 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Rational Networks
Feb 18, 2021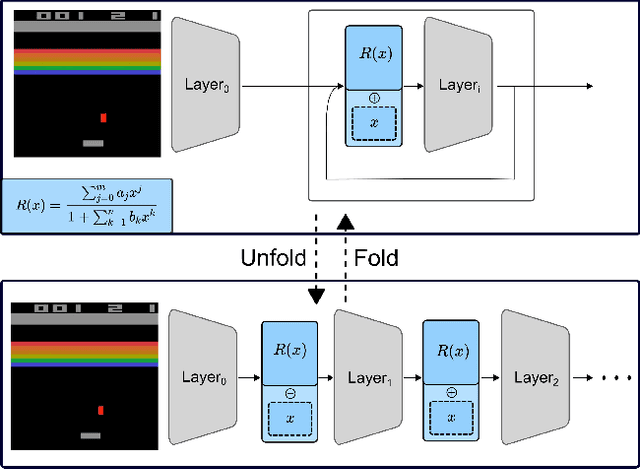
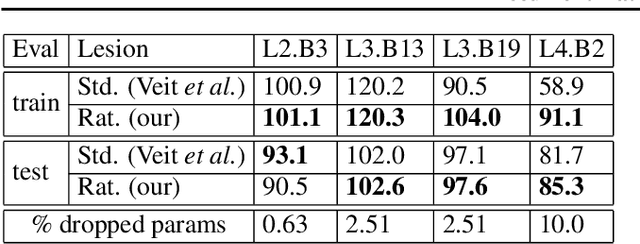
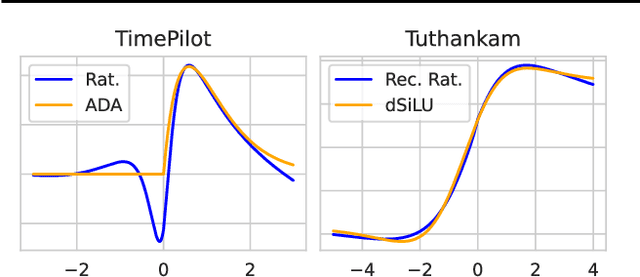
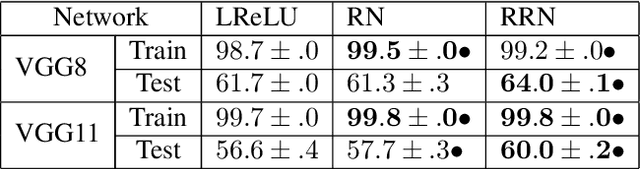
Latest insights from biology show that intelligence does not only emerge from the connections between the neurons, but that individual neurons shoulder more computational responsibility. Current Neural Network architecture design and search are biased on fixed activation functions. Using more advanced learnable activation functions provide Neural Networks with higher learning capacity. However, general guidance for building such networks is still missing. In this work, we first explain why rationals offer an optimal choice for activation functions. We then show that they are closed under residual connections, and inspired by recurrence for residual networks we derive a self-regularized version of Rationals: Recurrent Rationals. We demonstrate that (Recurrent) Rational Networks lead to high performance improvements on Image Classification and Deep Reinforcement Learning.
