 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Image Geo-Localization to Continent Level
Oct 30, 2025Determining the precise geographic location of an image at a global scale remains an unsolved challenge. Standard image retrieval techniques are inefficient due to the sheer volume of images (>100M) and fail when coverage is insufficient. Scalable solutions, however, involve a trade-off: global classification typically yields coarse results (10+ kilometers), while cross-view retrieval between ground and aerial imagery suffers from a domain gap and has been primarily studied on smaller regions. This paper introduces a hybrid approach that achieves fine-grained geo-localization across a large geographic expanse the size of a continent. We leverage a proxy classification task during training to learn rich feature representations that implicitly encode precise location information. We combine these learned prototypes with embeddings of aerial imagery to increase robustness to the sparsity of ground-level data. This enables direct, fine-grained retrieval over areas spanning multiple countries. Our extensive evaluation demonstrates that our approach can localize within 200m more than 68\% of queries of a dataset covering a large part of Europe. The code is publicly available at https://scaling-geoloc.github.io.
Yes, we CANN: Constrained Approximate Nearest Neighbors for local feature-based visual localization
Jun 15, 2023Large-scale visual localization systems continue to rely on 3D point clouds built from image collections using structure-from-motion. While the 3D points in these models are represented using local image features, directly matching a query image's local features against the point cloud is challenging due to the scale of the nearest-neighbor search problem. Many recent approaches to visual localization have thus proposed a hybrid method, where first a global (per image) embedding is used to retrieve a small subset of database images, and local features of the query are matched only against those. It seems to have become common belief that global embeddings are critical for said image-retrieval in visual localization, despite the significant downside of having to compute two feature types for each query image. In this paper, we take a step back from this assumption and propose Constrained Approximate Nearest Neighbors (CANN), a joint solution of k-nearest-neighbors across both the geometry and appearance space using only local features. We first derive the theoretical foundation for k-nearest-neighbor retrieval across multiple metrics and then showcase how CANN improves visual localization. Our experiments on public localization benchmarks demonstrate that our method significantly outperforms both state-of-the-art global feature-based retrieval and approaches using local feature aggregation schemes. Moreover, it is an order of magnitude faster in both index and query time than feature aggregation schemes for these datasets. Code will be released.
SNAP: Self-Supervised Neural Maps for Visual Positioning and Semantic Understanding
Jun 08, 2023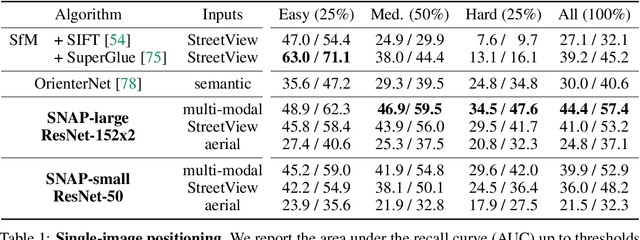
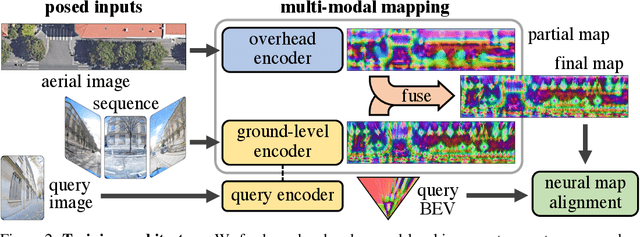


Semantic 2D maps are commonly used by humans and machines for navigation purposes, whether it's walking or driving. However, these maps have limitations: they lack detail, often contain inaccuracies, and are difficult to create and maintain, especially in an automated fashion. Can we use raw imagery to automatically create better maps that can be easily interpreted by both humans and machines? We introduce SNAP, a deep network that learns rich neural 2D maps from ground-level and overhead images. We train our model to align neural maps estimated from different inputs, supervised only with camera poses over tens of millions of StreetView images. SNAP can resolve the location of challenging image queries beyond the reach of traditional methods, outperforming the state of the art in localization by a large margin. Moreover, our neural maps encode not only geometry and appearance but also high-level semantics, discovered without explicit supervision. This enables effective pre-training for data-efficient semantic scene understanding, with the potential to unlock cost-efficient creation of more detailed maps.
Efficient Large Scale Inlier Voting for Geometric Vision Problems
Jul 27, 2021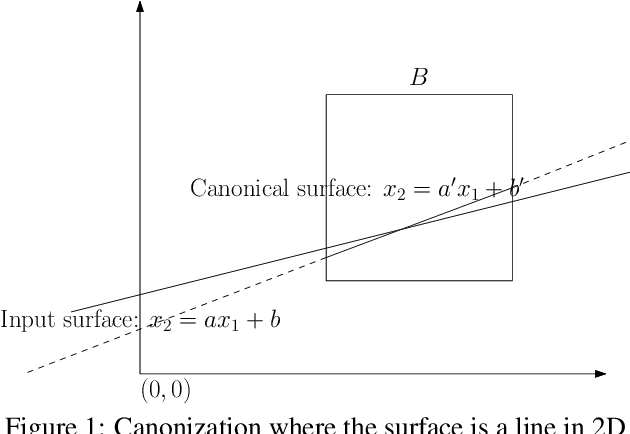



