 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComments on "Privacy-Enhanced Federated Learning Against Poisoning Adversaries"
Sep 30, 2024In August 2021, Liu et al. (IEEE TIFS'21) proposed a privacy-enhanced framework named PEFL to efficiently detect poisoning behaviours in Federated Learning (FL) using homomorphic encryption. In this article, we show that PEFL does not preserve privacy. In particular, we illustrate that PEFL reveals the entire gradient vector of all users in clear to one of the participating entities, thereby violating privacy. Furthermore, we clearly show that an immediate fix for this issue is still insufficient to achieve privacy by pointing out multiple flaws in the proposed system. Note: Although our privacy issues mentioned in Section II have been published in January 2023 (Schneider et. al., IEEE TIFS'23), several subsequent papers continued to reference Liu et al. (IEEE TIFS'21) as a potential solution for private federated learning. While a few works have acknowledged the privacy concerns we raised, several of subsequent works either propagate these errors or adopt the constructions from Liu et al. (IEEE TIFS'21), thereby unintentionally inheriting the same privacy vulnerabilities. We believe this oversight is partly due to the limited visibility of our comments paper at TIFS'23 (Schneider et. al., IEEE TIFS'23). Consequently, to prevent the continued propagation of the flawed algorithms in Liu et al. (IEEE TIFS'21) into future research, we also put this article to an ePrint.
Attesting Distributional Properties of Training Data for Machine Learning
Aug 18, 2023



The success of machine learning (ML) has been accompanied by increased concerns about its trustworthiness. Several jurisdictions are preparing ML regulatory frameworks. One such concern is ensuring that model training data has desirable distributional properties for certain sensitive attributes. For example, draft regulations indicate that model trainers are required to show that training datasets have specific distributional properties, such as reflecting diversity of the population. We propose the notion of property attestation allowing a prover (e.g., model trainer) to demonstrate relevant distributional properties of training data to a verifier (e.g., a customer) without revealing the data. We present an effective hybrid property attestation combining property inference with cryptographic mechanisms.
Orthogonal Sampling based Broad-Band Signal Generation with Low-Bandwidth Electronics
Jun 08, 2023High-bandwidth signals are needed in many applications like radar, sensing, measurement and communications. Especially in optical networks, the sampling rate and analog bandwidth of digital-to-analog converters (DACs) is a bottleneck for further increasing data rates. To circumvent the sampling rate and bandwidth problem of electronic DACs, we demonstrate the generation of wide-band signals with low-bandwidth electronics. This generation is based on orthogonal sampling with sinc-pulse sequences in N parallel branches. The method not only reduces the sampling rate and bandwidth, at the same time the effective number of bits (ENOB) is improved, dramatically reducing the requirements on the electronic signal processing. In proof of concept experiments the generation of analog signals, as well as Nyquist shaped and normal data will be shown. In simulations we investigate the performance of 60 GHz data generation by 20 and 12 GHz electronics. The method can easily be integrated together with already existing electronic DAC designs and would be of great interest for all high-bandwidth applications.
HyFL: A Hybrid Approach For Private Federated Learning
Feb 20, 2023



As a distributed machine learning paradigm, federated learning (FL) conveys a sense of privacy to contributing participants because training data never leaves their devices. However, gradient updates and the aggregated model still reveal sensitive information. In this work, we propose HyFL, a new framework that combines private training and inference with secure aggregation and hierarchical FL to provide end-to-end protection and facilitate large-scale global deployments. Additionally, we show that HyFL strictly limits the attack surface for malicious participants: they are restricted to data-poisoning attacks and cannot significantly reduce accuracy.
