 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEVA-Compass: A Continual Learning EValuation Assessment Compass to Promote Research Transparency and Comparability
Oct 07, 2021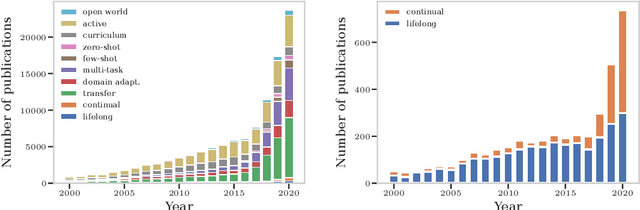
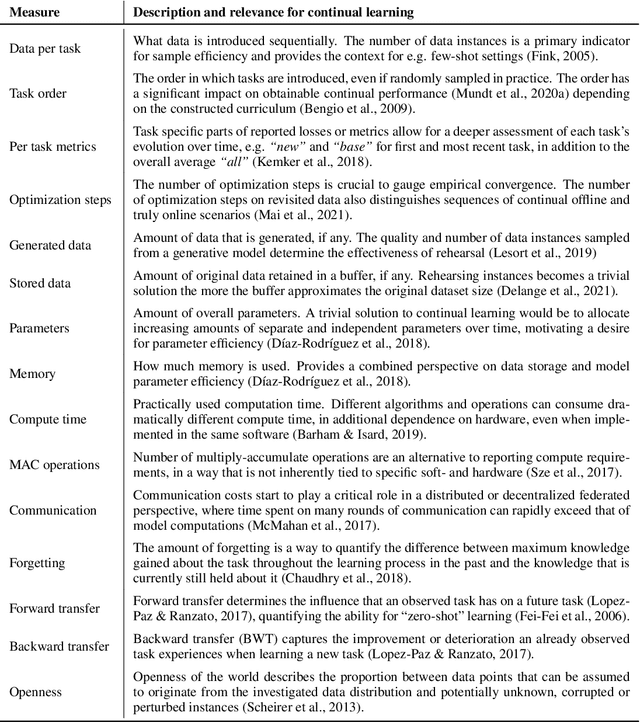
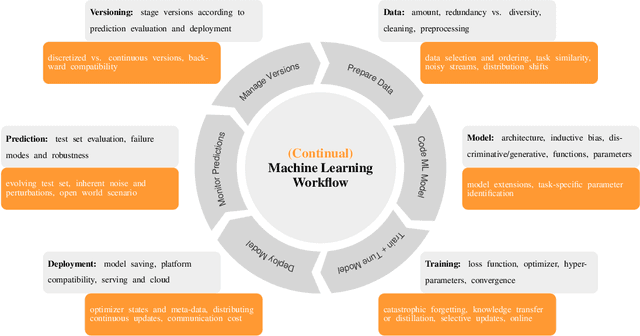

What is the state of the art in continual machine learning? Although a natural question for predominant static benchmarks, the notion to train systems in a lifelong manner entails a plethora of additional challenges with respect to set-up and evaluation. The latter have recently sparked a growing amount of critiques on prominent algorithm-centric perspectives and evaluation protocols being too narrow, resulting in several attempts at constructing guidelines in favor of specific desiderata or arguing against the validity of prevalent assumptions. In this work, we depart from this mindset and argue that the goal of a precise formulation of desiderata is an ill-posed one, as diverse applications may always warrant distinct scenarios. Instead, we introduce the Continual Learning EValuation Assessment Compass, CLEVA-Compass for short. The compass provides the visual means to both identify how approaches are practically reported and how works can simultaneously be contextualized in the broader literature landscape. In addition to promoting compact specification in the spirit of recent replication trends, the CLEVA-Compass thus provides an intuitive chart to understand the priorities of individual systems, where they resemble each other, and what elements are missing towards a fair comparison.
DAFNe: A One-Stage Anchor-Free Deep Model for Oriented Object Detection
Sep 22, 2021

