 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Turn Your Knowledge Graph Embeddings into Generative Models via Probabilistic Circuits
May 25, 2023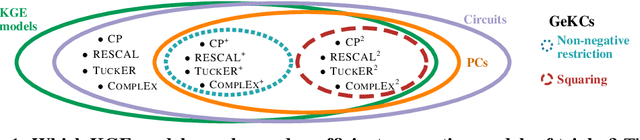
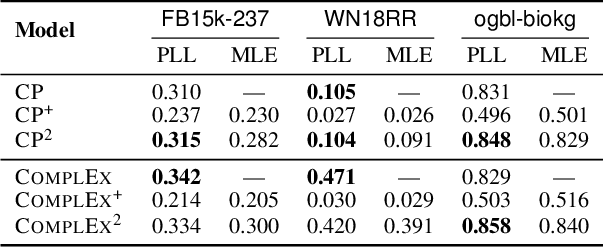
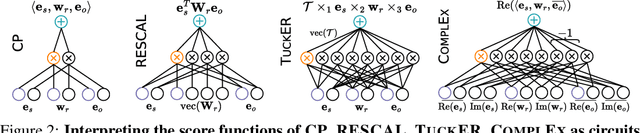
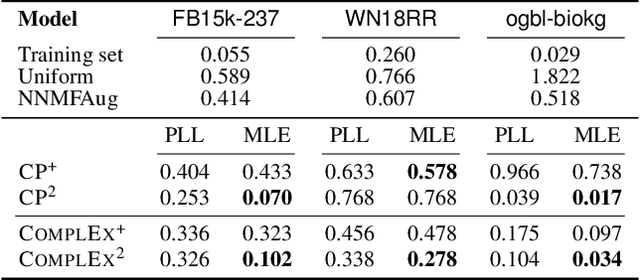
Some of the most successful knowledge graph embedding (KGE) models for link prediction -- CP, RESCAL, TuckER, ComplEx -- can be interpreted as energy-based models. Under this perspective they are not amenable for exact maximum-likelihood estimation (MLE), sampling and struggle to integrate logical constraints. This work re-interprets the score functions of these KGEs as circuits -- constrained computational graphs allowing efficient marginalisation. Then, we design two recipes to obtain efficient generative circuit models by either restricting their activations to be non-negative or squaring their outputs. Our interpretation comes with little or no loss of performance for link prediction, while the circuits framework unlocks exact learning by MLE, efficient sampling of new triples, and guarantee that logical constraints are satisfied by design. Furthermore, our models scale more gracefully than the original KGEs on graphs with millions of entities.
SPFlow: An Easy and Extensible Library for Deep Probabilistic Learning using Sum-Product Networks
Jan 11, 2019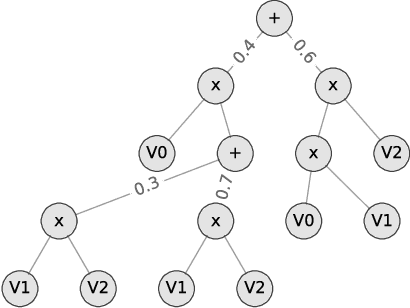
We introduce SPFlow, an open-source Python library providing a simple interface to inference, learning and manipulation routines for deep and tractable probabilistic models called Sum-Product Networks (SPNs). The library allows one to quickly create SPNs both from data and through a domain specific language (DSL). It efficiently implements several probabilistic inference routines like computing marginals, conditionals and (approximate) most probable explanations (MPEs) along with sampling as well as utilities for serializing, plotting and structure statistics on an SPN. Moreover, many of the algorithms proposed in the literature to learn the structure and parameters of SPNs are readily available in SPFlow. Furthermore, SPFlow is extremely extensible and customizable, allowing users to promptly distill new inference and learning routines by injecting custom code into a lightweight functional-oriented API framework. This is achieved in SPFlow by keeping an internal Python representation of the graph structure that also enables practical compilation of an SPN into a TensorFlow graph, C, CUDA or FPGA custom code, significantly speeding-up computations.
