 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-to-Local or Local-to-Global? Enhancing Image Retrieval with Efficient Local Search and Effective Global Re-ranking
Sep 04, 2025The dominant paradigm in image retrieval systems today is to search large databases using global image features, and re-rank those initial results with local image feature matching techniques. This design, dubbed global-to-local, stems from the computational cost of local matching approaches, which can only be afforded for a small number of retrieved images. However, emerging efficient local feature search approaches have opened up new possibilities, in particular enabling detailed retrieval at large scale, to find partial matches which are often missed by global feature search. In parallel, global feature-based re-ranking has shown promising results with high computational efficiency. In this work, we leverage these building blocks to introduce a local-to-global retrieval paradigm, where efficient local feature search meets effective global feature re-ranking. Critically, we propose a re-ranking method where global features are computed on-the-fly, based on the local feature retrieval similarities. Such re-ranking-only global features leverage multidimensional scaling techniques to create embeddings which respect the local similarities obtained during search, enabling a significant re-ranking boost. Experimentally, we demonstrate solid retrieval performance, setting new state-of-the-art results on the Revisited Oxford and Paris datasets.
Yes, we CANN: Constrained Approximate Nearest Neighbors for local feature-based visual localization
Jun 15, 2023Large-scale visual localization systems continue to rely on 3D point clouds built from image collections using structure-from-motion. While the 3D points in these models are represented using local image features, directly matching a query image's local features against the point cloud is challenging due to the scale of the nearest-neighbor search problem. Many recent approaches to visual localization have thus proposed a hybrid method, where first a global (per image) embedding is used to retrieve a small subset of database images, and local features of the query are matched only against those. It seems to have become common belief that global embeddings are critical for said image-retrieval in visual localization, despite the significant downside of having to compute two feature types for each query image. In this paper, we take a step back from this assumption and propose Constrained Approximate Nearest Neighbors (CANN), a joint solution of k-nearest-neighbors across both the geometry and appearance space using only local features. We first derive the theoretical foundation for k-nearest-neighbor retrieval across multiple metrics and then showcase how CANN improves visual localization. Our experiments on public localization benchmarks demonstrate that our method significantly outperforms both state-of-the-art global feature-based retrieval and approaches using local feature aggregation schemes. Moreover, it is an order of magnitude faster in both index and query time than feature aggregation schemes for these datasets. Code will be released.
SCOOP: Self-Supervised Correspondence and Optimization-Based Scene Flow
Nov 25, 2022



Scene flow estimation is a long-standing problem in computer vision, where the goal is to find the 3D motion of a scene from its consecutive observations. Recently, there have been efforts to compute the scene flow from 3D point clouds. A common approach is to train a regression model that consumes source and target point clouds and outputs the per-point translation vectors. An alternative is to learn point matches between the point clouds concurrently with regressing a refinement of the initial correspondence flow. In both cases, the learning task is very challenging since the flow regression is done in the free 3D space, and a typical solution is to resort to a large annotated synthetic dataset. We introduce SCOOP, a new method for scene flow estimation that can be learned on a small amount of data without employing ground-truth flow supervision. In contrast to previous work, we train a pure correspondence model focused on learning point feature representation and initialize the flow as the difference between a source point and its softly corresponding target point. Then, in the run-time phase, we directly optimize a flow refinement component with a self-supervised objective, which leads to a coherent and accurate flow field between the point clouds. Experiments on widespread datasets demonstrate the performance gains achieved by our method compared to existing leading techniques while using a fraction of the training data. Our code is publicly available at https://github.com/itailang/SCOOP.
Efficient Large Scale Inlier Voting for Geometric Vision Problems
Jul 27, 2021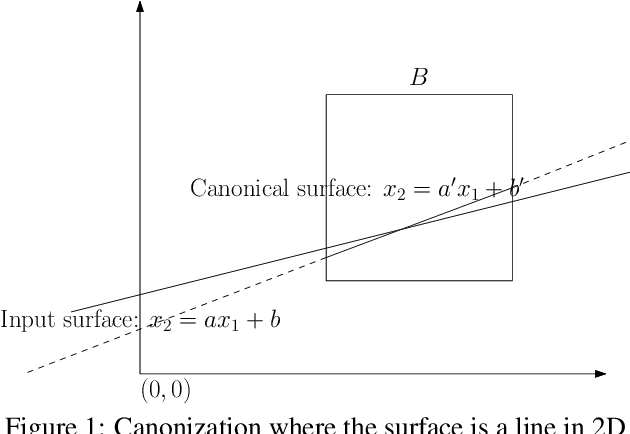



