 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLR: Channel-wise Lightweight Reprogramming for Continual Learning
Jul 21, 2023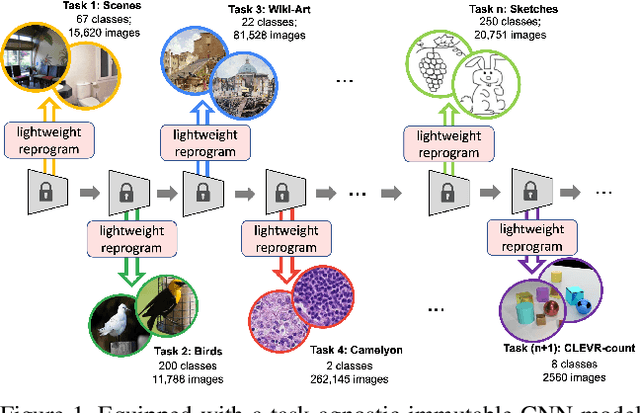

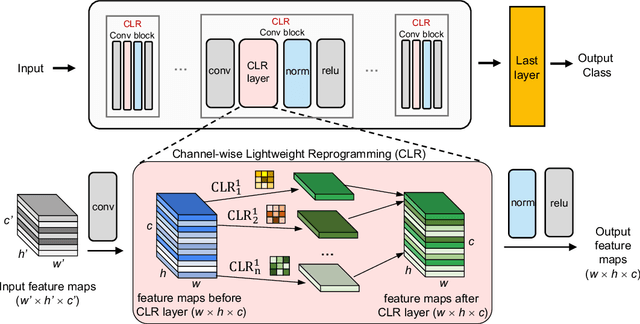
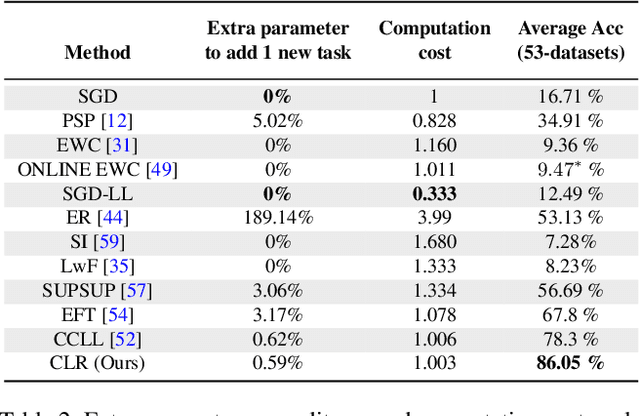
Continual learning aims to emulate the human ability to continually accumulate knowledge over sequential tasks. The main challenge is to maintain performance on previously learned tasks after learning new tasks, i.e., to avoid catastrophic forgetting. We propose a Channel-wise Lightweight Reprogramming (CLR) approach that helps convolutional neural networks (CNNs) overcome catastrophic forgetting during continual learning. We show that a CNN model trained on an old task (or self-supervised proxy task) could be ``reprogrammed" to solve a new task by using our proposed lightweight (very cheap) reprogramming parameter. With the help of CLR, we have a better stability-plasticity trade-off to solve continual learning problems: To maintain stability and retain previous task ability, we use a common task-agnostic immutable part as the shared ``anchor" parameter set. We then add task-specific lightweight reprogramming parameters to reinterpret the outputs of the immutable parts, to enable plasticity and integrate new knowledge. To learn sequential tasks, we only train the lightweight reprogramming parameters to learn each new task. Reprogramming parameters are task-specific and exclusive to each task, which makes our method immune to catastrophic forgetting. To minimize the parameter requirement of reprogramming to learn new tasks, we make reprogramming lightweight by only adjusting essential kernels and learning channel-wise linear mappings from anchor parameters to task-specific domain knowledge. We show that, for general CNNs, the CLR parameter increase is less than 0.6\% for any new task. Our method outperforms 13 state-of-the-art continual learning baselines on a new challenging sequence of 53 image classification datasets. Code and data are available at https://github.com/gyhandy/Channel-wise-Lightweight-Reprogramming
Building One-class Detector for Anything: Open-vocabulary Zero-shot OOD Detection Using Text-image Models
May 26, 2023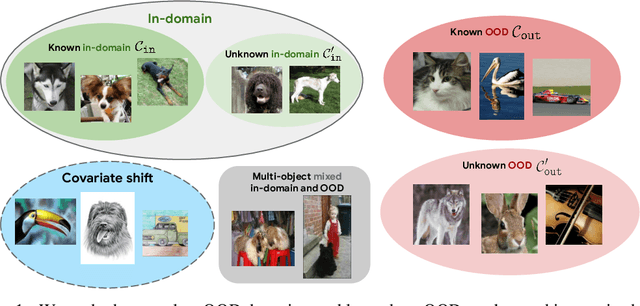

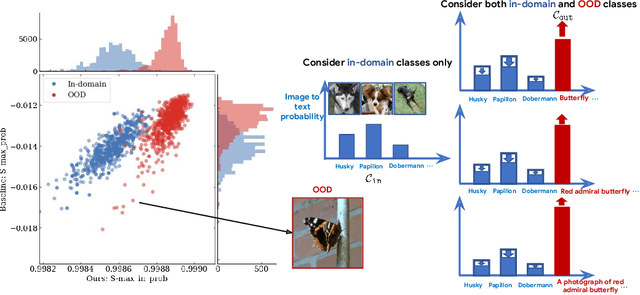
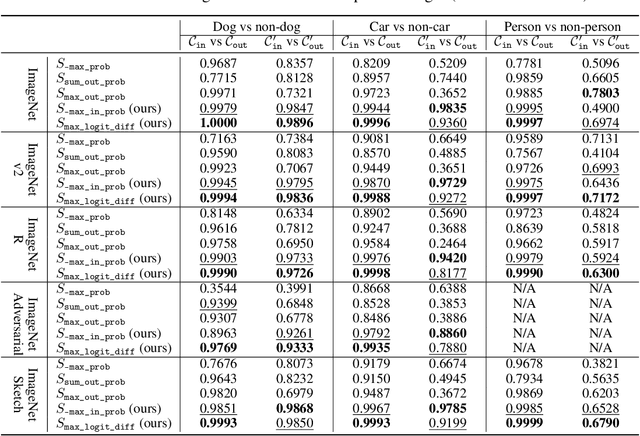