Visualizing and Understanding Sum-Product Networks
Aug 24, 2018

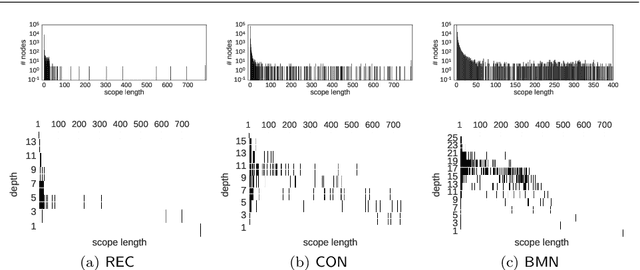
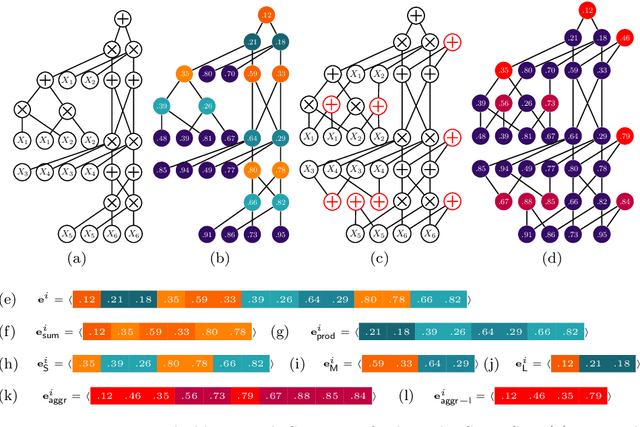
Sum-Product Networks (SPNs) are recently introduced deep tractable probabilistic models by which several kinds of inference queries can be answered exactly and in a tractable time. Up to now, they have been largely used as black box density estimators, assessed only by comparing their likelihood scores only. In this paper we explore and exploit the inner representations learned by SPNs. We do this with a threefold aim: first we want to get a better understanding of the inner workings of SPNs; secondly, we seek additional ways to evaluate one SPN model and compare it against other probabilistic models, providing diagnostic tools to practitioners; lastly, we want to empirically evaluate how good and meaningful the extracted representations are, as in a classic Representation Learning framework. In order to do so we revise their interpretation as deep neural networks and we propose to exploit several visualization techniques on their node activations and network outputs under different types of inference queries. To investigate these models as feature extractors, we plug some SPNs, learned in a greedy unsupervised fashion on image datasets, in supervised classification learning tasks. We extract several embedding types from node activations by filtering nodes by their type, by their associated feature abstraction level and by their scope. In a thorough empirical comparison we prove them to be competitive against those generated from popular feature extractors as Restricted Boltzmann Machines. Finally, we investigate embeddings generated from random probabilistic marginal queries as means to compare other tractable probabilistic models on a common ground, extending our experiments to Mixtures of Trees.
Sum-Product Networks for Hybrid Domains
Nov 06, 2017

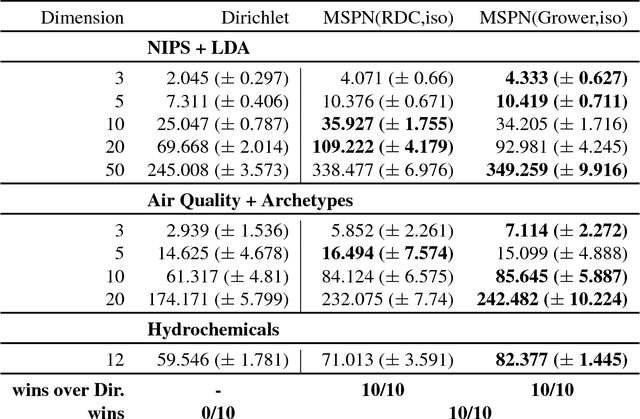
While all kinds of mixed data -from personal data, over panel and scientific data, to public and commercial data- are collected and stored, building probabilistic graphical models for these hybrid domains becomes more difficult. Users spend significant amounts of time in identifying the parametric form of the random variables (Gaussian, Poisson, Logit, etc.) involved and learning the mixed models. To make this difficult task easier, we propose the first trainable probabilistic deep architecture for hybrid domains that features tractable queries. It is based on Sum-Product Networks (SPNs) with piecewise polynomial leave distributions together with novel nonparametric decomposition and conditioning steps using the Hirschfeld-Gebelein-R\'enyi Maximum Correlation Coefficient. This relieves the user from deciding a-priori the parametric form of the random variables but is still expressive enough to effectively approximate any continuous distribution and permits efficient learning and inference. Our empirical evidence shows that the architecture, called Mixed SPNs, can indeed capture complex distributions across a wide range of hybrid domains.