Outlier rejection and equivalently inlier set optimization is a key ingredient in numerous applications in computer vision such as filtering point-matches in camera pose estimation or plane and normal estimation in point clouds. Several approaches exist, yet at large scale we face a combinatorial explosion of possible solutions and state-of-the-art methods like RANSAC, Hough transform or Branch&Bound require a minimum inlier ratio or prior knowledge to remain practical. In fact, for problems such as camera posing in very large scenes these approaches become useless as they have exponential runtime growth if these conditions aren't met. To approach the problem we present a efficient and general algorithm for outlier rejection based on "intersecting" $k$-dimensional surfaces in $R^d$. We provide a recipe for casting a variety of geometric problems as finding a point in $R^d$ which maximizes the number of nearby surfaces (and thus inliers). The resulting algorithm has linear worst-case complexity with a better runtime dependency in the approximation factor than competing algorithms while not requiring domain specific bounds. This is achieved by introducing a space decomposition scheme that bounds the number of computations by successively rounding and grouping samples. Our recipe (and open-source code) enables anybody to derive such fast approaches to new problems across a wide range of domains. We demonstrate the versatility of the approach on several camera posing problems with a high number of matches at low inlier ratio achieving state-of-the-art results at significantly lower processing times.
SuperNCN: Neighbourhood consensus network for robust outdoor scenes matching
Dec 10, 2019


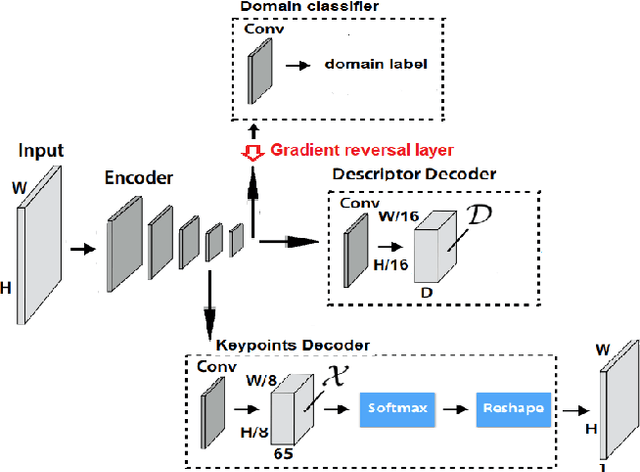
In this paper, we present a framework for computing dense keypoint correspondences between images under strong scene appearance changes. Traditional methods, based on nearest neighbour search in the feature descriptor space, perform poorly when environmental conditions vary, e.g. when images are taken at different times of the day or seasons. Our method improves finding keypoint correspondences in such difficult conditions. First, we use Neighbourhood Consensus Networks to build spatially consistent matching grid between two images at a coarse scale. Then, we apply Superpoint-like corner detector to achieve pixel-level accuracy. Both parts use features learned with domain adaptation to increase robustness against strong scene appearance variations. The framework has been tested on a RobotCar Seasons dataset, proving large improvement on pose estimation task under challenging environmental conditions.
Large-scale, real-time visual-inertial localization revisited
Jun 30, 2019



The overarching goals in image-based localization are scale, robustness and speed. In recent years, approaches based on local features and sparse 3D point-cloud models have both dominated the benchmarks and seen successful realworld deployment. They enable applications ranging from robot navigation, autonomous driving, virtual and augmented reality to device geo-localization. Recently end-to-end learned localization approaches have been proposed which show promising results on small scale datasets. However the positioning accuracy, scalability, latency and compute & storage requirements of these approaches remain open challenges. We aim to deploy localization at global-scale where one thus relies on methods using local features and sparse 3D models. Our approach spans from offline model building to real-time client-side pose fusion. The system compresses appearance and geometry of the scene for efficient model storage and lookup leading to scalability beyond what what has been previously demonstrated. It allows for low-latency localization queries and efficient fusion run in real-time on mobile platforms by combining server-side localization with real-time visual-inertial-based camera pose tracking. In order to further improve efficiency we leverage a combination of priors, nearest neighbor search, geometric match culling and a cascaded pose candidate refinement step. This combination outperforms previous approaches when working with large scale models and allows deployment at unprecedented scale. We demonstrate the effectiveness of our approach on a proof-of-concept system localizing 2.5 million images against models from four cities in different regions on the world achieving query latencies in the 200ms range.
SConE: Siamese Constellation Embedding Descriptor for Image Matching
Sep 28, 2018