We focus on the challenge of out-of-distribution (OOD) detection in deep learning models, a crucial aspect in ensuring reliability. Despite considerable effort, the problem remains significantly challenging in deep learning models due to their propensity to output over-confident predictions for OOD inputs. We propose a novel one-class open-set OOD detector that leverages text-image pre-trained models in a zero-shot fashion and incorporates various descriptions of in-domain and OOD. Our approach is designed to detect anything not in-domain and offers the flexibility to detect a wide variety of OOD, defined via fine- or coarse-grained labels, or even in natural language. We evaluate our approach on challenging benchmarks including large-scale datasets containing fine-grained, semantically similar classes, distributionally shifted images, and multi-object images containing a mixture of in-domain and OOD objects. Our method shows superior performance over previous methods on all benchmarks. Code is available at https://github.com/gyhandy/One-Class-Anything
Improving Zero-shot Generalization and Robustness of Multi-modal Models
Dec 04, 2022



Multi-modal image-text models such as CLIP and LiT have demonstrated impressive performance on image classification benchmarks and their zero-shot generalization ability is particularly exciting. While the top-5 zero-shot accuracies of these models are very high, the top-1 accuracies are much lower (over 25% gap in some cases). We investigate the reasons for this performance gap and find that many of the failure cases are caused by ambiguity in the text prompts. First, we develop a simple and efficient zero-shot post-hoc method to identify images whose top-1 prediction is likely to be incorrect, by measuring consistency of the predictions w.r.t. multiple prompts and image transformations. We show that our procedure better predicts mistakes, outperforming the popular max logit baseline on selective prediction tasks. Next, we propose a simple and efficient way to improve accuracy on such uncertain images by making use of the WordNet hierarchy; specifically we augment the original class by incorporating its parent and children from the semantic label hierarchy, and plug the augmentation into text promts. We conduct experiments on both CLIP and LiT models with five different ImageNet-based datasets. For CLIP, our method improves the top-1 accuracy by 17.13% on the uncertain subset and 3.6% on the entire ImageNet validation set. We also show that our method improves across ImageNet shifted datasets and other model architectures such as LiT. Our proposed method is hyperparameter-free, requires no additional model training and can be easily scaled to other large multi-modal architectures.
