 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Fast Differentially Private SGD via Just-in-Time Compilation and Vectorization
Oct 18, 2020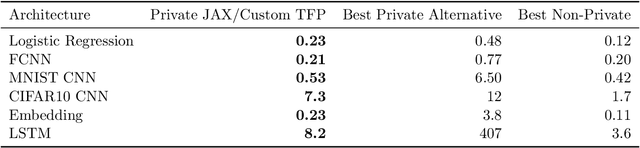
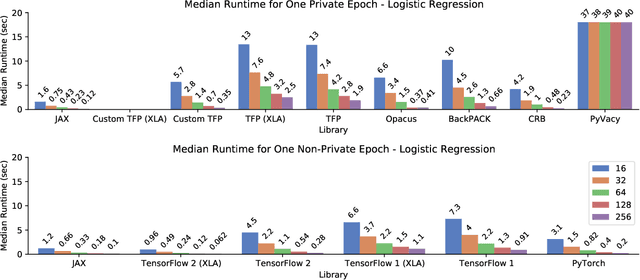
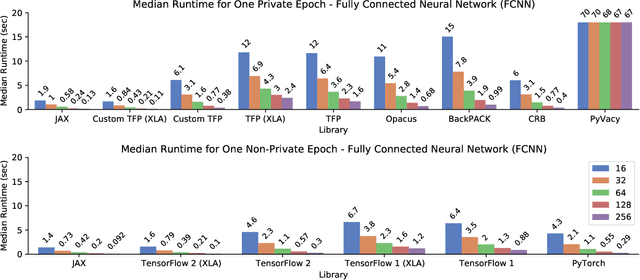
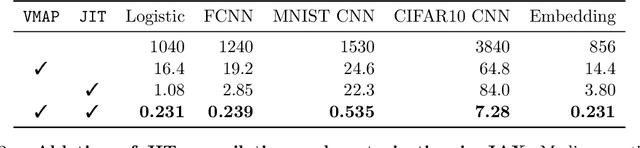
A common pain point in differentially private machine learning is the significant runtime overhead incurred when executing Differentially Private Stochastic Gradient Descent (DPSGD), which may be as large as two orders of magnitude. We thoroughly demonstrate that by exploiting powerful language primitives, including vectorization, just-in-time compilation, and static graph optimization, one can dramatically reduce these overheads, in many cases nearly matching the best non-private running times. These gains are realized in two frameworks: JAX and TensorFlow. JAX provides rich support for these primitives as core features of the language through the XLA compiler. We also rebuild core parts of TensorFlow Privacy, integrating features from TensorFlow 2 as well as XLA compilation, granting significant memory and runtime improvements over the current release version. These approaches allow us to achieve up to 50x speedups in comparison to the best alternatives. Our code is available at https://github.com/TheSalon/fast-dpsgd.
SPFlow: An Easy and Extensible Library for Deep Probabilistic Learning using Sum-Product Networks
Jan 11, 2019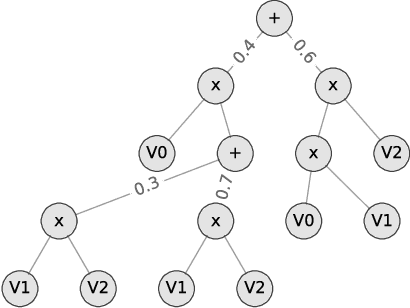
We introduce SPFlow, an open-source Python library providing a simple interface to inference, learning and manipulation routines for deep and tractable probabilistic models called Sum-Product Networks (SPNs). The library allows one to quickly create SPNs both from data and through a domain specific language (DSL). It efficiently implements several probabilistic inference routines like computing marginals, conditionals and (approximate) most probable explanations (MPEs) along with sampling as well as utilities for serializing, plotting and structure statistics on an SPN. Moreover, many of the algorithms proposed in the literature to learn the structure and parameters of SPNs are readily available in SPFlow. Furthermore, SPFlow is extremely extensible and customizable, allowing users to promptly distill new inference and learning routines by injecting custom code into a lightweight functional-oriented API framework. This is achieved in SPFlow by keeping an internal Python representation of the graph structure that also enables practical compilation of an SPN into a TensorFlow graph, C, CUDA or FPGA custom code, significantly speeding-up computations.