Outlier rejection and equivalently inlier set optimization is a key ingredient in numerous applications in computer vision such as filtering point-matches in camera pose estimation or plane and normal estimation in point clouds. Several approaches exist, yet at large scale we face a combinatorial explosion of possible solutions and state-of-the-art methods like RANSAC, Hough transform or Branch&Bound require a minimum inlier ratio or prior knowledge to remain practical. In fact, for problems such as camera posing in very large scenes these approaches become useless as they have exponential runtime growth if these conditions aren't met. To approach the problem we present a efficient and general algorithm for outlier rejection based on "intersecting" $k$-dimensional surfaces in $R^d$. We provide a recipe for casting a variety of geometric problems as finding a point in $R^d$ which maximizes the number of nearby surfaces (and thus inliers). The resulting algorithm has linear worst-case complexity with a better runtime dependency in the approximation factor than competing algorithms while not requiring domain specific bounds. This is achieved by introducing a space decomposition scheme that bounds the number of computations by successively rounding and grouping samples. Our recipe (and open-source code) enables anybody to derive such fast approaches to new problems across a wide range of domains. We demonstrate the versatility of the approach on several camera posing problems with a high number of matches at low inlier ratio achieving state-of-the-art results at significantly lower processing times.
Large-scale, real-time visual-inertial localization revisited
Jun 30, 2019



The overarching goals in image-based localization are scale, robustness and speed. In recent years, approaches based on local features and sparse 3D point-cloud models have both dominated the benchmarks and seen successful realworld deployment. They enable applications ranging from robot navigation, autonomous driving, virtual and augmented reality to device geo-localization. Recently end-to-end learned localization approaches have been proposed which show promising results on small scale datasets. However the positioning accuracy, scalability, latency and compute & storage requirements of these approaches remain open challenges. We aim to deploy localization at global-scale where one thus relies on methods using local features and sparse 3D models. Our approach spans from offline model building to real-time client-side pose fusion. The system compresses appearance and geometry of the scene for efficient model storage and lookup leading to scalability beyond what what has been previously demonstrated. It allows for low-latency localization queries and efficient fusion run in real-time on mobile platforms by combining server-side localization with real-time visual-inertial-based camera pose tracking. In order to further improve efficiency we leverage a combination of priors, nearest neighbor search, geometric match culling and a cascaded pose candidate refinement step. This combination outperforms previous approaches when working with large scale models and allows deployment at unprecedented scale. We demonstrate the effectiveness of our approach on a proof-of-concept system localizing 2.5 million images against models from four cities in different regions on the world achieving query latencies in the 200ms range.
Large-Scale 3D Scene Classification With Multi-View Volumetric CNN
Dec 26, 2017

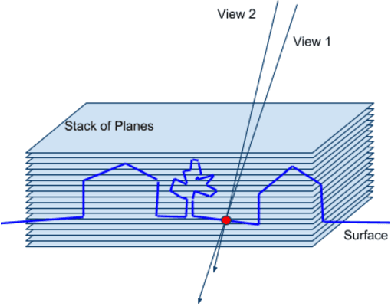

We introduce a method to classify imagery using a convo- lutional neural network (CNN) on multi-view image pro- jections. The power of our method comes from using pro- jections of multiple images at multiple depth planes near the reconstructed surface. This enables classification of categories whose salient aspect is appearance change un- der different viewpoints, such as water, trees, and other materials with complex reflection/light response proper- ties. Our method does not require boundary labelling in images and works on pixel-level classification with a small (few pixels) context, which simplifies the cre- ation of a training set. We demonstrate this application on large-scale aerial imagery collections, and extend the per-pixel classification to robustly create a consistent 2D classification which can be used to fill the gaps in non- reconstructible water regions. We also apply our method to classify tree regions. In both cases, the training data can quickly be generated using a small number of manually- created polygons on a map. We show that even with a very simple and standard network our CNN outperforms the state-of-the-art image classification, the Inception-V3 model retrained from a large collection of aerial images.