ScionFL: Secure Quantized Aggregation for Federated Learning
Oct 13, 2022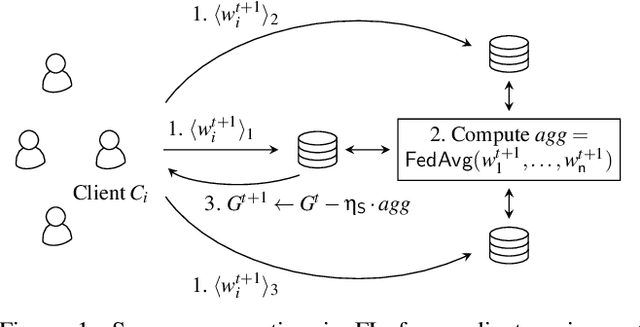
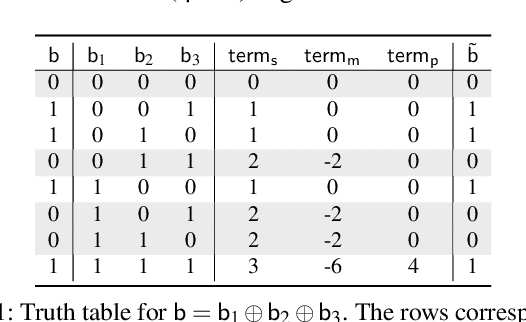

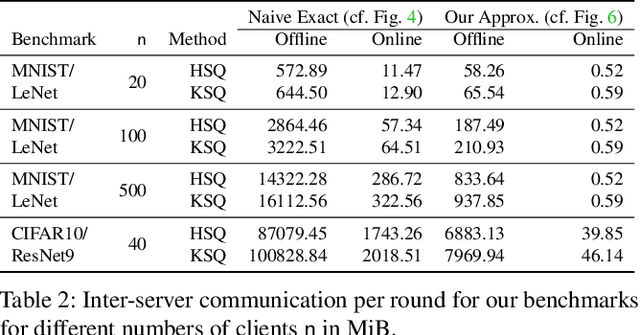
Privacy concerns in federated learning (FL) are commonly addressed with secure aggregation schemes that prevent a central party from observing plaintext client updates. However, most such schemes neglect orthogonal FL research that aims at reducing communication between clients and the aggregator and is instrumental in facilitating cross-device FL with thousands and even millions of (mobile) participants. In particular, quantization techniques can typically reduce client-server communication by a factor of 32x. In this paper, we unite both research directions by introducing an efficient secure aggregation framework based on outsourced multi-party computation (MPC) that supports any linear quantization scheme. Specifically, we design a novel approximate version of an MPC-based secure aggregation protocol with support for multiple stochastic quantization schemes, including ones that utilize the randomized Hadamard transform and Kashin's representation. In our empirical performance evaluation, we show that with no additional overhead for clients and moderate inter-server communication, we achieve similar training accuracy as insecure schemes for standard FL benchmarks. Beyond this, we present an efficient extension to our secure quantized aggregation framework that effectively defends against state-of-the-art untargeted poisoning attacks.