Towards Representation Learning with Tractable Probabilistic Models
Aug 08, 2016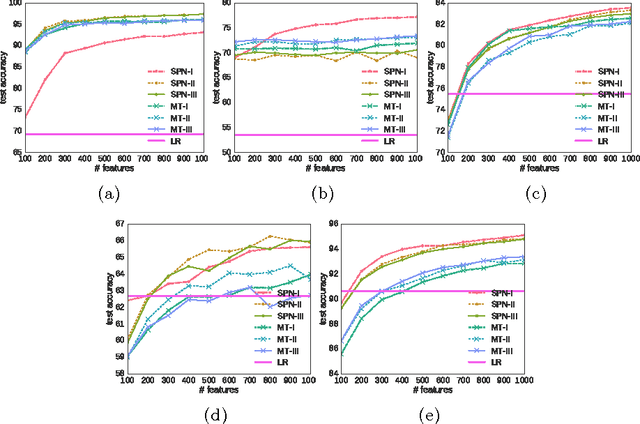
Probabilistic models learned as density estimators can be exploited in representation learning beside being toolboxes used to answer inference queries only. However, how to extract useful representations highly depends on the particular model involved. We argue that tractable inference, i.e. inference that can be computed in polynomial time, can enable general schemes to extract features from black box models. We plan to investigate how Tractable Probabilistic Models (TPMs) can be exploited to generate embeddings by random query evaluations. We devise two experimental designs to assess and compare different TPMs as feature extractors in an unsupervised representation learning framework. We show some experimental results on standard image datasets by applying such a method to Sum-Product Networks and Mixture of Trees as tractable models generating embeddings.
Ensemble Relational Learning based on Selective Propositionalization
Nov 15, 2013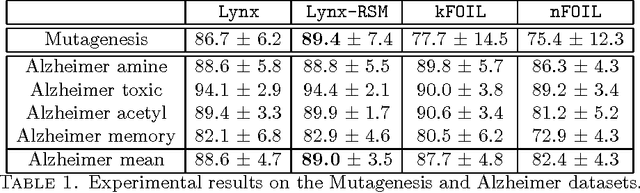
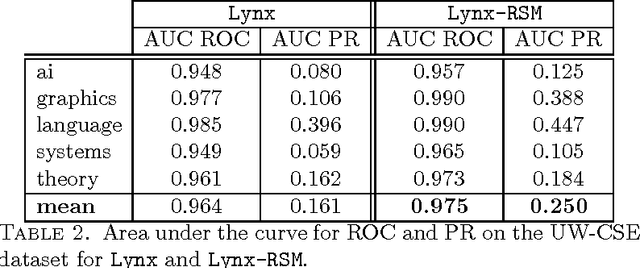

Dealing with structured data needs the use of expressive representation formalisms that, however, puts the problem to deal with the computational complexity of the machine learning process. Furthermore, real world domains require tools able to manage their typical uncertainty. Many statistical relational learning approaches try to deal with these problems by combining the construction of relevant relational features with a probabilistic tool. When the combination is static (static propositionalization), the constructed features are considered as boolean features and used offline as input to a statistical learner; while, when the combination is dynamic (dynamic propositionalization), the feature construction and probabilistic tool are combined into a single process. In this paper we propose a selective propositionalization method that search the optimal set of relational features to be used by a probabilistic learner in order to minimize a loss function. The new propositionalization approach has been combined with the random subspace ensemble method. Experiments on real-world datasets shows the validity of the proposed method.