Einsum Networks: Fast and Scalable Learning of Tractable Probabilistic Circuits
Apr 13, 2020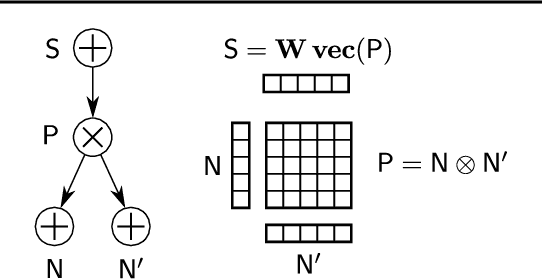

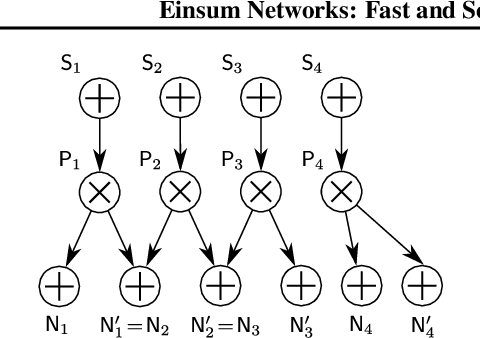
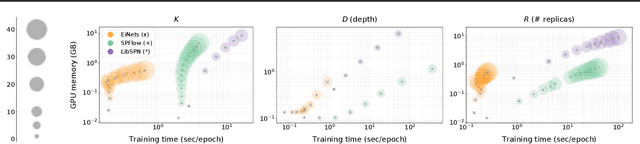
Probabilistic circuits (PCs) are a promising avenue for probabilistic modeling, as they permit a wide range of exact and efficient inference routines. Recent ``deep-learning-style'' implementations of PCs strive for a better scalability, but are still difficult to train on real-world data, due to their sparsely connected computational graphs. In this paper, we propose Einsum Networks (EiNets), a novel implementation design for PCs, improving prior art in several regards. At their core, EiNets combine a large number of arithmetic operations in a single monolithic einsum-operation, leading to speedups and memory savings of up to two orders of magnitude, in comparison to previous implementations. As an algorithmic contribution, we show that the implementation of Expectation-Maximization (EM) can be simplified for PCs, by leveraging automatic differentiation. Furthermore, we demonstrate that EiNets scale well to datasets which were previously out of reach, such as SVHN and CelebA, and that they can be used as faithful generative image models.
CryptoSPN: Privacy-preserving Sum-Product Network Inference
Feb 03, 2020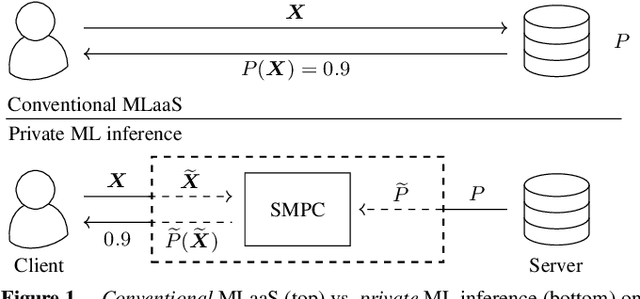
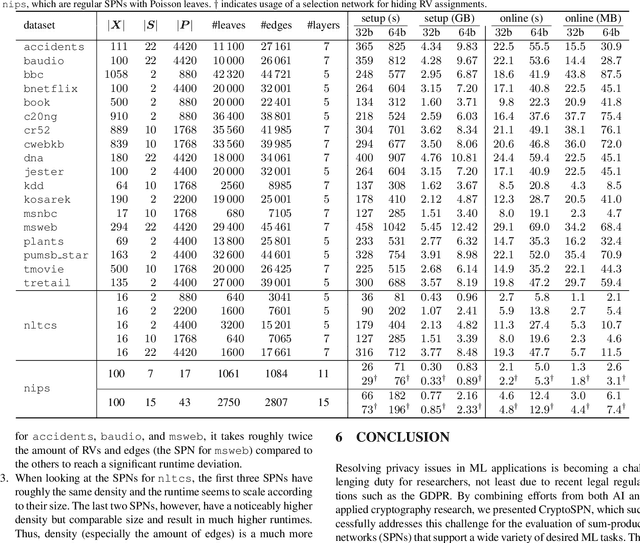
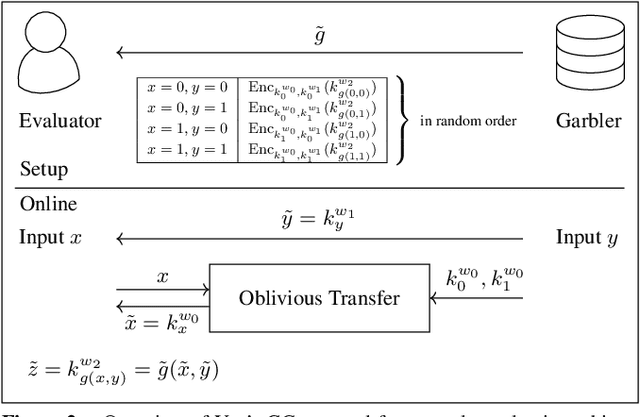
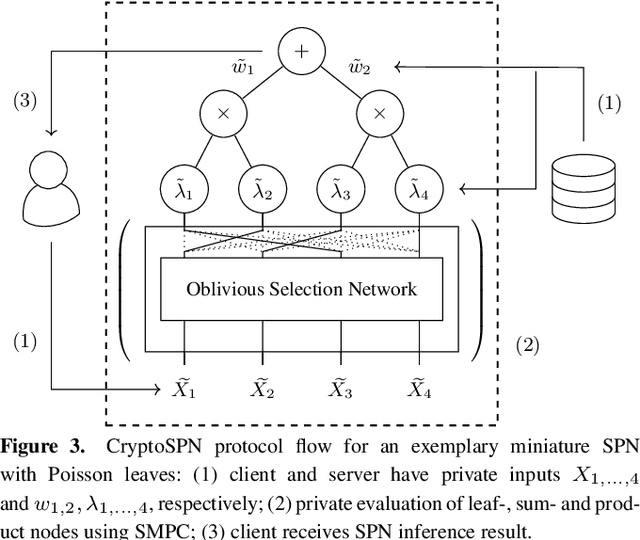
