 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-to-Local or Local-to-Global? Enhancing Image Retrieval with Efficient Local Search and Effective Global Re-ranking
Sep 04, 2025The dominant paradigm in image retrieval systems today is to search large databases using global image features, and re-rank those initial results with local image feature matching techniques. This design, dubbed global-to-local, stems from the computational cost of local matching approaches, which can only be afforded for a small number of retrieved images. However, emerging efficient local feature search approaches have opened up new possibilities, in particular enabling detailed retrieval at large scale, to find partial matches which are often missed by global feature search. In parallel, global feature-based re-ranking has shown promising results with high computational efficiency. In this work, we leverage these building blocks to introduce a local-to-global retrieval paradigm, where efficient local feature search meets effective global feature re-ranking. Critically, we propose a re-ranking method where global features are computed on-the-fly, based on the local feature retrieval similarities. Such re-ranking-only global features leverage multidimensional scaling techniques to create embeddings which respect the local similarities obtained during search, enabling a significant re-ranking boost. Experimentally, we demonstrate solid retrieval performance, setting new state-of-the-art results on the Revisited Oxford and Paris datasets.
Gemini Embedding: Generalizable Embeddings from Gemini
Mar 10, 2025In this report, we introduce Gemini Embedding, a state-of-the-art embedding model leveraging the power of Gemini, Google's most capable large language model. Capitalizing on Gemini's inherent multilingual and code understanding capabilities, Gemini Embedding produces highly generalizable embeddings for text spanning numerous languages and textual modalities. The representations generated by Gemini Embedding can be precomputed and applied to a variety of downstream tasks including classification, similarity, clustering, ranking, and retrieval. Evaluated on the Massive Multilingual Text Embedding Benchmark (MMTEB), which includes over one hundred tasks across 250+ languages, Gemini Embedding substantially outperforms prior state-of-the-art models, demonstrating considerable improvements in embedding quality. Achieving state-of-the-art performance across MMTEB's multilingual, English, and code benchmarks, our unified model demonstrates strong capabilities across a broad selection of tasks and surpasses specialized domain-specific models.
Learning Visual Composition through Improved Semantic Guidance
Dec 19, 2024



Visual imagery does not consist of solitary objects, but instead reflects the composition of a multitude of fluid concepts. While there have been great advances in visual representation learning, such advances have focused on building better representations for a small number of discrete objects bereft of an understanding of how these objects are interacting. One can observe this limitation in representations learned through captions or contrastive learning -- where the learned model treats an image essentially as a bag of words. Several works have attempted to address this limitation through the development of bespoke learned architectures to directly address the shortcomings in compositional learning. In this work, we focus on simple, and scalable approaches. In particular, we demonstrate that by substantially improving weakly labeled data, i.e. captions, we can vastly improve the performance of standard contrastive learning approaches. Previous CLIP models achieved near chance rate on challenging tasks probing compositional learning. However, our simple approach boosts performance of CLIP substantially and surpasses all bespoke architectures. Furthermore, we showcase our results on a relatively new captioning benchmark derived from DOCCI. We demonstrate through a series of ablations that a standard CLIP model trained with enhanced data may demonstrate impressive performance on image retrieval tasks.
Dataset Distillers Are Good Label Denoisers In the Wild
Nov 18, 2024



Learning from noisy data has become essential for adapting deep learning models to real-world applications. Traditional methods often involve first evaluating the noise and then applying strategies such as discarding noisy samples, re-weighting, or re-labeling. However, these methods can fall into a vicious cycle when the initial noise evaluation is inaccurate, leading to suboptimal performance. To address this, we propose a novel approach that leverages dataset distillation for noise removal. This method avoids the feedback loop common in existing techniques and enhances training efficiency, while also providing strong privacy protection through offline processing. We rigorously evaluate three representative dataset distillation methods (DATM, DANCE, and RCIG) under various noise conditions, including symmetric noise, asymmetric noise, and real-world natural noise. Our empirical findings reveal that dataset distillation effectively serves as a denoising tool in random noise scenarios but may struggle with structured asymmetric noise patterns, which can be absorbed into the distilled samples. Additionally, clean but challenging samples, such as those from tail classes in imbalanced datasets, may undergo lossy compression during distillation. Despite these challenges, our results highlight that dataset distillation holds significant promise for robust model training, especially in high-privacy environments where noise is prevalent.