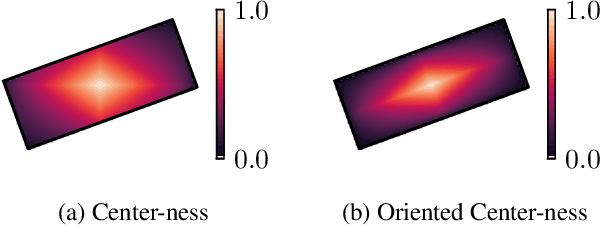

Object detection is a fundamental task in computer vision. While approaches for axis-aligned bounding box detection have made substantial progress in recent years, they perform poorly on oriented objects which are common in several real-world scenarios such as aerial view imagery and security camera footage. In these cases, a large part of a predicted bounding box will, undesirably, cover non-object related areas. Therefore, oriented object detection has emerged with the aim of generalizing object detection to arbitrary orientations. This enables a tighter fit to oriented objects, leading to a better separation of bounding boxes especially in case of dense object distributions. The vast majority of the work in this area has focused on complex two-stage anchor-based approaches. Anchors act as priors on the bounding box shape and require attentive hyper-parameter fine-tuning on a per-dataset basis, increased model size, and come with computational overhead. In this work, we present DAFNe: A Dense one-stage Anchor-Free deep Network for oriented object detection. As a one-stage model, DAFNe performs predictions on a dense grid over the input image, being architecturally simpler and faster, as well as easier to optimize than its two-stage counterparts. Furthermore, as an anchor-free model, DAFNe reduces the prediction complexity by refraining from employing bounding box anchors. Moreover, we introduce an orientation-aware generalization of the center-ness function for arbitrarily oriented bounding boxes to down-weight low-quality predictions and a center-to-corner bounding box prediction strategy that improves object localization performance. DAFNe improves the prediction accuracy over the previous best one-stage anchor-free model results on DOTA 1.0 by 4.65% mAP, setting the new state-of-the-art results by achieving 76.95% mAP.
Einsum Networks: Fast and Scalable Learning of Tractable Probabilistic Circuits
Apr 13, 2020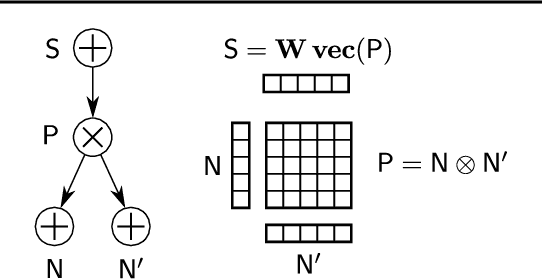

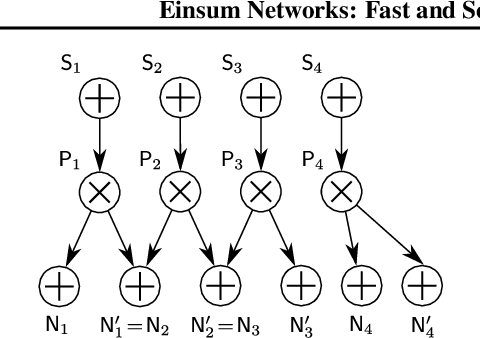
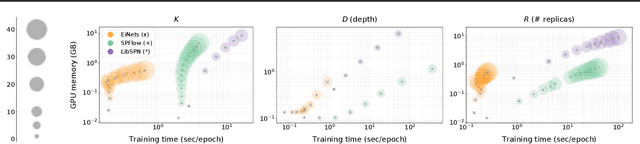
Probabilistic circuits (PCs) are a promising avenue for probabilistic modeling, as they permit a wide range of exact and efficient inference routines. Recent ``deep-learning-style'' implementations of PCs strive for a better scalability, but are still difficult to train on real-world data, due to their sparsely connected computational graphs. In this paper, we propose Einsum Networks (EiNets), a novel implementation design for PCs, improving prior art in several regards. At their core, EiNets combine a large number of arithmetic operations in a single monolithic einsum-operation, leading to speedups and memory savings of up to two orders of magnitude, in comparison to previous implementations. As an algorithmic contribution, we show that the implementation of Expectation-Maximization (EM) can be simplified for PCs, by leveraging automatic differentiation. Furthermore, we demonstrate that EiNets scale well to datasets which were previously out of reach, such as SVHN and CelebA, and that they can be used as faithful generative image models.