Reconfigurable and Real-Time Nyquist OTDM Demultiplexing in Silicon Photonics
Oct 19, 2021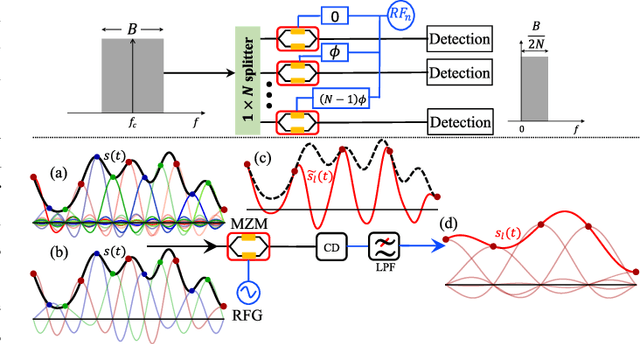
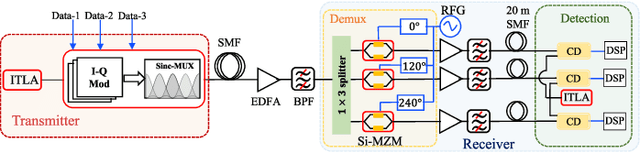
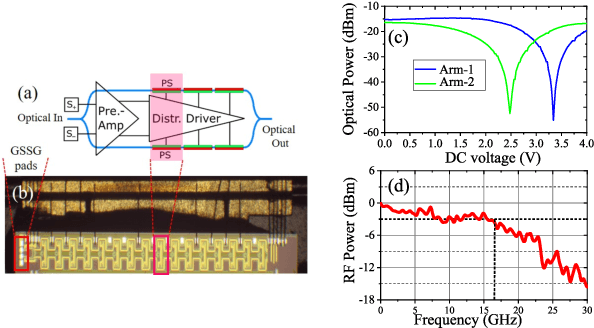
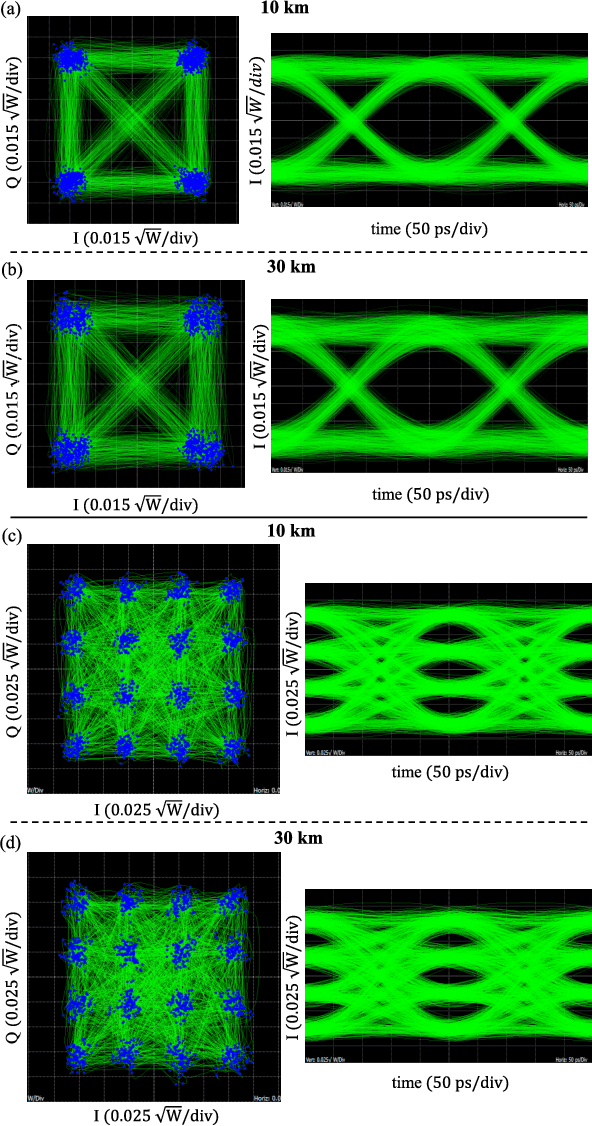
We demonstrate for the first time, to the best of our knowledge, reconfigurable and real-time orthogonal time-domain demultiplexing of coherent multilevel Nyquist signals in silicon photonics. No external pulse source is needed and frequencytime coherence is used to sample the incoming Nyquist OTDM signal with orthogonal sinc-shaped Nyquist pulse sequences using Mach-Zehnder modulators. All the parameters such as bandwidth and channel selection are completely tunable in the electrical domain. The feasibility of this scheme is demonstrated through a demultiplexing experiment over the entire C-band (1530 nm - 1550 nm), employing 24 Gbaud Nyquist QAM signals due to experimental constraints on the transmitter side. However, the silicon Mach-Zehnder modulator with a 3-dB bandwidth of only 16 GHz can demultiplex Nyquist pulses of 90 GHz optical bandwidth suggesting a possibility to reach symbol rates up to 90 GBd in an integrated Nyquist transceiver.