Learning View-Disentangled Human Pose Representation by Contrastive Cross-View Mutual Information Maximization
Dec 02, 2020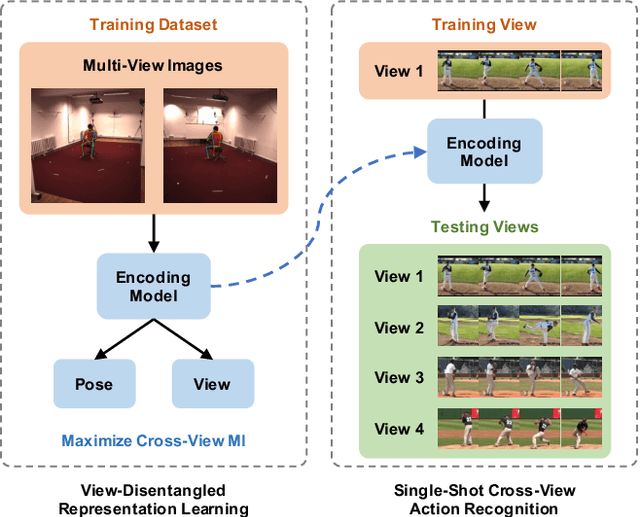
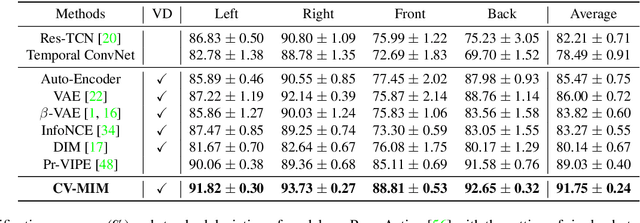
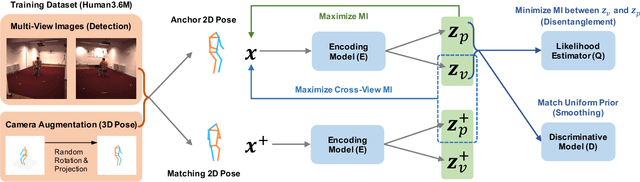
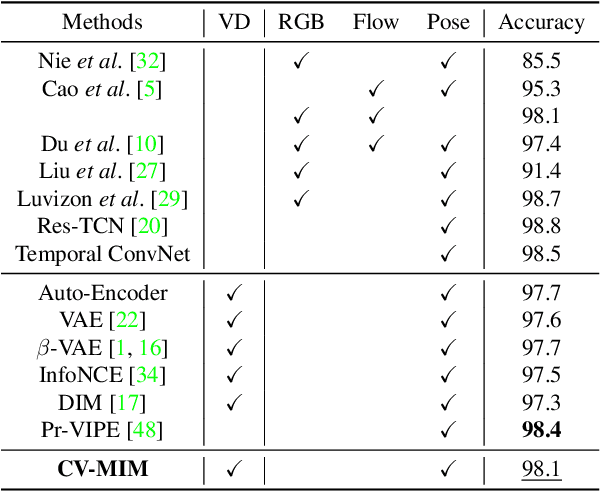
We introduce a novel representation learning method to disentangle pose-dependent as well as view-dependent factors from 2D human poses. The method trains a network using cross-view mutual information maximization (CV-MIM) which maximizes mutual information of the same pose performed from different viewpoints in a contrastive learning manner. We further propose two regularization terms to ensure disentanglement and smoothness of the learned representations. The resulting pose representations can be used for cross-view action recognition. To evaluate the power of the learned representations, in addition to the conventional fully-supervised action recognition settings, we introduce a novel task called single-shot cross-view action recognition. This task trains models with actions from only one single viewpoint while models are evaluated on poses captured from all possible viewpoints. We evaluate the learned representations on standard benchmarks for action recognition, and show that (i) CV-MIM performs competitively compared with the state-of-the-art models in the fully-supervised scenarios; (ii) CV-MIM outperforms other competing methods by a large margin in the single-shot cross-view setting; (iii) and the learned representations can significantly boost the performance when reducing the amount of supervised training data.