AI algorithms, and machine learning (ML) techniques in particular, are increasingly important to individuals' lives, but have caused a range of privacy concerns addressed by, e.g., the European GDPR. Using cryptographic techniques, it is possible to perform inference tasks remotely on sensitive client data in a privacy-preserving way: the server learns nothing about the input data and the model predictions, while the client learns nothing about the ML model (which is often considered intellectual property and might contain traces of sensitive data). While such privacy-preserving solutions are relatively efficient, they are mostly targeted at neural networks, can degrade the predictive accuracy, and usually reveal the network's topology. Furthermore, existing solutions are not readily accessible to ML experts, as prototype implementations are not well-integrated into ML frameworks and require extensive cryptographic knowledge. In this paper, we present CryptoSPN, a framework for privacy-preserving inference of sum-product networks (SPNs). SPNs are a tractable probabilistic graphical model that allows a range of exact inference queries in linear time. Specifically, we show how to efficiently perform SPN inference via secure multi-party computation (SMPC) without accuracy degradation while hiding sensitive client and training information with provable security guarantees. Next to foundations, CryptoSPN encompasses tools to easily transform existing SPNs into privacy-preserving executables. Our empirical results demonstrate that CryptoSPN achieves highly efficient and accurate inference in the order of seconds for medium-sized SPNs.
