 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScionFL: Secure Quantized Aggregation for Federated Learning
Oct 13, 2022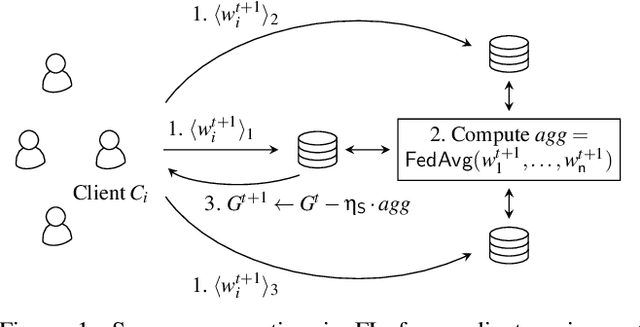
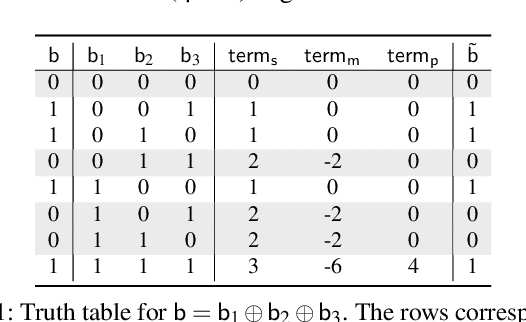

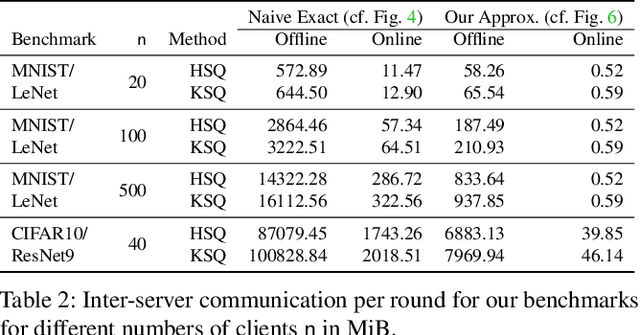
Privacy concerns in federated learning (FL) are commonly addressed with secure aggregation schemes that prevent a central party from observing plaintext client updates. However, most such schemes neglect orthogonal FL research that aims at reducing communication between clients and the aggregator and is instrumental in facilitating cross-device FL with thousands and even millions of (mobile) participants. In particular, quantization techniques can typically reduce client-server communication by a factor of 32x. In this paper, we unite both research directions by introducing an efficient secure aggregation framework based on outsourced multi-party computation (MPC) that supports any linear quantization scheme. Specifically, we design a novel approximate version of an MPC-based secure aggregation protocol with support for multiple stochastic quantization schemes, including ones that utilize the randomized Hadamard transform and Kashin's representation. In our empirical performance evaluation, we show that with no additional overhead for clients and moderate inter-server communication, we achieve similar training accuracy as insecure schemes for standard FL benchmarks. Beyond this, we present an efficient extension to our secure quantized aggregation framework that effectively defends against state-of-the-art untargeted poisoning attacks.
BaFFLe: Backdoor detection via Feedback-based Federated Learning
Nov 04, 2020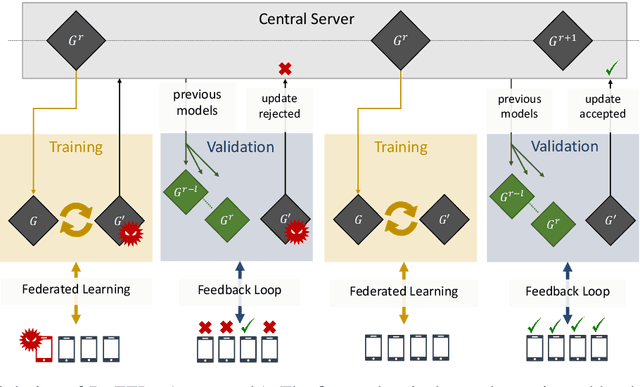
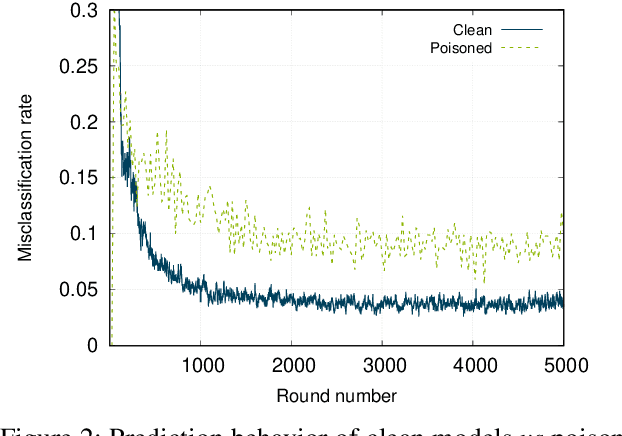
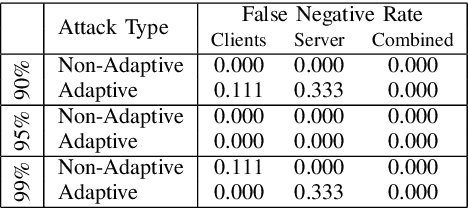
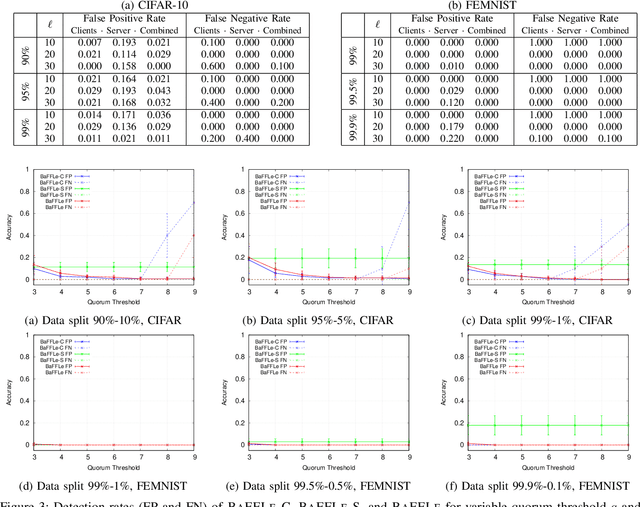
Recent studies have shown that federated learning (FL) is vulnerable to poisoning attacks which aim at injecting a backdoor into the global model. These attacks are effective, even when performed by a single client, and undetectable by most existing defensive techniques. In this paper, we propose a novel defense, dubbed BaFFLe---Backdoor detection via Feedback-based Federated Learning---to secure FL against backdoor attacks. The core idea behind BaFFLe is to leverage data of multiple clients not only for training but also for uncovering model poisoning. Namely, we exploit the availability of multiple, rich datasets at the various clients by incorporating a feedback loop into the FL process to integrate the views of those clients when deciding whether a given model update is genuine or not. We show that this powerful construct can achieve very high detection rates against state-of-the-art backdoor attacks, even when relying on straightforward methods to validate the model. Namely, we show by means of evaluation using the CIFAR-10 and FEMNIST datasets that, by combining the feedback loop with a method that suspects poisoning attempts by assessing the per-class classification performance of the updated model, BaFFLe reliably detects state-of-the-art semantic-backdoor attacks with a detection accuracy of 100% and a false-positive rate below 5%. Moreover, we show that our solution can detect an adaptive attack which is tuned to bypass the defense.