Language-Constraint Reachability Learning in Probabilistic Graphs
May 24, 2012

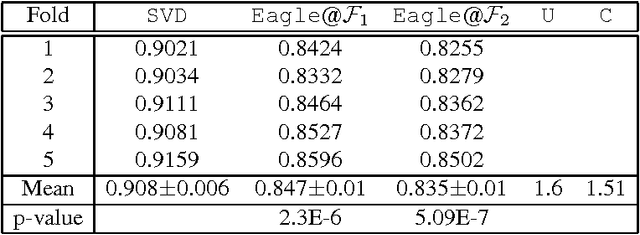
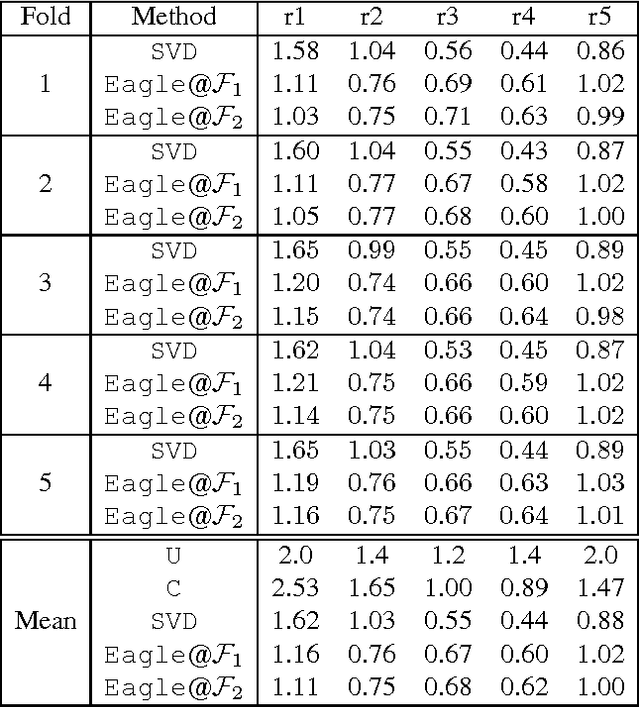
The probabilistic graphs framework models the uncertainty inherent in real-world domains by means of probabilistic edges whose value quantifies the likelihood of the edge existence or the strength of the link it represents. The goal of this paper is to provide a learning method to compute the most likely relationship between two nodes in a framework based on probabilistic graphs. In particular, given a probabilistic graph we adopted the language-constraint reachability method to compute the probability of possible interconnections that may exists between two nodes. Each of these connections may be viewed as feature, or a factor, between the two nodes and the corresponding probability as its weight. Each observed link is considered as a positive instance for its corresponding link label. Given the training set of observed links a L2-regularized Logistic Regression has been adopted to learn a model able to predict unobserved link labels. The experiments on a real world collaborative filtering problem proved that the proposed approach achieves better results than that obtained adopting classical methods.
GRASP and path-relinking for Coalition Structure Generation
Mar 09, 2011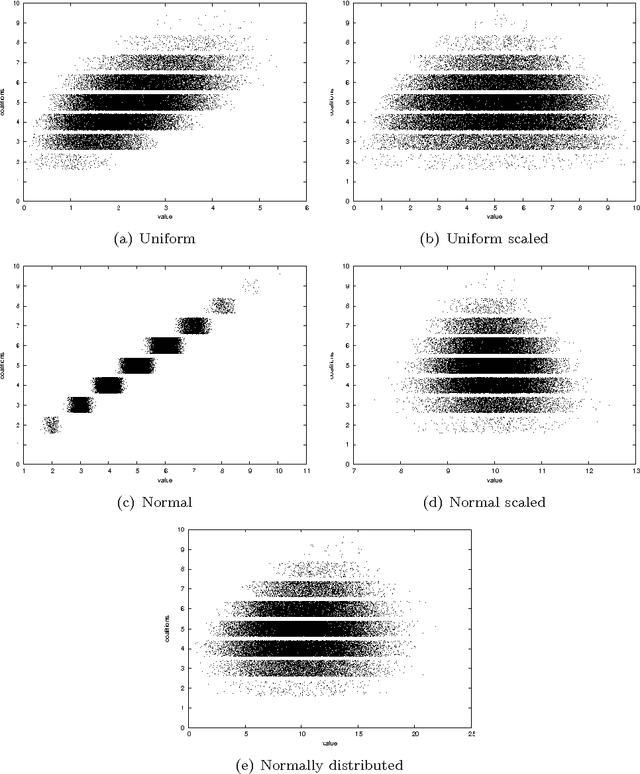
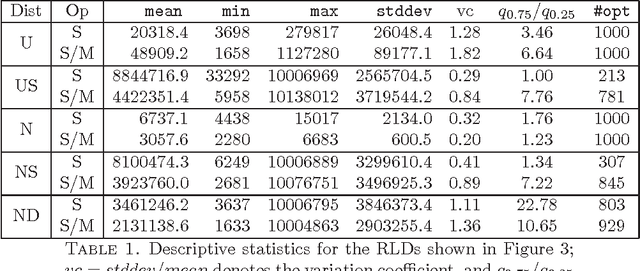
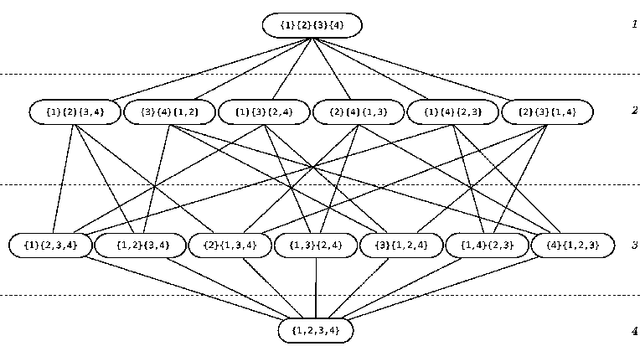

In Artificial Intelligence with Coalition Structure Generation (CSG) one refers to those cooperative complex problems that require to find an optimal partition, maximising a social welfare, of a set of entities involved in a system into exhaustive and disjoint coalitions. The solution of the CSG problem finds applications in many fields such as Machine Learning (covering machines, clustering), Data Mining (decision tree, discretization), Graph Theory, Natural Language Processing (aggregation), Semantic Web (service composition), and Bioinformatics. The problem of finding the optimal coalition structure is NP-complete. In this paper we present a greedy adaptive search procedure (GRASP) with path-relinking to efficiently search the space of coalition structures. Experiments and comparisons to other algorithms prove the validity of the proposed method in solving this hard combinatorial problem.