Random Sum-Product Forests with Residual Links
Aug 08, 2019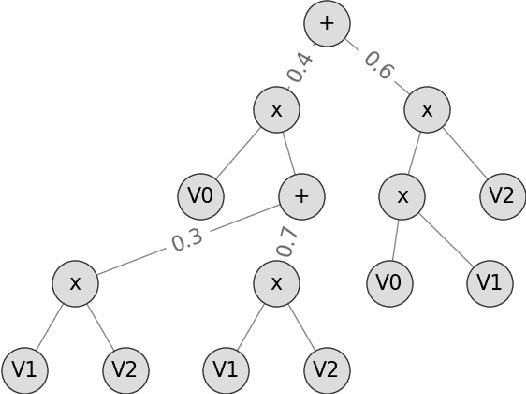
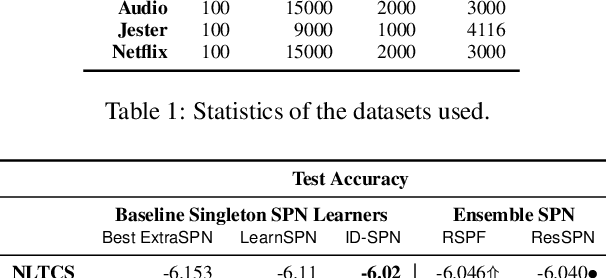

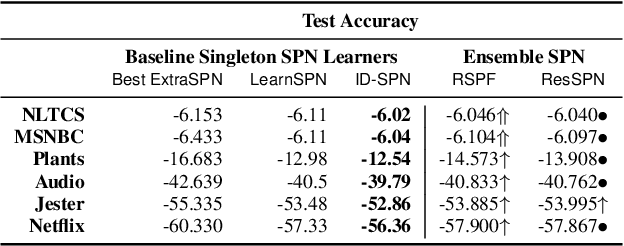
Tractable yet expressive density estimators are a key building block of probabilistic machine learning. While sum-product networks (SPNs) offer attractive inference capabilities, obtaining structures large enough to fit complex, high-dimensional data has proven challenging. In this paper, we present random sum-product forests (RSPFs), an ensemble approach for mixing multiple randomly generated SPNs. We also introduce residual links, which reference specialized substructures of other component SPNs in order to leverage the context-specific knowledge encoded within them. Our empirical evidence demonstrates that RSPFs provide better performance than their individual components. Adding residual links improves the models further, allowing the resulting ResSPNs to be competitive with commonly used structure learning methods.
Padé Activation Units: End-to-end Learning of Flexible Activation Functions in Deep Networks
Jul 15, 2019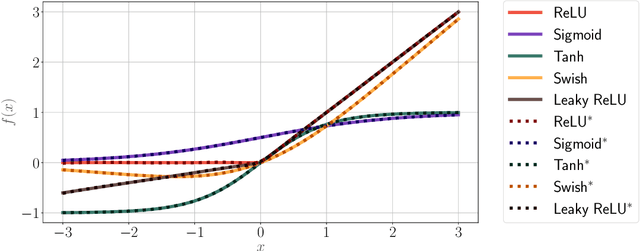
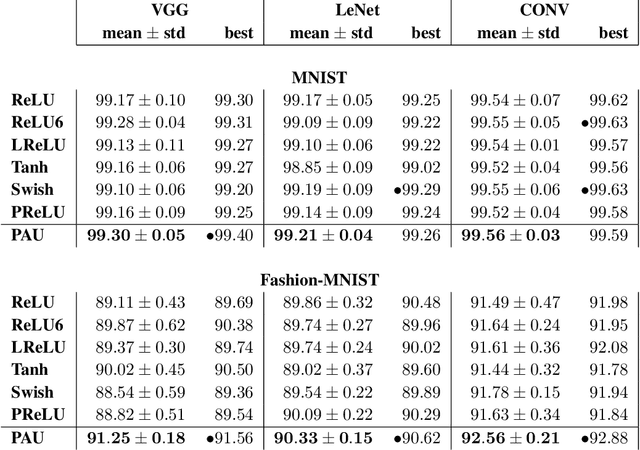

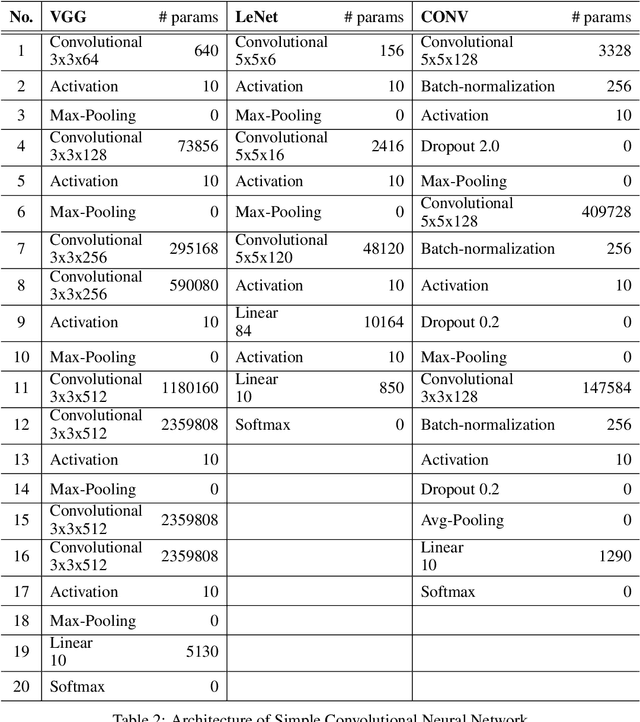
The performance of deep network learning strongly depends on the choice of the non-linear activation function associated with each neuron. However, deciding on the best activation is non-trivial and the choice depends on the architecture, hyper-parameters, and even on the dataset. Typically these activations are fixed by hand before training. Here, we demonstrate how