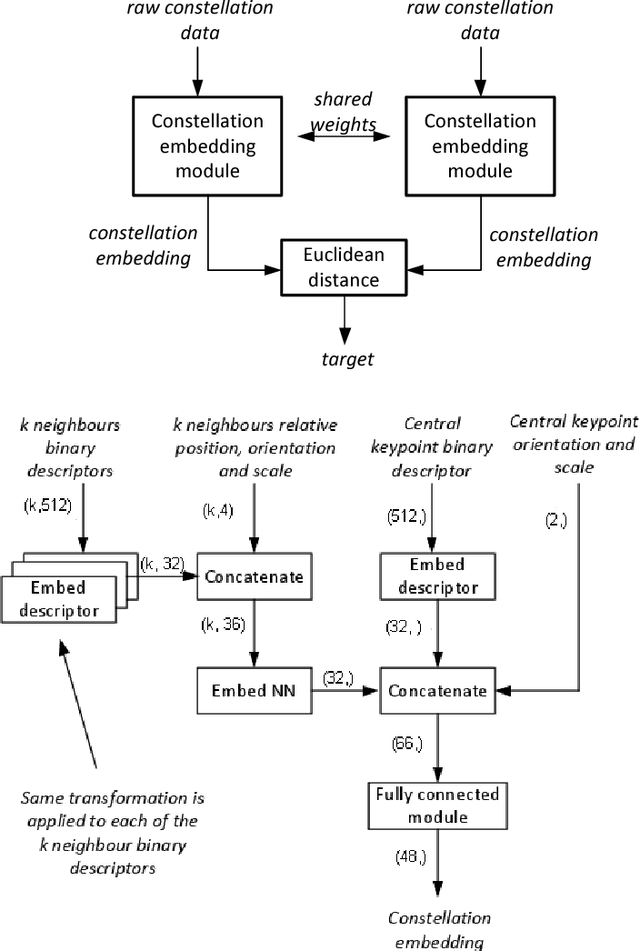
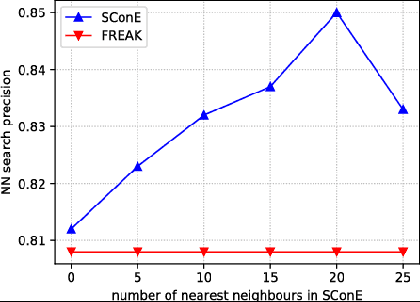
Numerous computer vision applications rely on local feature descriptors, such as SIFT, SURF or FREAK, for image matching. Although their local character makes image matching processes more robust to occlusions, it often leads to geometrically inconsistent keypoint matches that need to be filtered out, e.g. using RANSAC. In this paper we propose a novel, more discriminative, descriptor that includes not only local feature representation, but also information about the geometric layout of neighbouring keypoints. To that end, we use a Siamese architecture that learns a low-dimensional feature embedding of keypoint constellation by maximizing the distances between non-corresponding pairs of matched image patches, while minimizing it for correct matches. The 48-dimensional oating point descriptor that we train is built on top of the state-of-the-art FREAK descriptor achieves significant performance improvement over the competitors on a challenging TUM dataset.
Interest point detectors stability evaluation on ApolloScape dataset
Sep 28, 2018
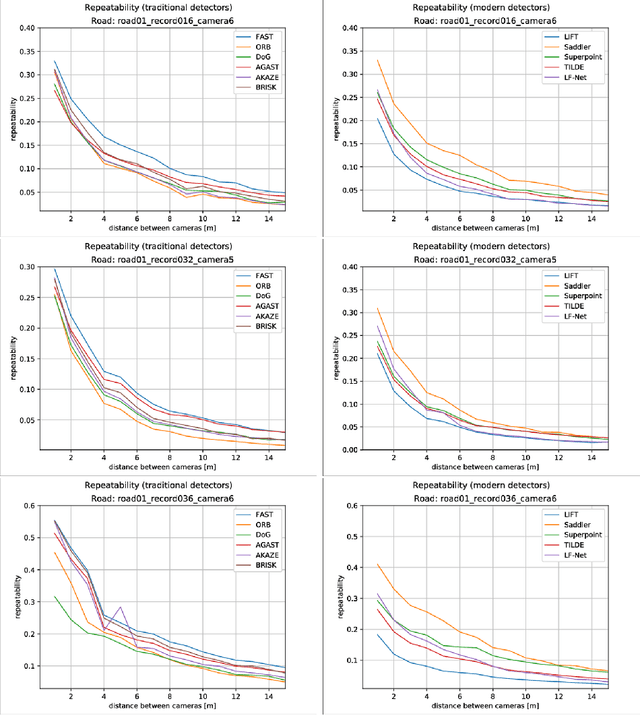
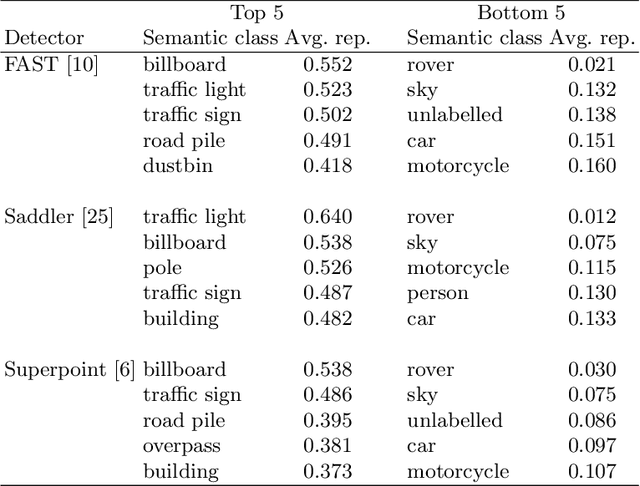