View-Invariant, Occlusion-Robust Probabilistic Embedding for Human Pose
Oct 23, 2020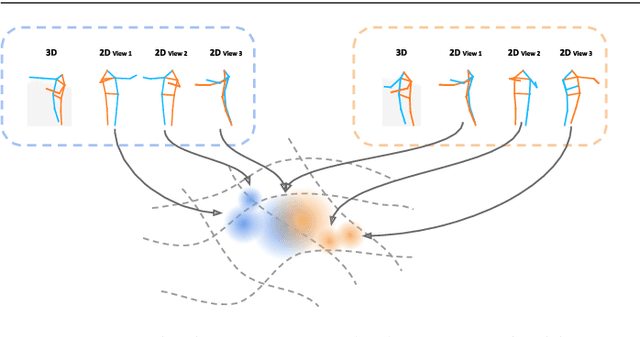
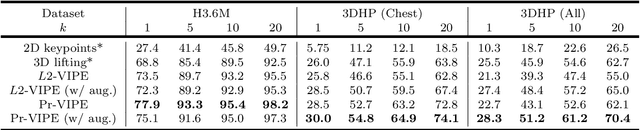
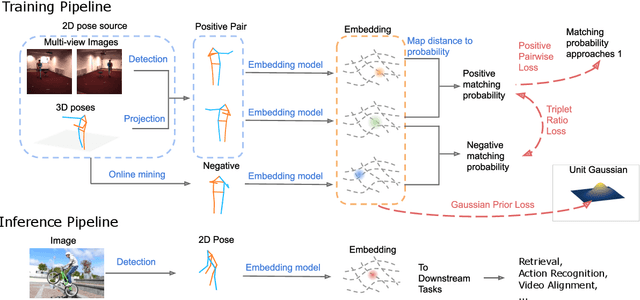

Recognition of human poses and activities is crucial for autonomous systems to interact smoothly with people. However, cameras generally capture human poses in 2D as images and videos, which can have significant appearance variations across viewpoints. To address this, we explore recognizing similarity in 3D human body poses from 2D information, which has not been well-studied in existing works. Here, we propose an approach to learning a compact view-invariant embedding space from 2D body joint keypoints, without explicitly predicting 3D poses. Input ambiguities of 2D poses from projection and occlusion are difficult to represent through a deterministic mapping, and therefore we use probabilistic embeddings. In order to enable our embeddings to work with partially visible input keypoints, we further investigate different keypoint occlusion augmentation strategies during training. Experimental results show that our embedding model achieves higher accuracy when retrieving similar poses across different camera views, in comparison with 3D pose estimation models. We further show that keypoint occlusion augmentation during training significantly improves retrieval performance on partial 2D input poses. Results on action recognition and video alignment demonstrate that our embeddings, without any additional training, achieves competitive performance relative to other models specifically trained for each task.