TIPS: Text-Image Pretraining with Spatial Awareness
Oct 21, 2024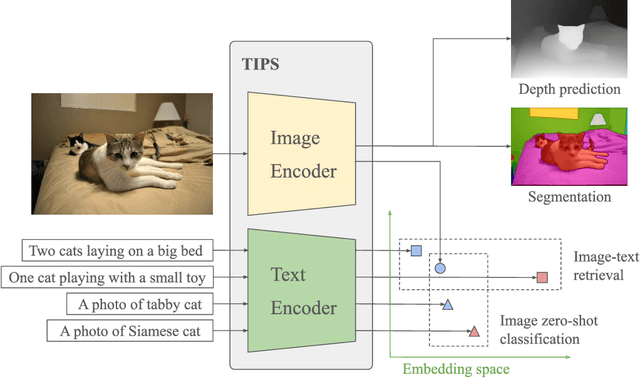
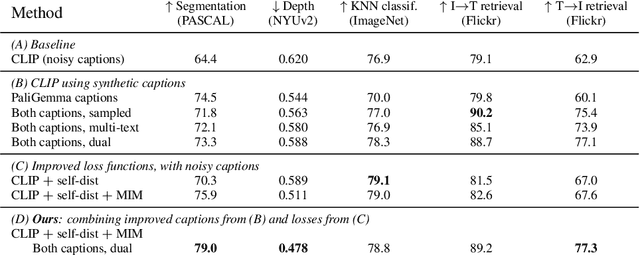
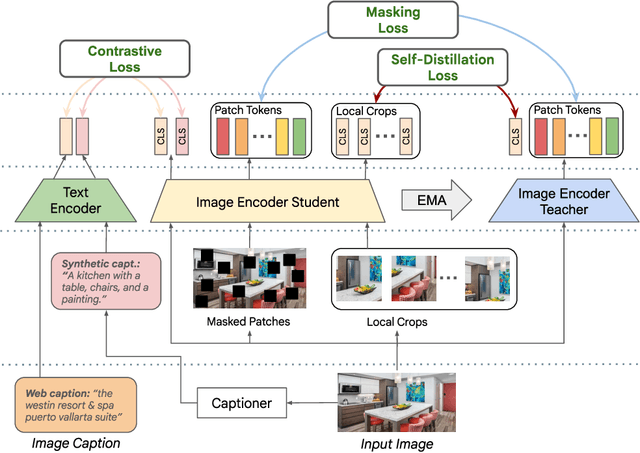
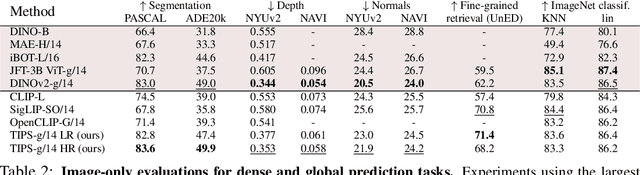
While image-text representation learning has become very popular in recent years, existing models tend to lack spatial awareness and have limited direct applicability for dense understanding tasks. For this reason, self-supervised image-only pretraining is still the go-to method for many dense vision applications (e.g. depth estimation, semantic segmentation), despite the lack of explicit supervisory signals. In this paper, we close this gap between image-text and self-supervised learning, by proposing a novel general-purpose image-text model, which can be effectively used off-the-shelf for dense and global vision tasks. Our method, which we refer to as Text-Image Pretraining with Spatial awareness (TIPS), leverages two simple and effective insights. First, on textual supervision: we reveal that replacing noisy web image captions by synthetically generated textual descriptions boosts dense understanding performance significantly, due to a much richer signal for learning spatially aware representations. We propose an adapted training method that combines noisy and synthetic captions, resulting in improvements across both dense and global understanding tasks. Second, on the learning technique: we propose to combine contrastive image-text learning with self-supervised masked image modeling, to encourage spatial coherence, unlocking substantial enhancements for downstream applications. Building on these two ideas, we scale our model using the transformer architecture, trained on a curated set of public images. Our experiments are conducted on 8 tasks involving 16 datasets in total, demonstrating strong off-the-shelf performance on both dense and global understanding, for several image-only and image-text tasks.