to eliminate the reliance on first picking fixed activation functions by using flexible parametric rational functions instead. The resulting Pad\'e Activation Units (PAUs) can both approximate common activation functions and also learn new ones while providing compact representations. Our empirical evidence shows that end-to-end learning deep networks with PAUs can increase the predictive performance and reduce the training time of common deep architectures. Moreover, PAUs pave the way to approximations with provable robustness. The source code can be found at https://github.com/ml-research/pau
Conditional Sum-Product Networks: Imposing Structure on Deep Probabilistic Architectures
May 21, 2019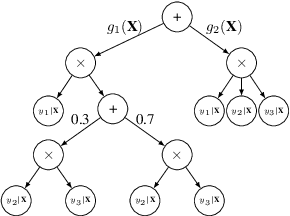
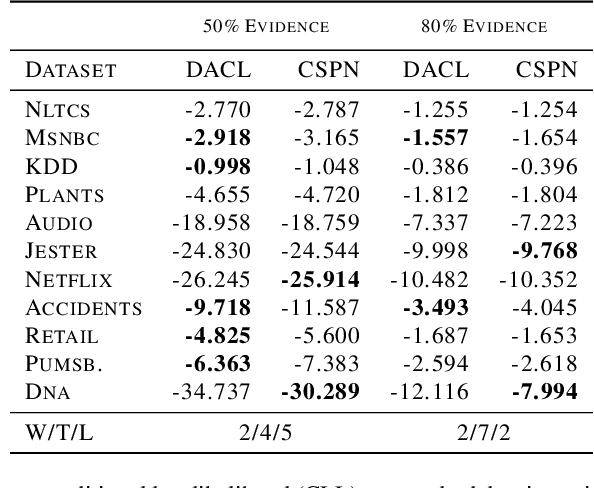
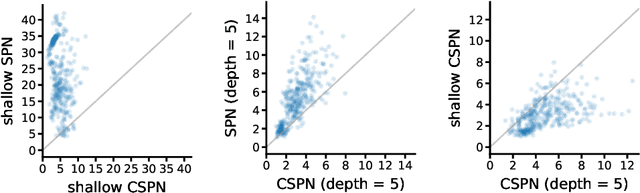

Bayesian networks are a central tool in machine learning and artificial intelligence, and make use of conditional independencies to impose structure on joint distributions. However, they are generally not as expressive as deep learning models and inference is hard and slow. In contrast, deep probabilistic models such as sum-product networks (SPNs) capture joint distributions in a tractable fashion, but use little interpretable structure. Here, we extend the notion of SPNs towards conditional distributions, which combine simple conditional models into high-dimensional ones. As shown in our experiments, the resulting conditional SPNs can be naturally used to impose structure on deep probabilistic models, allow for mixed data types, while maintaining fast and efficient inference.
