 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Recognize Objects by Retaining other Factors of Variation
Jan 22, 2017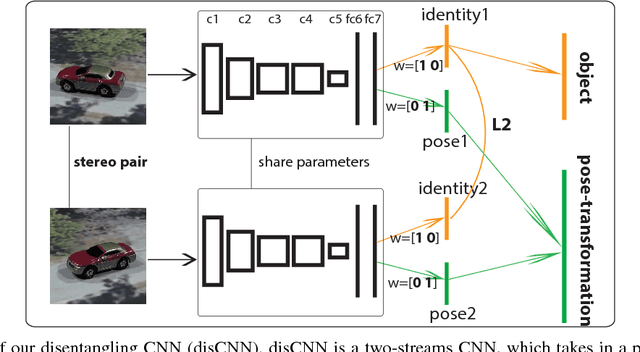


Natural images are generated under many factors, including shape, pose, illumination etc. Most existing ConvNets formulate object recognition from natural images as a single task classification problem, and attempt to learn features useful for object categories, but invariant to other factors of variation as much as possible. These architectures do not explicitly learn other factors, like pose and lighting, instead, they usually discard them by pooling and normalization. In this work, we take the opposite approach: we train ConvNets for object recognition by retaining other factors (pose in our case) and learn them jointly with object category. We design a new multi-task leaning (MTL) ConvNet, named disentangling CNN (disCNN), which explicitly enforces the disentangled representations of object identity and pose, and is trained to predict object categories and pose transformations. We show that disCNN achieves significantly better object recognition accuracies than AlexNet trained solely to predict object categories on the iLab-20M dataset, which is a large scale turntable dataset with detailed object pose and lighting information. We further show that the pretrained disCNN/AlexNet features on iLab- 20M generalize to object recognition on both Washington RGB-D and ImageNet datasets, and the pretrained disCNN features are significantly better than the pretrained AlexNet features for fine-tuning object recognition on the ImageNet dataset.