UDON: Universal Dynamic Online distillatioN for generic image representations
Jun 12, 2024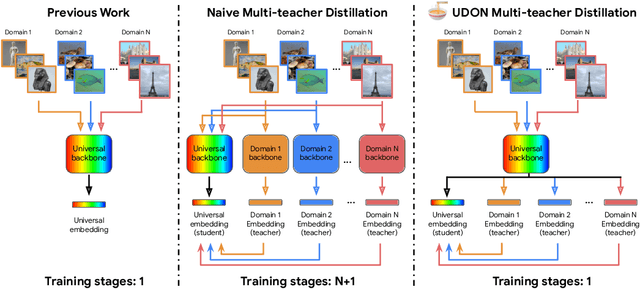

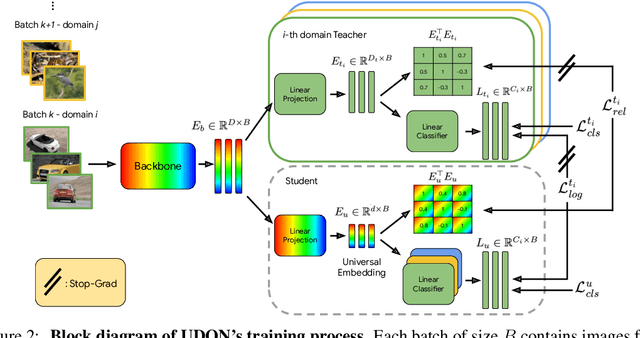
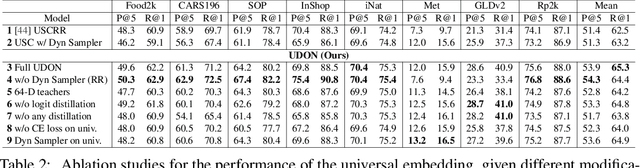
Universal image representations are critical in enabling real-world fine-grained and instance-level recognition applications, where objects and entities from any domain must be identified at large scale. Despite recent advances, existing methods fail to capture important domain-specific knowledge, while also ignoring differences in data distribution across different domains. This leads to a large performance gap between efficient universal solutions and expensive approaches utilising a collection of specialist models, one for each domain. In this work, we make significant strides towards closing this gap, by introducing a new learning technique, dubbed UDON (Universal Dynamic Online DistillatioN). UDON employs multi-teacher distillation, where each teacher is specialized in one domain, to transfer detailed domain-specific knowledge into the student universal embedding. UDON's distillation approach is not only effective, but also very efficient, by sharing most model parameters between the student and all teachers, where all models are jointly trained in an online manner. UDON also comprises a sampling technique which adapts the training process to dynamically allocate batches to domains which are learned slower and require more frequent processing. This boosts significantly the learning of complex domains which are characterised by a large number of classes and long-tail distributions. With comprehensive experiments, we validate each component of UDON, and showcase significant improvements over the state of the art in the recent UnED benchmark. Code: https://github.com/nikosips/UDON .
Learning Vision from Models Rivals Learning Vision from Data
Dec 28, 2023



We introduce SynCLR, a novel approach for learning visual representations exclusively from synthetic images and synthetic captions, without any real data. We synthesize a large dataset of image captions using LLMs, then use an off-the-shelf text-to-image model to generate multiple images corresponding to each synthetic caption. We perform visual representation learning on these synthetic images via contrastive learning, treating images sharing the same caption as positive pairs. The resulting representations transfer well to many downstream tasks, competing favorably with other general-purpose visual representation learners such as CLIP and DINO v2 in image classification tasks. Furthermore, in dense prediction tasks such as semantic segmentation, SynCLR outperforms previous self-supervised methods by a significant margin, e.g., improving over MAE and iBOT by 6.2 and 4.3 mIoU on ADE20k for ViT-B/16.
Scaling Laws of Synthetic Images for Model Training for Now
Dec 07, 2023



Recent significant advances in text-to-image models unlock the possibility of training vision systems using synthetic images, potentially overcoming the difficulty of collecting curated data at scale. It is unclear, however, how these models behave at scale, as more synthetic data is added to the training set. In this paper we study the scaling laws of synthetic images generated by state of the art text-to-image models, for the training of supervised models: image classifiers with label supervision, and CLIP with language supervision. We identify several factors, including text prompts, classifier-free guidance scale, and types of text-to-image models, that significantly affect scaling behavior. After tuning these factors, we observe that synthetic images demonstrate a scaling trend similar to, but slightly less effective than, real images in CLIP training, while they significantly underperform in scaling when training supervised image classifiers. Our analysis indicates that the main reason for this underperformance is the inability of off-the-shelf text-to-image models to generate certain concepts, a limitation that significantly impairs the training of image classifiers. Our findings also suggest that scaling synthetic data can be particularly effective in scenarios such as: (1) when there is a limited supply of real images for a supervised problem (e.g., fewer than 0.5 million images in ImageNet), (2) when the evaluation dataset diverges significantly from the training data, indicating the out-of-distribution scenario, or (3) when synthetic data is used in conjunction with real images, as demonstrated in the training of CLIP models.