Perils of Zero-Interaction Security in the Internet of Things
Jan 22, 2019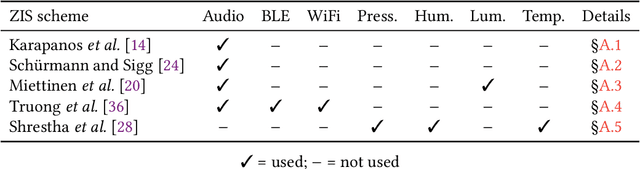
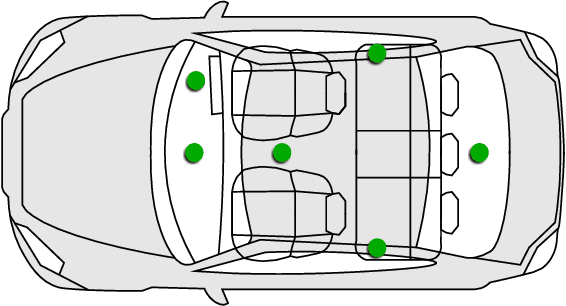
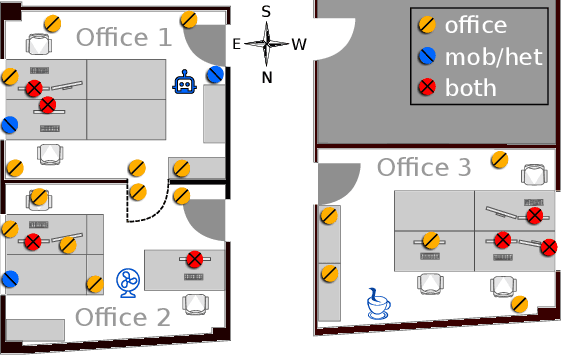

The Internet of Things (IoT) demands authentication systems which can provide both security and usability. Recent research utilizes the rich sensing capabilities of smart devices to build security schemes operating without human interaction, such as zero-interaction pairing (ZIP) and zero-interaction authentication (ZIA). Prior work proposed a number of ZIP and ZIA schemes and reported promising results. However, those schemes were often evaluated under conditions which do not reflect realistic IoT scenarios. In addition, drawing any comparison among the existing schemes is impossible due to the lack of a common public dataset and unavailability of scheme implementations. In this paper, we address these challenges by conducting the first large-scale comparative study of ZIP and ZIA schemes, carried out under realistic conditions. We collect and release the most comprehensive dataset in the domain to date, containing over 4250 hours of audio recordings and 1 billion sensor readings from three different scenarios, and evaluate five state-of-the-art schemes based on these data. Our study reveals that the effectiveness of the existing proposals is highly dependent on the scenario they are used in. In particular, we show that these schemes are subject to error rates between 0.6% and 52.8%.
SPFlow: An Easy and Extensible Library for Deep Probabilistic Learning using Sum-Product Networks
Jan 11, 2019
We introduce SPFlow, an open-source Python library providing a simple interface to inference, learning and manipulation routines for deep and tractable probabilistic models called Sum-Product Networks (SPNs). The library allows one to quickly create SPNs both from data and through a domain specific language (DSL). It efficiently implements several probabilistic inference routines like computing marginals, conditionals and (approximate) most probable explanations (MPEs) along with sampling as well as utilities for serializing, plotting and structure statistics on an SPN. Moreover, many of the algorithms proposed in the literature to learn the structure and parameters of SPNs are readily available in SPFlow. Furthermore, SPFlow is extremely extensible and customizable, allowing users to promptly distill new inference and learning routines by injecting custom code into a lightweight functional-oriented API framework. This is achieved in SPFlow by keeping an internal Python representation of the graph structure that also enables practical compilation of an SPN into a TensorFlow graph, C, CUDA or FPGA custom code, significantly speeding-up computations.