Optical Channel Aggregation by Coherent Spectral Superposition with Electro-Optic Modulators
Sep 03, 2021
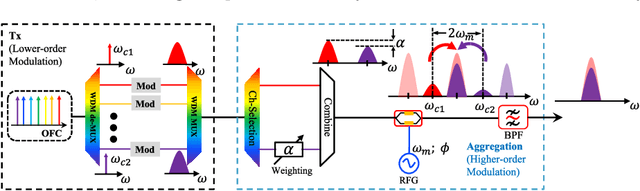
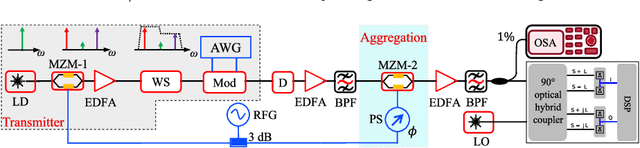
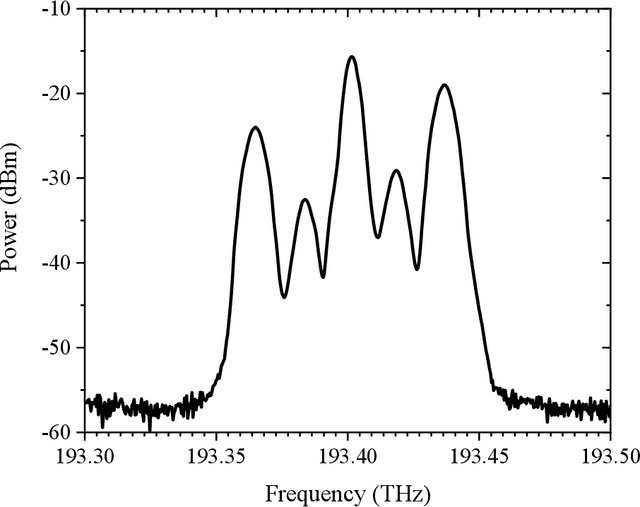
As the bit rates of routed data streams exceed the throughput of single wavelength-division multiplexing channels, spectral traffic aggregation becomes essential for optical network scaling. Here we propose a scheme for all-optical aggregation of several low bitrate channels to fewer channels with higher spectral efficiency. The method is based on optical vector summation facilitated by coherent spectral superposition. Thereby it does not need any optical nonlinearities and is based on linear signal processing with an electro-optic modulator. Furthermore, optical phase tuning required for vector addition can be easily achieved by a phase tuning of the radio frequency signal driving the modulator. We experimentally demonstrate the aggregation of two 10 Gbaud BPSK signals into one 10 Gbaud QPSK and one 10 Gbaud PAM-4 signal, the aggregation of two 10 Gbaud QPSK signals into 10 Gbaud QAM-16, as well as the aggregation of sinc-shaped Nyquist signals. The presented concept of in-line all-optical aggregation demonstrates considerable improvement in network spectrum utilization and can significantly enhance the operational capacity with reduced complexity. It provides a new way for realizing the flexible optical transmission of advanced modulation format signals, and suits for future dynamically reconfigurable optical networks. Since the method is based on linear signal processing with electro-optic modulator, integration into any integrated photonic platform is straightforward.
Conservative Extensions in Horn Description Logics with Inverse Roles
Nov 19, 2020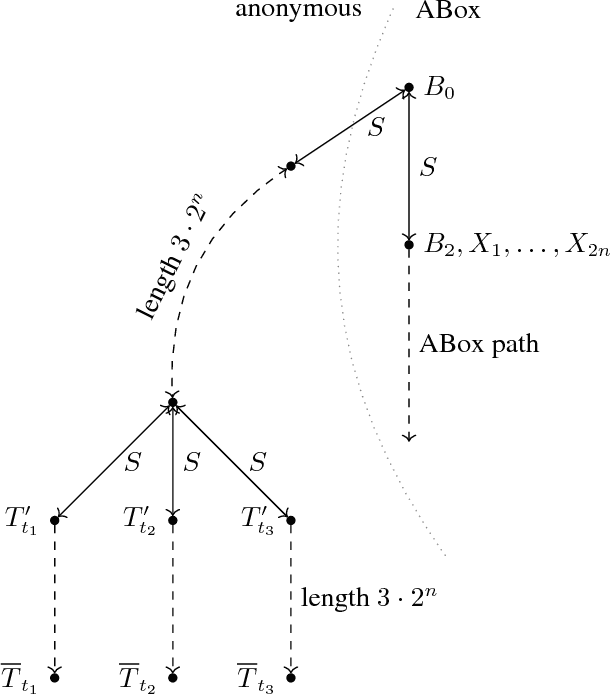
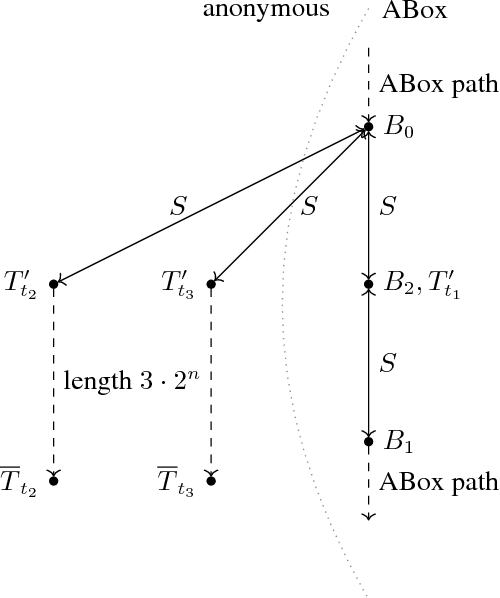
We investigate the decidability and computational complexity of conservative extensions and the related notions of inseparability and entailment in Horn description logics (DLs) with inverse roles. We consider both query conservative extensions, defined by requiring that the answers to all conjunctive queries are left unchanged, and deductive conservative