Pose Augmentation: Class-agnostic Object Pose Transformation for Object Recognition
Mar 19, 2020


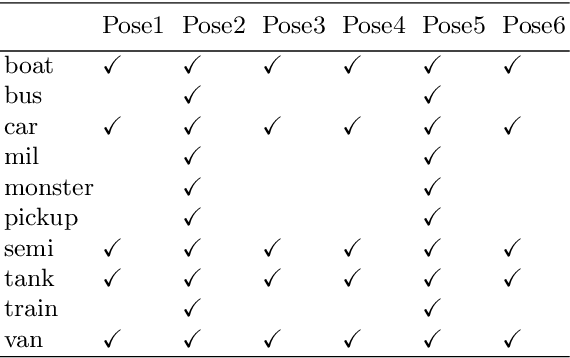
Object pose increases interclass object variance which makes object recognition from 2D images harder. To render a classifier robust to pose variations, most deep neural networks try to eliminate the influence of pose by using large datasets with many poses for each class. Here, we propose a different approach: a class-agnostic object pose transformation network (OPT-Net) can transform an image along 3D yaw and pitch axes to synthesize additional poses continuously. Synthesized images lead to better training of an object classifier. We design a novel eliminate-add structure to explicitly disentangle pose from object identity: first eliminate pose information of the input image and then add target pose information (regularized as continuous variables) to synthesize any target pose. We trained OPT-Net on images of toy vehicles shot on a turntable from the iLab-20M dataset. After training on unbalanced discrete poses (5 classes with 6 poses per object instance, plus 5 classes with only 2 poses), we show that OPT-Net can synthesize balanced continuous new poses along yaw and pitch axes with high quality. Training a ResNet-18 classifier with original plus synthesized poses improves mAP accuracy by 9% overtraining on original poses only. Further, the pre-trained OPT-Net can generalize to new object classes, which we demonstrate on both iLab-20M and RGB-D. We also show that the learned features can generalize to ImageNet.
View-Invariant Probabilistic Embedding for Human Pose
Dec 02, 2019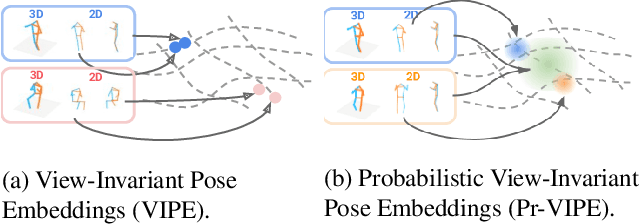
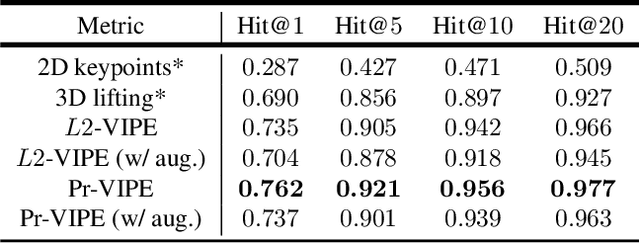


Depictions of similar human body configurations can vary with changing viewpoints. Using only 2D information, we would like to enable vision algorithms to recognize similarity in human body poses across multiple views. This ability is useful for analyzing body movements and human behaviors in images and videos. In this paper, we propose an approach for learning a compact view-invariant embedding space from 2D joint keypoints alone, without explicitly predicting 3D poses. Since 2D poses are projected from 3D space, they have an inherent ambiguity, which is difficult to represent through a deterministic mapping. Hence, we use probabilistic embeddings to model this input uncertainty. Experimental results show that our embedding model achieves higher accuracy when retrieving similar poses across different camera views, in comparison with 2D-to-3D pose lifting models. The results also suggest that our model is able to generalize across datasets, and our embedding variance correlates with input pose ambiguity.