Model-based Approximate Query Processing
Nov 15, 2018



Interactive visualizations are arguably the most important tool to explore, understand and convey facts about data. In the past years, the database community has been working on different techniques for Approximate Query Processing (AQP) that aim to deliver an approximate query result given a fixed time bound to support interactive visualizations better. However, classical AQP approaches suffer from various problems that limit the applicability to support the ad-hoc exploration of a new data set: (1) Classical AQP approaches that perform online sampling can support ad-hoc exploration queries but yield low quality if executed over rare subpopulations. (2) Classical AQP approaches that rely on offline sampling can use some form of biased sampling to mitigate these problems but require a priori knowledge of the workload, which is often not realistic if users want to explore a new database. In this paper, we present a new approach to AQP called Model-based AQP that leverages generative models learned over the complete database to answer SQL queries at interactive speeds. Different from classical AQP approaches, generative models allow us to compute responses to ad-hoc queries and deliver high-quality estimates also over rare subpopulations at the same time. In our experiments with real and synthetic data sets, we show that Model-based AQP can in many scenarios return more accurate results in a shorter runtime. Furthermore, we think that our techniques of using generative models presented in this paper can not only be used for AQP in databases but also has applications for other database problems including Query Optimization as well as Data Cleaning.
Automatic Bayesian Density Analysis
Oct 03, 2018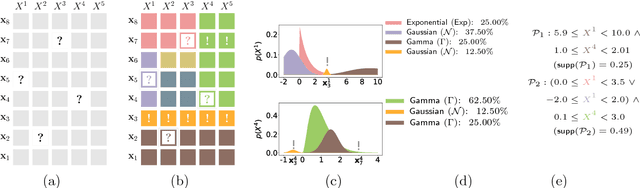
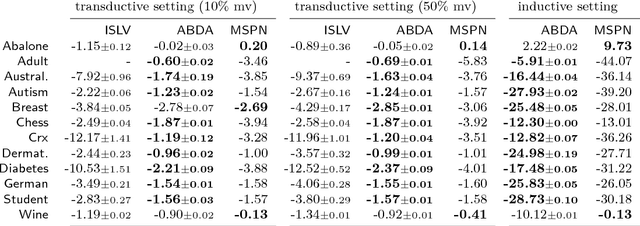
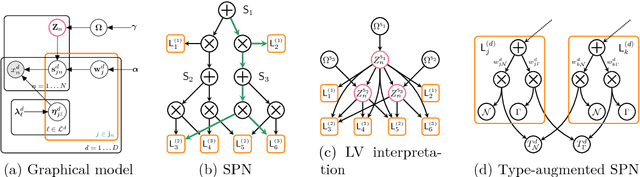

Making sense of a dataset in an automatic and unsupervised fashion is a challenging problem in statistics and AI. Classical approaches for density estimation are usually not flexible enough to deal with the uncertainty inherent to real-world data: they are often restricted to fixed latent interaction models and homogeneous likelihoods; they are sensitive to missing, corrupt and anomalous data; moreover, their expressiveness generally comes at the price of intractable inference. As a result, supervision from statisticians is usually needed to find the right model for the data. However, as domain experts do not necessarily have to be experts in statistics, we propose Automatic Bayesian Density Analysis (ABDA) to make density estimation accessible at large. ABDA automates the selection of adequate likelihood models from arbitrarily rich dictionaries while modeling their interactions via a deep latent structure adaptively learned from data as a sum-product network. ABDA casts uncertainty estimation at these local and global levels into a joint Bayesian inference problem, providing robust and yet tractable inference. Extensive empirical evidence shows that ABDA is a suitable tool for automatic exploratory analysis of heterogeneous tabular data, allowing for missing value estimation, statistical data type and likelihood discovery, anomaly detection and dependency structure mining, on top of providing accurate density estimation.