extensions, which require that the entailed concept inclusions, role inclusions, and functionality assertions do not change. Upper bounds for query conservative extensions are particularly challenging because characterizations in terms of unbounded homomorphisms between universal models, which are the foundation of the standard approach to establishing decidability, fail in the presence of inverse roles. We resort to a characterization that carefully mixes unbounded and bounded homomorphisms and enables a decision procedure that combines tree automata and a mosaic technique. Our main results are that query conservative extensions are 2ExpTime-complete in all DLs between ELI and Horn-ALCHIF and between Horn-ALC and Horn-ALCHIF, and that deductive conservative extensions are 2ExpTime-complete in all DLs between ELI and ELHIF_\bot. The same results hold for inseparability and entailment.
Trustworthy AI Inference Systems: An Industry Research View
Aug 10, 2020In this work, we provide an industry research view for approaching the design, deployment, and operation of trustworthy Artificial Intelligence (AI) inference systems. Such systems provide customers with timely, informed, and customized inferences to aid their decision, while at the same time utilizing appropriate security protection mechanisms for AI models. Additionally, such systems should also use Privacy-Enhancing Technologies (PETs) to protect customers' data at any time. To approach the subject, we start by introducing trends in AI inference systems. We continue by elaborating on the relationship between Intellectual Property (IP) and private data protection in such systems. Regarding the protection mechanisms, we survey the security and privacy building blocks instrumental in designing, building, deploying, and operating private AI inference systems. For example, we highlight opportunities and challenges in AI systems using trusted execution environments combined with more recent advances in cryptographic techniques to protect data in use. Finally, we outline areas of further development that require the global collective attention of industry, academia, and government researchers to sustain the operation of trustworthy AI inference systems.