Learning to Recognize Objects by Retaining other Factors of Variation
Jan 22, 2017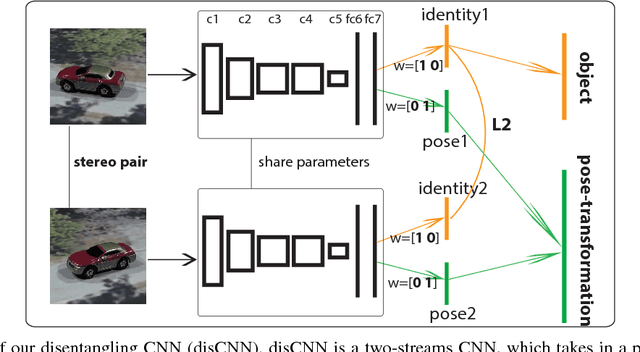


Natural images are generated under many factors, including shape, pose, illumination etc. Most existing ConvNets formulate object recognition from natural images as a single task classification problem, and attempt to learn features useful for object categories, but invariant to other factors of variation as much as possible. These architectures do not explicitly learn other factors, like pose and lighting, instead, they usually discard them by pooling and normalization. In this work, we take the opposite approach: we train ConvNets for object recognition by retaining other factors (pose in our case) and learn them jointly with object category. We design a new multi-task leaning (MTL) ConvNet, named disentangling CNN (disCNN), which explicitly enforces the disentangled representations of object identity and pose, and is trained to predict object categories and pose transformations. We show that disCNN achieves significantly better object recognition accuracies than AlexNet trained solely to predict object categories on the iLab-20M dataset, which is a large scale turntable dataset with detailed object pose and lighting information. We further show that the pretrained disCNN/AlexNet features on iLab- 20M generalize to object recognition on both Washington RGB-D and ImageNet datasets, and the pretrained disCNN features are significantly better than the pretrained AlexNet features for fine-tuning object recognition on the ImageNet dataset.
Improved Deep Learning of Object Category using Pose Information
Jan 22, 2017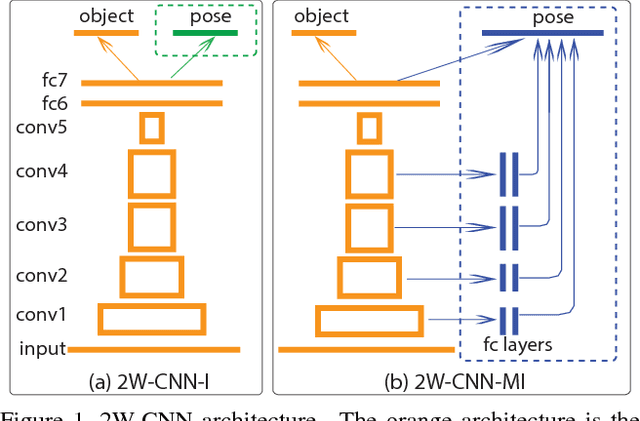



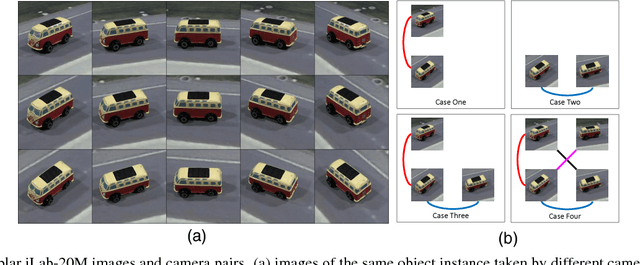
Despite significant recent progress, the best available computer vision algorithms still lag far behind human capabilities, even for recognizing individual discrete objects under various poses, illuminations, and backgrounds. Here we present a new approach to using object pose information to improve deep network learning. While existing large-scale datasets, e.g. ImageNet, do not have pose information, we leverage the newly published turntable dataset, iLab-20M, which has ~22M images of 704 object instances shot under different lightings, camera viewpoints and turntable rotations, to do more controlled object recognition experiments. We introduce a new convolutional neural network architecture, what/where CNN (2W-CNN), built on a linear-chain feedforward CNN (e.g., AlexNet), augmented by hierarchical layers regularized by object poses. Pose information is only used as feedback signal during training, in addition to category information; during test, the feedforward network only predicts category. To validate the approach, we train both 2W-CNN and AlexNet using a fraction of the dataset, and 2W-CNN achieves 6% performance improvement in category prediction. We show mathematically that 2W-CNN has inherent advantages over AlexNet under the stochastic gradient descent (SGD) optimization procedure. Further more, we fine-tune object recognition on ImageNet by using the pretrained 2W-CNN and AlexNet features on iLab-20M, results show that significant improvements have been achieved, compared with training AlexNet from scratch. Moreover, fine-tuning 2W-CNN features performs even better than fine-tuning the pretrained AlexNet features. These results show pretrained features on iLab- 20M generalizes well to natural image datasets, and 2WCNN learns even better features for object recognition than AlexNet.
