufficient variations. We introduce a solution that allows a pretrained T2I diffusion model to learn a set of soft prompts, enabling the generation of novel images by sampling prompts from the learned distribution. These prompts offer text-guided editing capabilities and additional flexibility in controlling variation and mixing between multiple distributions. We also show the adaptability of the learned prompt distribution to other tasks, such as text-to-3D. Finally we demonstrate effectiveness of our approach through quantitative analysis including automatic evaluation and human assessment. Project website: https://briannlongzhao.github.io/DreamDistribution
One-bit Spectrum Sensing with the Eigenvalue Moment Ratio Approach
Apr 08, 2021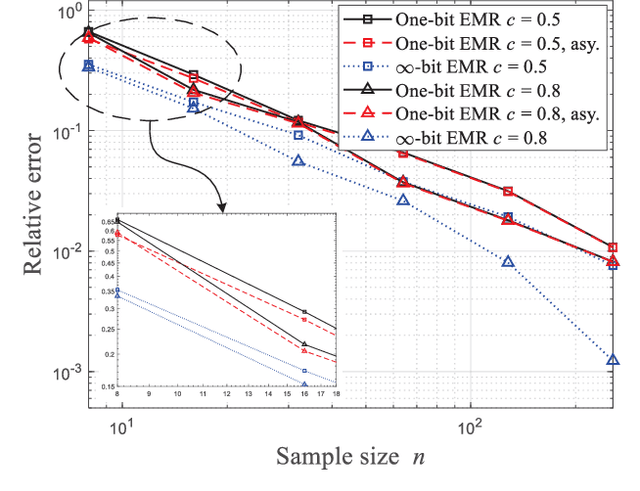
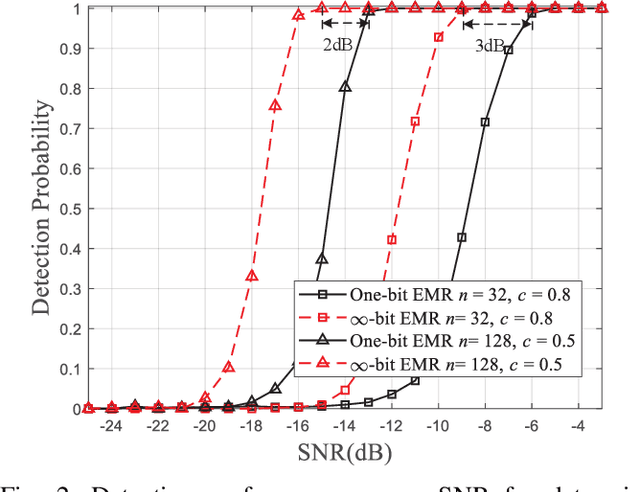

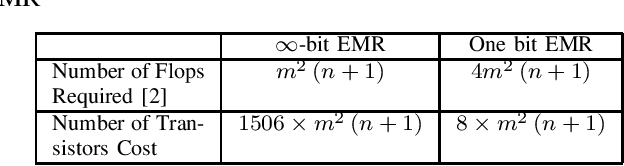
One-bit analog-to-digital converter (ADC), performing signal sampling as an extreme simple comparator, is an overwhelming technology for spectrum sensing due to its low-cost, low-power consumptions and high sampling rate. In this letter, we propose a novel one-bit sensing approach based on the eigenvalue moment ratio (EMR), which has been proved to be highly efficient for conventional multi-antenna spectrum sensing in $\infty$-bit situation. Particularly, we determine the asymptotic distribution of one-bit EMR under null hypothesis via the central limited theorem (CLT), allowing us to perform spectrum sensing with one-bit samples directly. Theoretical and simulation analysis show the new approach can provide reasonably good sensing performance at a low hardware cost.