CryptoSPN: Privacy-preserving Sum-Product Network Inference
Feb 03, 2020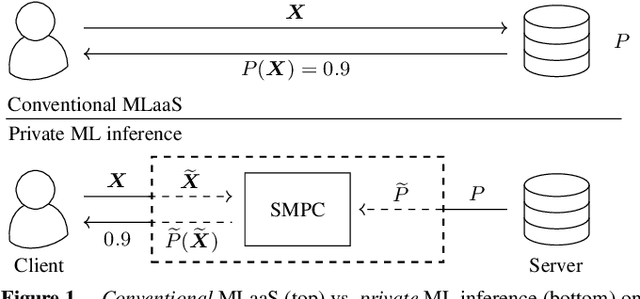
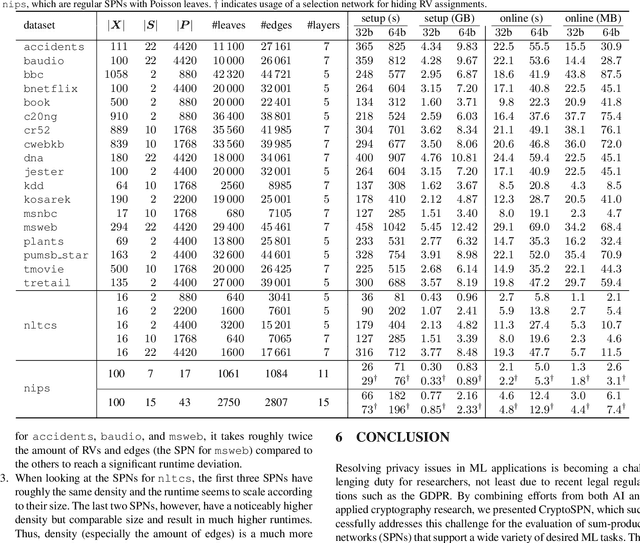
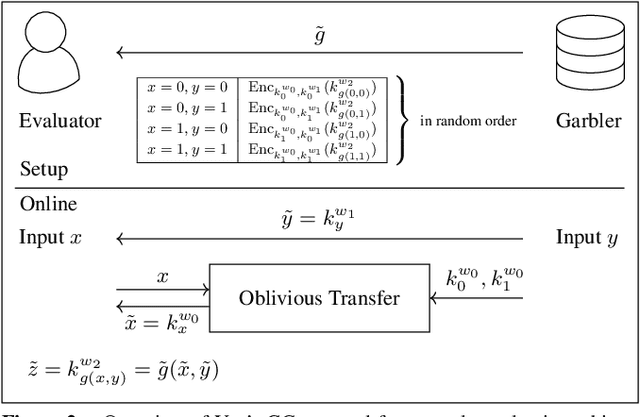
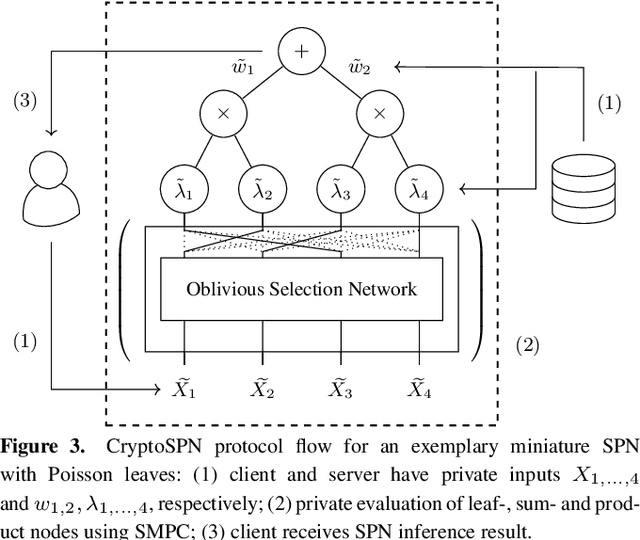
AI algorithms, and machine learning (ML) techniques in particular, are increasingly important to individuals' lives, but have caused a range of privacy concerns addressed by, e.g., the European GDPR. Using cryptographic techniques, it is possible to perform inference tasks remotely on sensitive client data in a privacy-preserving way: the server learns nothing about the input data and the model predictions, while the client learns nothing about the ML model (which is often considered intellectual property and might contain traces of sensitive data). While such privacy-preserving solutions are relatively efficient, they are mostly targeted at neural networks, can degrade the predictive accuracy, and usually reveal the network's topology. Furthermore, existing solutions are not readily accessible to ML experts, as prototype implementations are not well-integrated into ML frameworks and require extensive cryptographic knowledge. In this paper, we present CryptoSPN, a framework for privacy-preserving inference of sum-product networks (SPNs). SPNs are a tractable probabilistic graphical model that allows a range of exact inference queries in linear time. Specifically, we show how to efficiently perform SPN inference via secure multi-party computation (SMPC) without accuracy degradation while hiding sensitive client and training information with provable security guarantees. Next to foundations, CryptoSPN encompasses tools to easily transform existing SPNs into privacy-preserving executables. Our empirical results demonstrate that CryptoSPN achieves highly efficient and accurate inference in the order of seconds for medium-sized SPNs.