Improve Supervised Representation Learning with Masked Image Modeling
Dec 01, 2023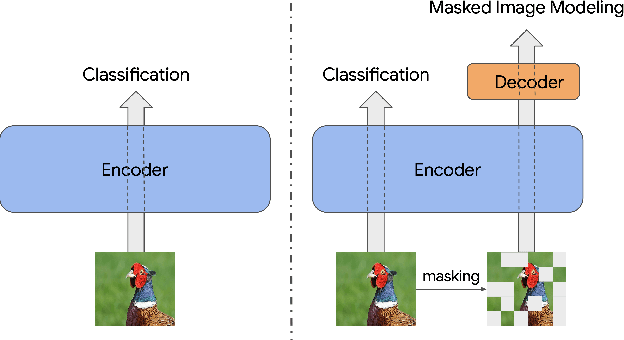
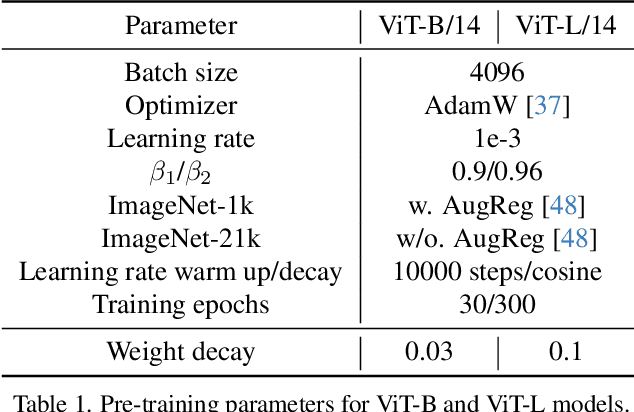
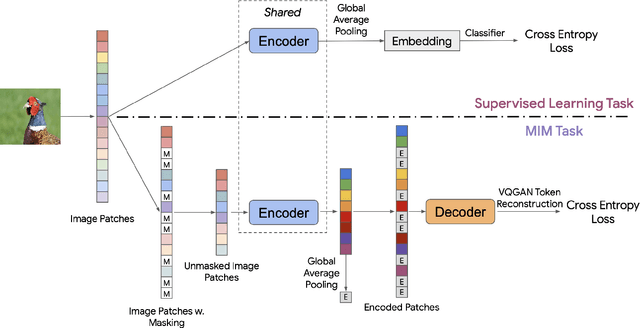
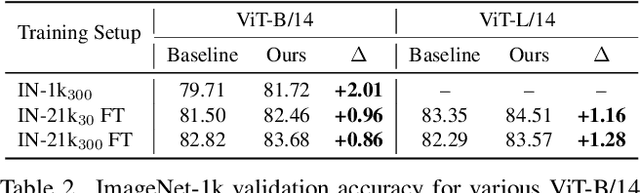
Training visual embeddings with labeled data supervision has been the de facto setup for representation learning in computer vision. Inspired by recent success of adopting masked image modeling (MIM) in self-supervised representation learning, we propose a simple yet effective setup that can easily integrate MIM into existing supervised training paradigms. In our design, in addition to the original classification task applied to a vision transformer image encoder, we add a shallow transformer-based decoder on top of the encoder and introduce an MIM task which tries to reconstruct image tokens based on masked image inputs. We show with minimal change in architecture and no overhead in inference that this setup is able to improve the quality of the learned representations for downstream tasks such as classification, image retrieval, and semantic segmentation. We conduct a comprehensive study and evaluation of our setup on public benchmarks. On ImageNet-1k, our ViT-B/14 model achieves 81.72% validation accuracy, 2.01% higher than the baseline model. On K-Nearest-Neighbor image retrieval evaluation with ImageNet-1k, the same model outperforms the baseline by 1.32%. We also show that this setup can be easily scaled to larger models and datasets. Code and checkpoints will be released.
MatFormer: Nested Transformer for Elastic Inference
Oct 11, 2023



Transformer models are deployed in a wide range of settings, from multi-accelerator clusters to standalone mobile phones. The diverse inference constraints in these scenarios necessitate practitioners to train foundation models such as PaLM 2, Llama, & ViTs as a series of models of varying sizes. Due to significant training costs, only a select few model sizes are trained and supported, limiting more fine-grained control over relevant tradeoffs, including latency, cost, and accuracy. This work introduces MatFormer, a nested Transformer architecture designed to offer elasticity in a variety of deployment constraints. Each Feed Forward Network (FFN) block of a MatFormer model is jointly optimized with a few nested smaller FFN blocks. This training procedure allows for the Mix'n'Match of model granularities across layers -- i.e., a trained universal MatFormer model enables extraction of hundreds of accurate smaller models, which were never explicitly optimized. We empirically demonstrate MatFormer's effectiveness across different model classes (decoders & encoders), modalities (language & vision), and scales (up to 2.6B parameters). We find that a 2.6B decoder-only MatFormer language model (MatLM) allows us to extract smaller models spanning from 1.5B to 2.6B, each exhibiting comparable validation loss and one-shot downstream evaluations to their independently trained counterparts. Furthermore, we observe that smaller encoders extracted from a universal MatFormer-based ViT (MatViT) encoder preserve the metric-space structure for adaptive large-scale retrieval. Finally, we showcase that speculative decoding with the accurate and consistent submodels extracted from MatFormer can further reduce inference latency.