In the recent years, a number of novel, deep-learning based, interest point detectors, such as LIFT, DELF, Superpoint or LF-Net was proposed. However there's a lack of a standard benchmark to evaluate suitability of these novel keypoint detectors for real-live applications such as autonomous driving. Traditional benchmarks (e.g. Oxford VGG) are rather limited, as they consist of relatively few images of mostly planar scenes taken in favourable conditions. In this paper we verify if the recent, deep-learning based interest point detectors have the advantage over the traditional, hand-crafted keypoint detectors. To this end, we evaluate stability of a number of hand crafted and recent, learning-based interest point detectors on the street-level view ApolloScape dataset.
LandmarkBoost: Efficient Visual Context Classifiers for Robust Localization
Jul 13, 2018



The growing popularity of autonomous systems creates a need for reliable and efficient metric pose retrieval algorithms. Currently used approaches tend to rely on nearest neighbor search of binary descriptors to perform the 2D-3D matching and guarantee realtime capabilities on mobile platforms. These methods struggle, however, with the growing size of the map, changes in viewpoint or appearance, and visual aliasing present in the environment. The rigidly defined descriptor patterns only capture a limited neighborhood of the keypoint and completely ignore the overall visual context. We propose LandmarkBoost - an approach that, in contrast to the conventional 2D-3D matching methods, casts the search problem as a landmark classification task. We use a boosted classifier to classify landmark observations and directly obtain correspondences as classifier scores. We also introduce a formulation of visual context that is flexible, efficient to compute, and can capture relationships in the entire image plane. The original binary descriptors are augmented with contextual information and informative features are selected by the boosting framework. Through detailed experiments, we evaluate the retrieval quality and performance of LandmarkBoost, demonstrating that it outperforms common state-of-the-art descriptor matching methods.
maplab: An Open Framework for Research in Visual-inertial Mapping and Localization
Nov 28, 2017


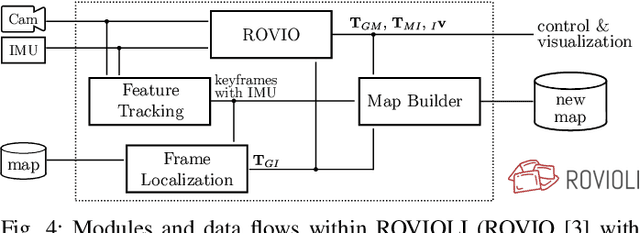
Robust and accurate visual-inertial estimation is crucial to many of today's challenges in robotics. Being able to localize against a prior map and obtain accurate and driftfree pose estimates can push the applicability of such systems even further. Most of the currently available solutions, however, either focus on a single session use-case, lack localization capabilities or an end-to-end pipeline. We believe that only a complete system, combining state-of-the-art algorithms, scalable multi-session mapping tools, and a flexible user interface, can become an efficient research platform. We therefore present maplab, an open, research-oriented visual-inertial mapping framework for processing and manipulating multi-session maps, written in C++. On the one hand, maplab can be seen as a ready-to-use visual-inertial mapping and localization system. On the other hand, maplab provides the research community with a collection of multisession mapping tools that include map merging, visual-inertial batch optimization, and loop closure. Furthermore, it includes an online frontend that can create visual-inertial maps and also track a global drift-free pose within a localization map. In this paper, we present the system architecture, five use-cases, and evaluations of the system on public datasets. The source code of maplab is freely available for the benefit of the robotics research community.