metricDTW: local distance metric learning in Dynamic Time Warping
Jun 11, 2016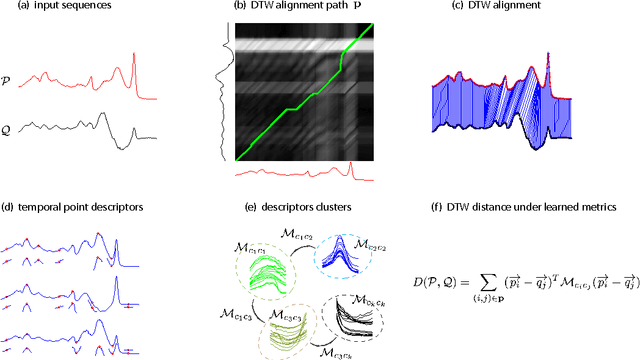
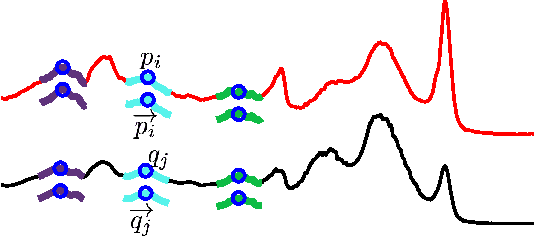
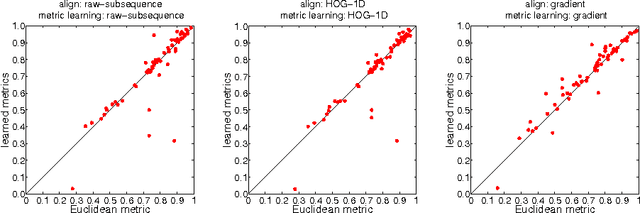
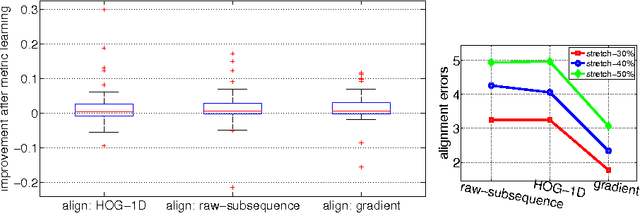
We propose to learn multiple local Mahalanobis distance metrics to perform k-nearest neighbor (kNN) classification of temporal sequences. Temporal sequences are first aligned by dynamic time warping (DTW); given the alignment path, similarity between two sequences is measured by the DTW distance, which is computed as the accumulated distance between matched temporal point pairs along the alignment path. Traditionally, Euclidean metric is used for distance computation between matched pairs, which ignores the data regularities and might not be optimal for applications at hand. Here we propose to learn multiple Mahalanobis metrics, such that DTW distance becomes the sum of Mahalanobis distances. We adapt the large margin nearest neighbor (LMNN) framework to our case, and formulate multiple metric learning as a linear programming problem. Extensive sequence classification results show that our proposed multiple metrics learning approach is effective, insensitive to the preceding alignment qualities, and reaches the state-of-the-art performances on UCR time series datasets.