Feature Construction for Relational Sequence Learning
Jun 27, 2010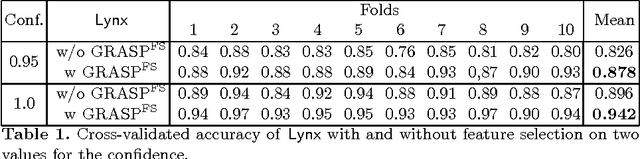

We tackle the problem of multi-class relational sequence learning using relevant patterns discovered from a set of labelled sequences. To deal with this problem, firstly each relational sequence is mapped into a feature vector using the result of a feature construction method. Since, the efficacy of sequence learning algorithms strongly depends on the features used to represent the sequences, the second step is to find an optimal subset of the constructed features leading to high classification accuracy. This feature selection task has been solved adopting a wrapper approach that uses a stochastic local search algorithm embedding a naive Bayes classifier. The performance of the proposed method applied to a real-world dataset shows an improvement when compared to other established methods, such as hidden Markov models, Fisher kernels and conditional random fields for relational sequences.
GRASP for the Coalition Structure Formation Problem
Apr 16, 2010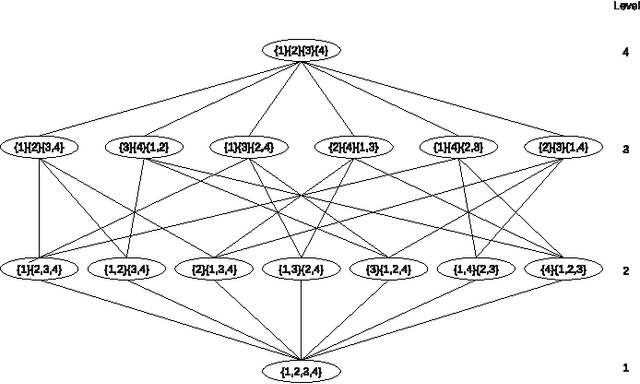
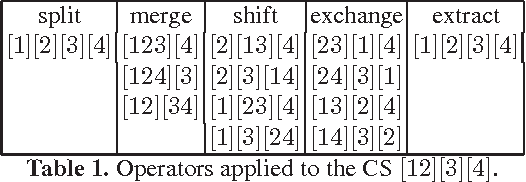
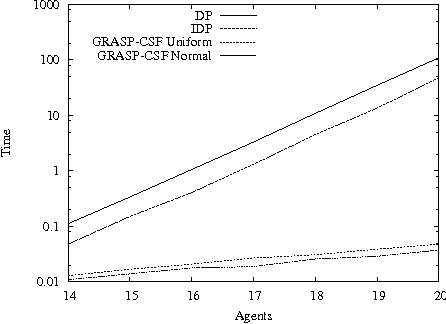

The coalition structure formation problem represents an active research area in multi-agent systems. A coalition structure is defined as a partition of the agents involved in a system into disjoint coalitions. The problem of finding the optimal coalition structure is NP-complete. In order to find the optimal solution in a combinatorial optimization problem it is theoretically possible to enumerate the solutions and evaluate each. But this approach is infeasible since the number of solutions often grows exponentially with the size of the problem. In this paper we present a greedy adaptive search procedure (GRASP) to efficiently search the space of coalition structures in order to find an optimal one. Experiments and comparisons to other algorithms prove the validity of the proposed method in solving this hard combinatorial problem.